 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthioLLM: Multilingual Large Language Models for Ethiopian Languages with Task Evaluation
Mar 26, 2024



Large language models (LLMs) have gained popularity recently due to their outstanding performance in various downstream Natural Language Processing (NLP) tasks. However, low-resource languages are still lagging behind current state-of-the-art (SOTA) developments in the field of NLP due to insufficient resources to train LLMs. Ethiopian languages exhibit remarkable linguistic diversity, encompassing a wide array of scripts, and are imbued with profound religious and cultural significance. This paper introduces EthioLLM -- multilingual large language models for five Ethiopian languages (Amharic, Ge'ez, Afan Oromo, Somali, and Tigrinya) and English, and Ethiobenchmark -- a new benchmark dataset for various downstream NLP tasks. We evaluate the performance of these models across five downstream NLP tasks. We open-source our multilingual language models, new benchmark datasets for various downstream tasks, and task-specific fine-tuned language models and discuss the performance of the models. Our dataset and models are available at the https://huggingface.co/EthioNLP repository.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023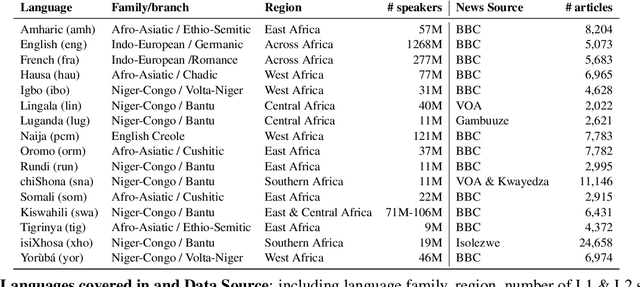
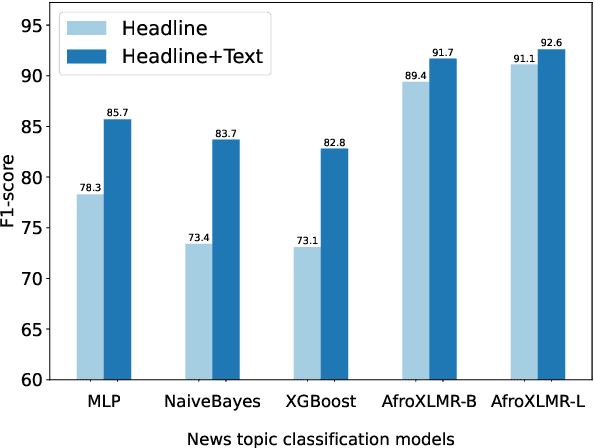
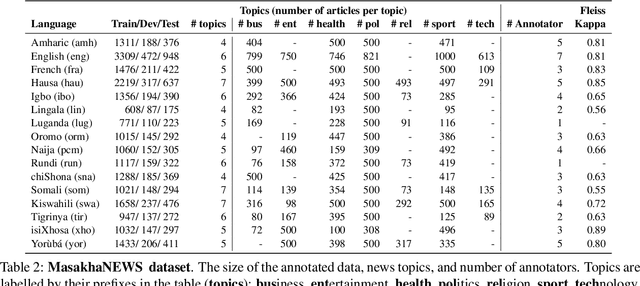
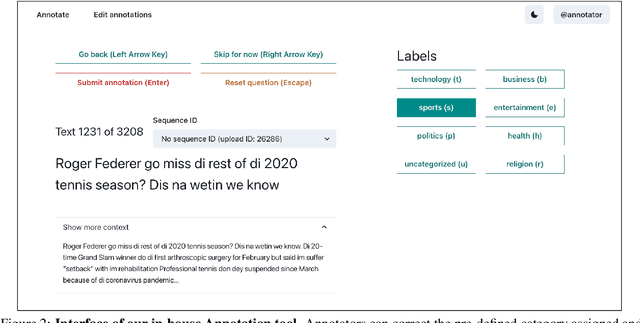
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
Natural Language Processing in Ethiopian Languages: Current State, Challenges, and Opportunities
Mar 25, 2023



This survey delves into the current state of natural language processing (NLP) for four Ethiopian languages: Amharic, Afaan Oromo, Tigrinya, and Wolaytta. Through this paper, we identify key challenges and opportunities for NLP research in Ethiopia. Furthermore, we provide a centralized repository on GitHub that contains publicly available resources for various NLP tasks in these languages. This repository can be updated periodically with contributions from other researchers. Our objective is to identify research gaps and disseminate the information to NLP researchers interested in Ethiopian languages and encourage future research in this domain.