 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding Synthetic Real-World Degradations for Blind Video Super Resolution
May 04, 2023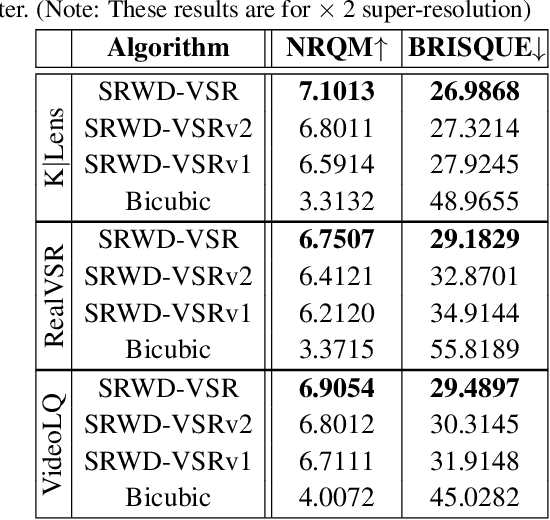
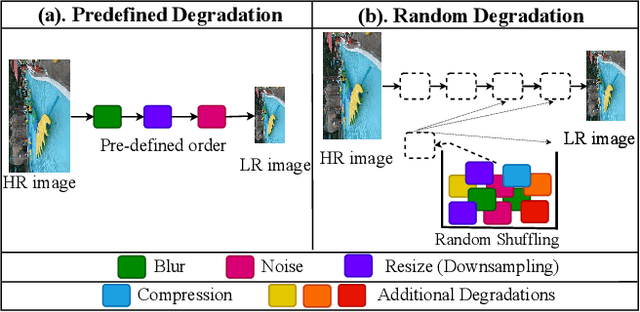
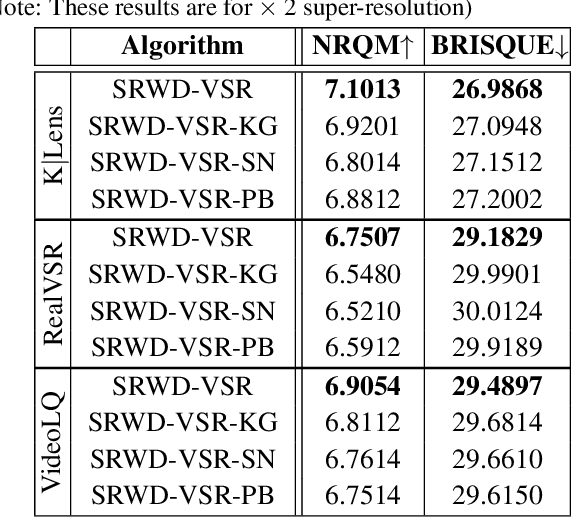
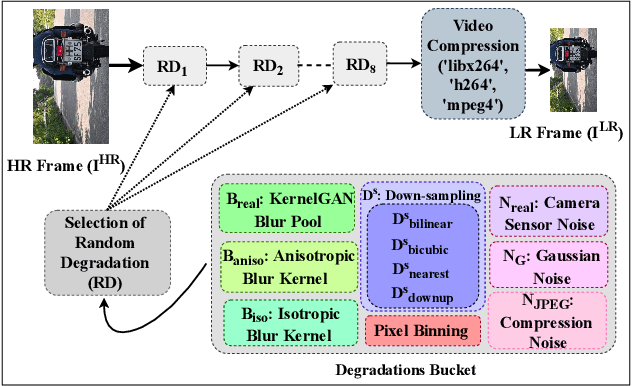
Video super-resolution (VSR) techniques, especially deep-learning-based algorithms, have drastically improved over the last few years and shown impressive performance on synthetic data. However, their performance on real-world video data suffers because of the complexity of real-world degradations and misaligned video frames. Since obtaining a synthetic dataset consisting of low-resolution (LR) and high-resolution (HR) frames are easier than obtaining real-world LR and HR images, in this paper, we propose synthesizing real-world degradations on synthetic training datasets. The proposed synthetic real-world degradations (SRWD) include a combination of the blur, noise, downsampling, pixel binning, and image and video compression artifacts. We then propose using a random shuffling-based strategy to simulate these degradations on the training datasets and train a single end-to-end deep neural network (DNN) on the proposed larger variation of realistic synthesized training data. Our quantitative and qualitative comparative analysis shows that the proposed training strategy using diverse realistic degradations improves the performance by 7.1 % in terms of NRQM compared to RealBasicVSR and by 3.34 % compared to BSRGAN on the VideoLQ dataset. We also introduce a new dataset that contains high-resolution real-world videos that can serve as a common ground for bench-marking.
