 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriHate: A Multilingual Collection of Hate Speech and Abusive Language Datasets for African Languages
Jan 15, 2025



Hate speech and abusive language are global phenomena that need socio-cultural background knowledge to be understood, identified, and moderated. However, in many regions of the Global South, there have been several documented occurrences of (1) absence of moderation and (2) censorship due to the reliance on keyword spotting out of context. Further, high-profile individuals have frequently been at the center of the moderation process, while large and targeted hate speech campaigns against minorities have been overlooked. These limitations are mainly due to the lack of high-quality data in the local languages and the failure to include local communities in the collection, annotation, and moderation processes. To address this issue, we present AfriHate: a multilingual collection of hate speech and abusive language datasets in 15 African languages. Each instance in AfriHate is annotated by native speakers familiar with the local culture. We report the challenges related to the construction of the datasets and present various classification baseline results with and without using LLMs. The datasets, individual annotations, and hate speech and offensive language lexicons are available on https://github.com/AfriHate/AfriHate
EthioLLM: Multilingual Large Language Models for Ethiopian Languages with Task Evaluation
Mar 26, 2024



Large language models (LLMs) have gained popularity recently due to their outstanding performance in various downstream Natural Language Processing (NLP) tasks. However, low-resource languages are still lagging behind current state-of-the-art (SOTA) developments in the field of NLP due to insufficient resources to train LLMs. Ethiopian languages exhibit remarkable linguistic diversity, encompassing a wide array of scripts, and are imbued with profound religious and cultural significance. This paper introduces EthioLLM -- multilingual large language models for five Ethiopian languages (Amharic, Ge'ez, Afan Oromo, Somali, and Tigrinya) and English, and Ethiobenchmark -- a new benchmark dataset for various downstream NLP tasks. We evaluate the performance of these models across five downstream NLP tasks. We open-source our multilingual language models, new benchmark datasets for various downstream tasks, and task-specific fine-tuned language models and discuss the performance of the models. Our dataset and models are available at the https://huggingface.co/EthioNLP repository.
ANEC: An Amharic Named Entity Corpus and Transformer Based Recognizer
Jul 02, 2022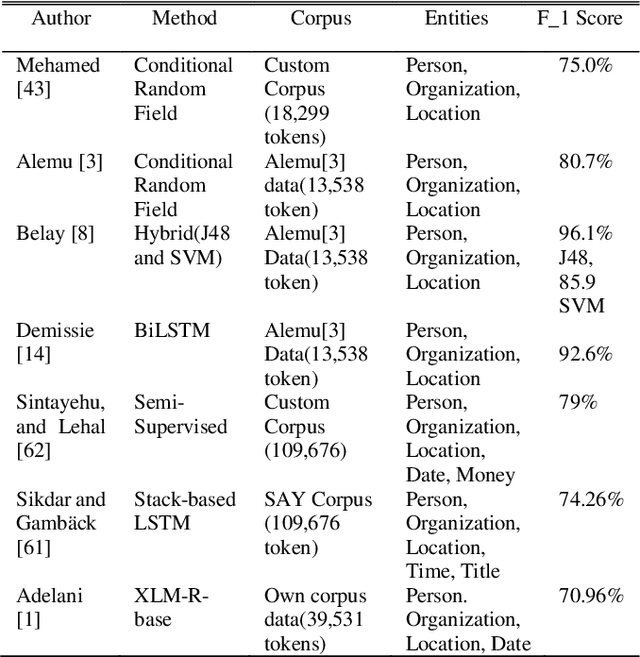
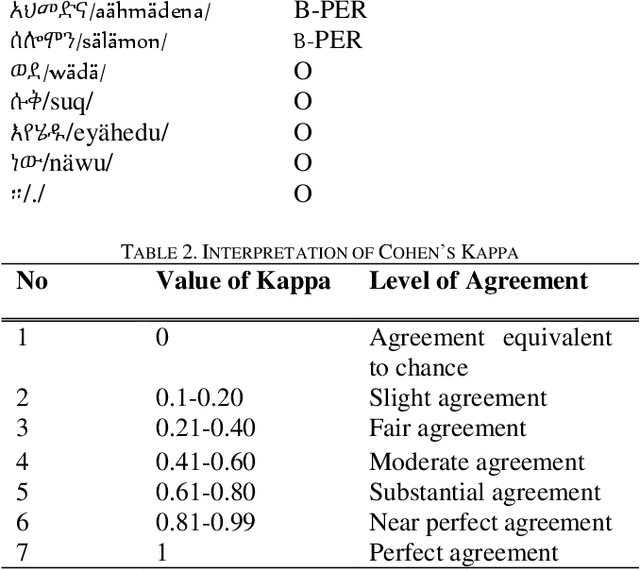
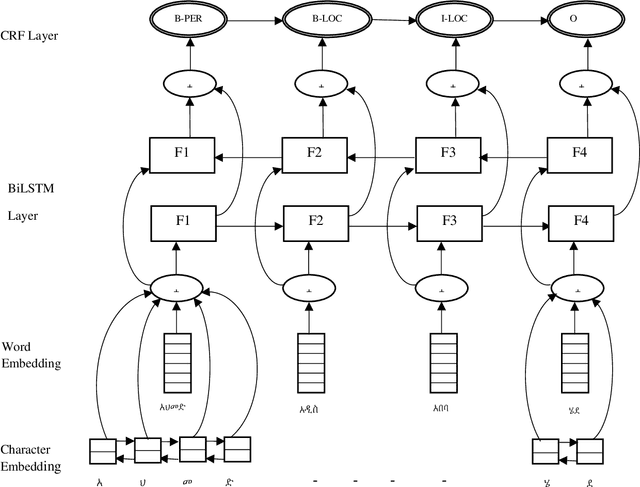
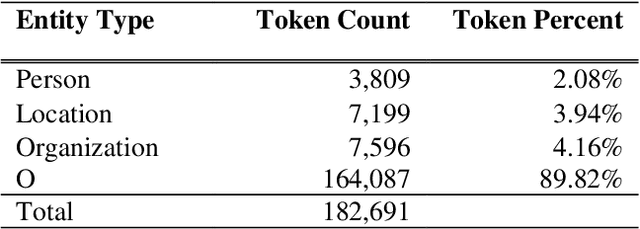
Named Entity Recognition is an information extraction task that serves as a preprocessing step for other natural language processing tasks, such as machine translation, information retrieval, and question answering. Named entity recognition enables the identification of proper names as well as temporal and numeric expressions in an open domain text. For Semitic languages such as Arabic, Amharic, and Hebrew, the named entity recognition task is more challenging due to the heavily inflected structure of these languages. In this paper, we present an Amharic named entity recognition system based on bidirectional long short-term memory with a conditional random fields layer. We annotate a new Amharic named entity recognition dataset (8,070 sentences, which has 182,691 tokens) and apply Synthetic Minority Over-sampling Technique to our dataset to mitigate the imbalanced classification problem. Our named entity recognition system achieves an F_1 score of 93%, which is the new state-of-the-art result for Amharic named entity recognition.