 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfrIFact: Cultural Information Retrieval, Evidence Extraction and Fact Checking for African Languages
Apr 01, 2026Assessing the veracity of a claim made online is a complex and important task with real-world implications. When these claims are directed at communities with limited access to information and the content concerns issues such as healthcare and culture, the consequences intensify, especially in low-resource languages. In this work, we introduce AfrIFact, a dataset that covers the necessary steps for automatic fact-checking (i.e., information retrieval, evidence extraction, and fact checking), in ten African languages and English. Our evaluation results show that even the best embedding models lack cross-lingual retrieval capabilities, and that cultural and news documents are easier to retrieve than healthcare-domain documents, both in large corpora and in single documents. We show that LLMs lack robust multilingual fact-verification capabilities in African languages, while few-shot prompting improves performance by up to 43% in AfriqueQwen-14B, and task-specific fine-tuning further improves fact-checking accuracy by up to 26%. These findings, along with our release of the AfrIFact dataset, encourage work on low-resource information retrieval, evidence retrieval, and fact checking.
SceMoS: Scene-Aware 3D Human Motion Synthesis by Planning with Geometry-Grounded Tokens
Feb 24, 2026Synthesizing text-driven 3D human motion within realistic scenes requires learning both semantic intent ("walk to the couch") and physical feasibility (e.g., avoiding collisions). Current methods use generative frameworks that simultaneously learn high-level planning and low-level contact reasoning, and rely on computationally expensive 3D scene data such as point clouds or voxel occupancy grids. We propose SceMoS, a scene-aware motion synthesis framework that shows that structured 2D scene representations can serve as a powerful alternative to full 3D supervision in physically grounded motion synthesis. SceMoS disentangles global planning from local execution using lightweight 2D cues and relying on (1) a text-conditioned autoregressive global motion planner that operates on a bird's-eye-view (BEV) image rendered from an elevated corner of the scene, encoded with DINOv2 features, as the scene representation, and (2) a geometry-grounded motion tokenizer trained via a conditional VQ-VAE, that uses 2D local scene heightmap, thus embedding surface physics directly into a discrete vocabulary. This 2D factorization reaches an efficiency-fidelity trade-off: BEV semantics capture spatial layout and affordance for global reasoning, while local heightmaps enforce fine-grained physical adherence without full 3D volumetric reasoning. SceMoS achieves state-of-the-art motion realism and contact accuracy on the TRUMANS benchmark, reducing the number of trainable parameters for scene encoding by over 50%, showing that 2D scene cues can effectively ground 3D human-scene interaction.
AmharicStoryQA: A Multicultural Story Question Answering Benchmark in Amharic
Feb 02, 2026With the growing emphasis on multilingual and cultural evaluation benchmarks for large language models, language and culture are often treated as synonymous, and performance is commonly used as a proxy for a models understanding of a given language. In this work, we argue that such evaluations overlook meaningful cultural variation that exists within a single language. We address this gap by focusing on narratives from different regions of Ethiopia and demonstrate that, despite shared linguistic characteristics, region-specific and domain-specific content substantially influences language evaluation outcomes. To this end, we introduce \textbf{\textit{AmharicStoryQA}}, a long-sequence story question answering benchmark grounded in culturally diverse narratives from Amharic-speaking regions. Using this benchmark, we reveal a significant narrative understanding gap in existing LLMs, highlight pronounced regional differences in evaluation results, and show that supervised fine-tuning yields uneven improvements across regions and evaluation settings. Our findings emphasize the need for culturally grounded benchmarks that go beyond language-level evaluation to more accurately assess and improve narrative understanding in low-resource languages.
ObjectVisA-120: Object-based Visual Attention Prediction in Interactive Street-crossing Environments
Jan 19, 2026The object-based nature of human visual attention is well-known in cognitive science, but has only played a minor role in computational visual attention models so far. This is mainly due to a lack of suitable datasets and evaluation metrics for object-based attention. To address these limitations, we present \dataset~ -- a novel 120-participant dataset of spatial street-crossing navigation in virtual reality specifically geared to object-based attention evaluations. The uniqueness of the presented dataset lies in the ethical and safety affiliated challenges that make collecting comparable data in real-world environments highly difficult. \dataset~ not only features accurate gaze data and a complete state-space representation of objects in the virtual environment, but it also offers variable scenario complexities and rich annotations, including panoptic segmentation, depth information, and vehicle keypoints. We further propose object-based similarity (oSIM) as a novel metric to evaluate the performance of object-based visual attention models, a previously unexplored performance characteristic. Our evaluations show that explicitly optimising for object-based attention not only improves oSIM performance but also leads to an improved model performance on common metrics. In addition, we present SUMGraph, a Mamba U-Net-based model, which explicitly encodes critical scene objects (vehicles) in a graph representation, leading to further performance improvements over several state-of-the-art visual attention prediction methods. The dataset, code and models will be publicly released.