Multi-Scale Features and Parallel Transformers Based Image Quality Assessment
Apr 20, 2022

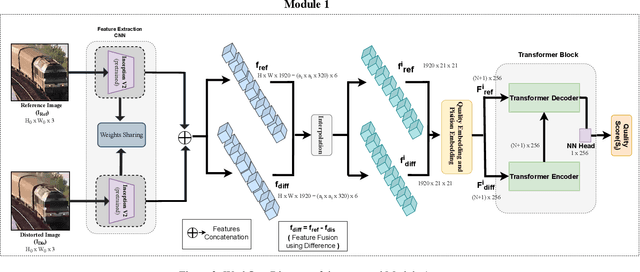
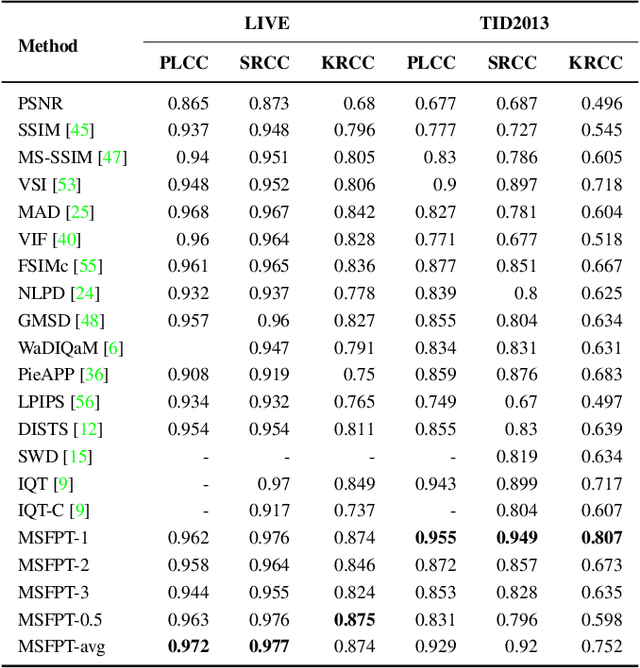
With the increase in multimedia content, the type of distortions associated with multimedia is also increasing. This problem of image quality assessment is expanded well in the PIPAL dataset, which is still an open problem to solve for researchers. Although, recently proposed transformers networks have already been used in the literature for image quality assessment. At the same time, we notice that multi-scale feature extraction has proven to be a promising approach for image quality assessment. However, the way transformer networks are used for image quality assessment until now lacks these properties of multi-scale feature extraction. We utilized this fact in our approach and proposed a new architecture by integrating these two promising quality assessment techniques of images. Our experimentation on various datasets, including the PIPAL dataset, demonstrates that the proposed integration technique outperforms existing algorithms. The source code of the proposed algorithm is available online: https://github.com/KomalPal9610/IQA
Detecting COVID-19 and Community Acquired Pneumonia using Chest CT scan images with Deep Learning
Apr 11, 2021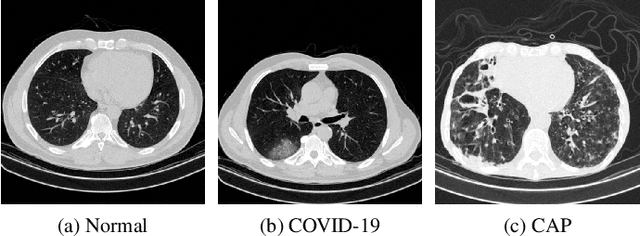
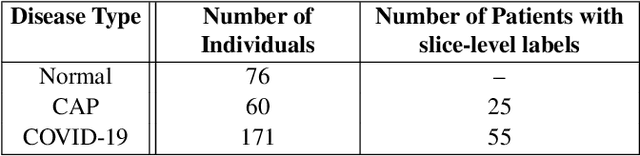

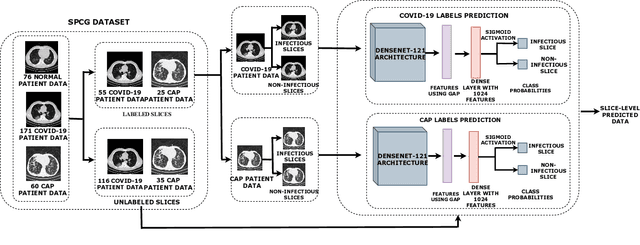
We propose a two-stage Convolutional Neural Network (CNN) based classification framework for detecting COVID-19 and Community-Acquired Pneumonia (CAP) using the chest Computed Tomography (CT) scan images. In the first stage, an infection - COVID-19 or CAP, is detected using a pre-trained DenseNet architecture. Then, in the second stage, a fine-grained three-way classification is done using EfficientNet architecture. The proposed COVID+CAP-CNN framework achieved a slice-level classification accuracy of over 94% at identifying COVID-19 and CAP. Further, the proposed framework has the potential to be an initial screening tool for differential diagnosis of COVID-19 and CAP, achieving a validation accuracy of over 89.3% at the finer three-way COVID-19, CAP, and healthy classification. Within the IEEE ICASSP 2021 Signal Processing Grand Challenge (SPGC) on COVID-19 Diagnosis, our proposed two-stage classification framework achieved an overall accuracy of 90% and sensitivity of .857, .9, and .942 at distinguishing COVID-19, CAP, and normal individuals respectively, to rank first in the evaluation. Code and model weights are available at https://github.com/shubhamchaudhary2015/ct_covid19_cap_cnn