 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework with Novel Metrics for Evaluating the Effectiveness of XAI Techniques in LLMs
Mar 06, 2025The increasing complexity of LLMs presents significant challenges to their transparency and interpretability, necessitating the use of eXplainable AI (XAI) techniques to enhance trustworthiness and usability. This study introduces a comprehensive evaluation framework with four novel metrics for assessing the effectiveness of five XAI techniques across five LLMs and two downstream tasks. We apply this framework to evaluate several XAI techniques LIME, SHAP, Integrated Gradients, Layer-wise Relevance Propagation (LRP), and Attention Mechanism Visualization (AMV) using the IMDB Movie Reviews and Tweet Sentiment Extraction datasets. The evaluation focuses on four key metrics: Human-reasoning Agreement (HA), Robustness, Consistency, and Contrastivity. Our results show that LIME consistently achieves high scores across multiple LLMs and evaluation metrics, while AMV demonstrates superior Robustness and near-perfect Consistency. LRP excels in Contrastivity, particularly with more complex models. Our findings provide valuable insights into the strengths and limitations of different XAI methods, offering guidance for developing and selecting appropriate XAI techniques for LLMs.
Evaluating the Effectiveness of XAI Techniques for Encoder-Based Language Models
Jan 26, 2025



The black-box nature of large language models (LLMs) necessitates the development of eXplainable AI (XAI) techniques for transparency and trustworthiness. However, evaluating these techniques remains a challenge. This study presents a general evaluation framework using four key metrics: Human-reasoning Agreement (HA), Robustness, Consistency, and Contrastivity. We assess the effectiveness of six explainability techniques from five different XAI categories model simplification (LIME), perturbation-based methods (SHAP), gradient-based approaches (InputXGradient, Grad-CAM), Layer-wise Relevance Propagation (LRP), and attention mechanisms-based explainability methods (Attention Mechanism Visualization, AMV) across five encoder-based language models: TinyBERT, BERTbase, BERTlarge, XLM-R large, and DeBERTa-xlarge, using the IMDB Movie Reviews and Tweet Sentiment Extraction (TSE) datasets. Our findings show that the model simplification-based XAI method (LIME) consistently outperforms across multiple metrics and models, significantly excelling in HA with a score of 0.9685 on DeBERTa-xlarge, robustness, and consistency as the complexity of large language models increases. AMV demonstrates the best Robustness, with scores as low as 0.0020. It also excels in Consistency, achieving near-perfect scores of 0.9999 across all models. Regarding Contrastivity, LRP performs the best, particularly on more complex models, with scores up to 0.9371.
Ethio-Fake: Cutting-Edge Approaches to Combat Fake News in Under-Resourced Languages Using Explainable AI
Oct 03, 2024



The proliferation of fake news has emerged as a significant threat to the integrity of information dissemination, particularly on social media platforms. Misinformation can spread quickly due to the ease of creating and disseminating content, affecting public opinion and sociopolitical events. Identifying false information is therefore essential to reducing its negative consequences and maintaining the reliability of online news sources. Traditional approaches to fake news detection often rely solely on content-based features, overlooking the crucial role of social context in shaping the perception and propagation of news articles. In this paper, we propose a comprehensive approach that integrates social context-based features with news content features to enhance the accuracy of fake news detection in under-resourced languages. We perform several experiments utilizing a variety of methodologies, including traditional machine learning, neural networks, ensemble learning, and transfer learning. Assessment of the outcomes of the experiments shows that the ensemble learning approach has the highest accuracy, achieving a 0.99 F1 score. Additionally, when compared with monolingual models, the fine-tuned model with the target language outperformed others, achieving a 0.94 F1 score. We analyze the functioning of the models, considering the important features that contribute to model performance, using explainable AI techniques.
EthioLLM: Multilingual Large Language Models for Ethiopian Languages with Task Evaluation
Mar 26, 2024