Accept or Deny? Evaluating LLM Fairness and Performance in Loan Approval across Table-to-Text Serialization Approaches
Aug 29, 2025



Large Language Models (LLMs) are increasingly employed in high-stakes decision-making tasks, such as loan approvals. While their applications expand across domains, LLMs struggle to process tabular data, ensuring fairness and delivering reliable predictions. In this work, we assess the performance and fairness of LLMs on serialized loan approval datasets from three geographically distinct regions: Ghana, Germany, and the United States. Our evaluation focuses on the model's zero-shot and in-context learning (ICL) capabilities. Our results reveal that the choice of serialization (Serialization refers to the process of converting tabular data into text formats suitable for processing by LLMs.) format significantly affects both performance and fairness in LLMs, with certain formats such as GReat and LIFT yielding higher F1 scores but exacerbating fairness disparities. Notably, while ICL improved model performance by 4.9-59.6% relative to zero-shot baselines, its effect on fairness varied considerably across datasets. Our work underscores the importance of effective tabular data representation methods and fairness-aware models to improve the reliability of LLMs in financial decision-making.
Quantum computing and artificial intelligence: status and perspectives
May 29, 2025


This white paper discusses and explores the various points of intersection between quantum computing and artificial intelligence (AI). It describes how quantum computing could support the development of innovative AI solutions. It also examines use cases of classical AI that can empower research and development in quantum technologies, with a focus on quantum computing and quantum sensing. The purpose of this white paper is to provide a long-term research agenda aimed at addressing foundational questions about how AI and quantum computing interact and benefit one another. It concludes with a set of recommendations and challenges, including how to orchestrate the proposed theoretical work, align quantum AI developments with quantum hardware roadmaps, estimate both classical and quantum resources - especially with the goal of mitigating and optimizing energy consumption - advance this emerging hybrid software engineering discipline, and enhance European industrial competitiveness while considering societal implications.
Evaluating the Capabilities of Large Language Models for Multi-label Emotion Understanding
Dec 17, 2024Large Language Models (LLMs) show promising learning and reasoning abilities. Compared to other NLP tasks, multilingual and multi-label emotion evaluation tasks are under-explored in LLMs. In this paper, we present EthioEmo, a multi-label emotion classification dataset for four Ethiopian languages, namely, Amharic (amh), Afan Oromo (orm), Somali (som), and Tigrinya (tir). We perform extensive experiments with an additional English multi-label emotion dataset from SemEval 2018 Task 1. Our evaluation includes encoder-only, encoder-decoder, and decoder-only language models. We compare zero and few-shot approaches of LLMs to fine-tuning smaller language models. The results show that accurate multi-label emotion classification is still insufficient even for high-resource languages such as English, and there is a large gap between the performance of high-resource and low-resource languages. The results also show varying performance levels depending on the language and model type. EthioEmo is available publicly to further improve the understanding of emotions in language models and how people convey emotions through various languages.
ProverbEval: Exploring LLM Evaluation Challenges for Low-resource Language Understanding
Nov 07, 2024



With the rapid development of evaluation datasets to assess LLMs understanding across a wide range of subjects and domains, identifying a suitable language understanding benchmark has become increasingly challenging. In this work, we explore LLM evaluation challenges for low-resource language understanding and introduce ProverbEval, LLM evaluation benchmark for low-resource languages based on proverbs to focus on low-resource language understanding in culture-specific scenarios. We benchmark various LLMs and explore factors that create variability in the benchmarking process. We observed performance variances of up to 50%, depending on the order in which answer choices were presented in multiple-choice tasks. Native language proverb descriptions significantly improve tasks such as proverb generation, contributing to improved outcomes. Additionally, monolingual evaluations consistently outperformed their cross-lingual counterparts. We argue special attention must be given to the order of choices, choice of prompt language, task variability, and generation tasks when creating LLM evaluation benchmarks.
N-BVH: Neural ray queries with bounding volume hierarchies
May 25, 2024



Neural representations have shown spectacular ability to compress complex signals in a fraction of the raw data size. In 3D computer graphics, the bulk of a scene's memory usage is due to polygons and textures, making them ideal candidates for neural compression. Here, the main challenge lies in finding good trade-offs between efficient compression and cheap inference while minimizing training time. In the context of rendering, we adopt a ray-centric approach to this problem and devise N-BVH, a neural compression architecture designed to answer arbitrary ray queries in 3D. Our compact model is learned from the input geometry and substituted for it whenever a ray intersection is queried by a path-tracing engine. While prior neural compression methods have focused on point queries, ours proposes neural ray queries that integrate seamlessly into standard ray-tracing pipelines. At the core of our method, we employ an adaptive BVH-driven probing scheme to optimize the parameters of a multi-resolution hash grid, focusing its neural capacity on the sparse 3D occupancy swept by the original surfaces. As a result, our N-BVH can serve accurate ray queries from a representation that is more than an order of magnitude more compact, providing faithful approximations of visibility, depth, and appearance attributes. The flexibility of our method allows us to combine and overlap neural and non-neural entities within the same 3D scene and extends to appearance level of detail.
* 10 pages
Reliable Student: Addressing Noise in Semi-Supervised 3D Object Detection
Apr 27, 2024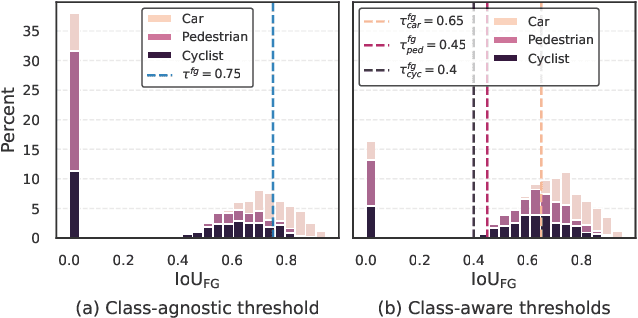
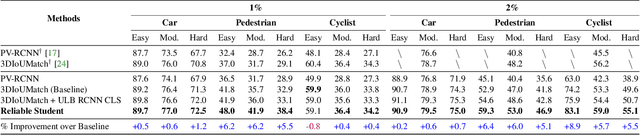
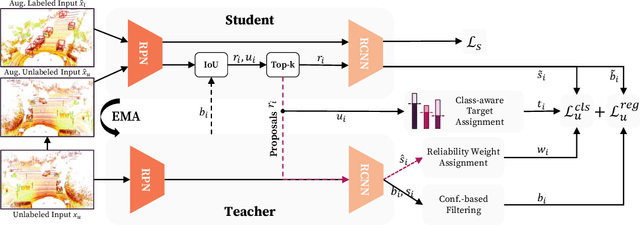
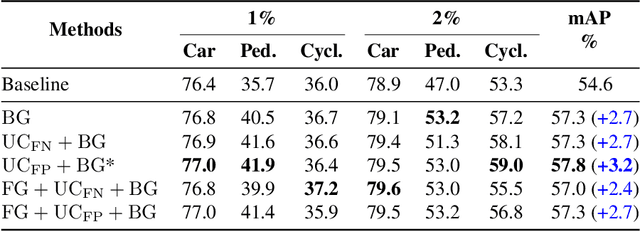
Semi-supervised 3D object detection can benefit from the promising pseudo-labeling technique when labeled data is limited. However, recent approaches have overlooked the impact of noisy pseudo-labels during training, despite efforts to enhance pseudo-label quality through confidence-based filtering. In this paper, we examine the impact of noisy pseudo-labels on IoU-based target assignment and propose the Reliable Student framework, which incorporates two complementary approaches to mitigate errors. First, it involves a class-aware target assignment strategy that reduces false negative assignments in difficult classes. Second, it includes a reliability weighting strategy that suppresses false positive assignment errors while also addressing remaining false negatives from the first step. The reliability weights are determined by querying the teacher network for confidence scores of the student-generated proposals. Our work surpasses the previous state-of-the-art on KITTI 3D object detection benchmark on point clouds in the semi-supervised setting. On 1% labeled data, our approach achieves a 6.2% AP improvement for the pedestrian class, despite having only 37 labeled samples available. The improvements become significant for the 2% setting, achieving 6.0% AP and 5.7% AP improvements for the pedestrian and cyclist classes, respectively.