Large language models (LLMs) have gained popularity recently due to their outstanding performance in various downstream Natural Language Processing (NLP) tasks. However, low-resource languages are still lagging behind current state-of-the-art (SOTA) developments in the field of NLP due to insufficient resources to train LLMs. Ethiopian languages exhibit remarkable linguistic diversity, encompassing a wide array of scripts, and are imbued with profound religious and cultural significance. This paper introduces EthioLLM -- multilingual large language models for five Ethiopian languages (Amharic, Ge'ez, Afan Oromo, Somali, and Tigrinya) and English, and Ethiobenchmark -- a new benchmark dataset for various downstream NLP tasks. We evaluate the performance of these models across five downstream NLP tasks. We open-source our multilingual language models, new benchmark datasets for various downstream tasks, and task-specific fine-tuned language models and discuss the performance of the models. Our dataset and models are available at the https://huggingface.co/EthioNLP repository.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023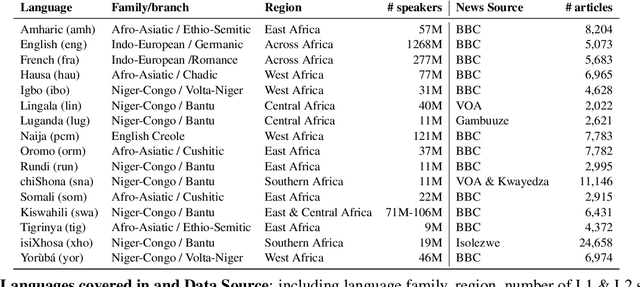
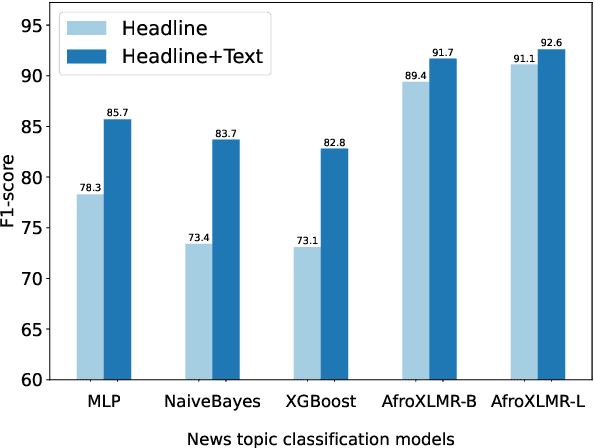
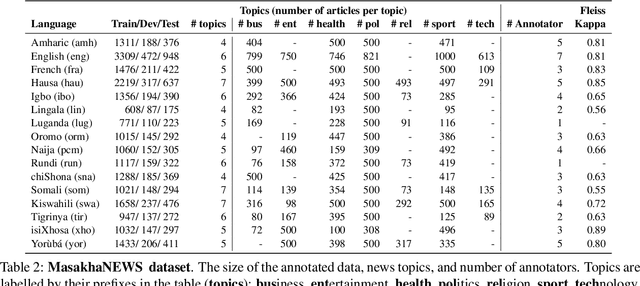
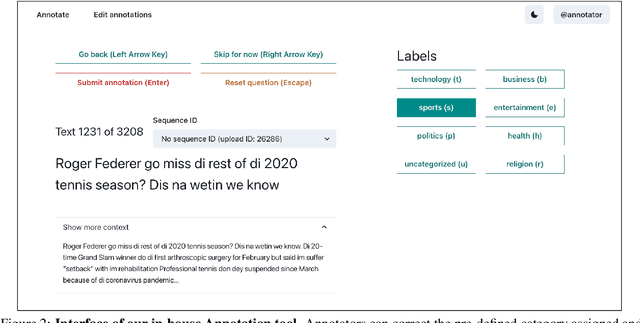
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
Transformer-based Model for Word Level Language Identification in Code-mixed Kannada-English Texts
Nov 26, 2022Using code-mixed data in natural language processing (NLP) research currently gets a lot of attention. Language identification of social media code-mixed text has been an interesting problem of study in recent years due to the advancement and influences of social media in communication. This paper presents the Instituto Polit\'ecnico Nacional, Centro de Investigaci\'on en Computaci\'on (CIC) team's system description paper for the CoLI-Kanglish shared task at ICON2022. In this paper, we propose the use of a Transformer based model for word-level language identification in code-mixed Kannada English texts. The proposed model on the CoLI-Kenglish dataset achieves a weighted F1-score of 0.84 and a macro F1-score of 0.61.