 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANEC: An Amharic Named Entity Corpus and Transformer Based Recognizer
Paper and Code
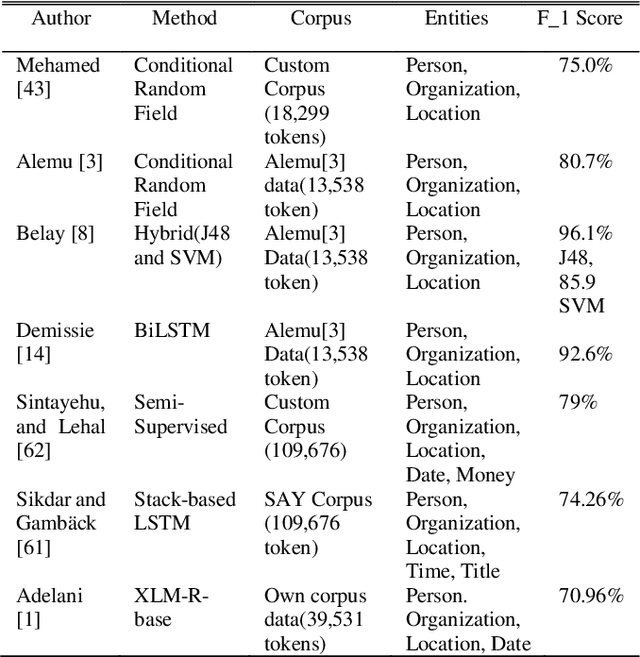
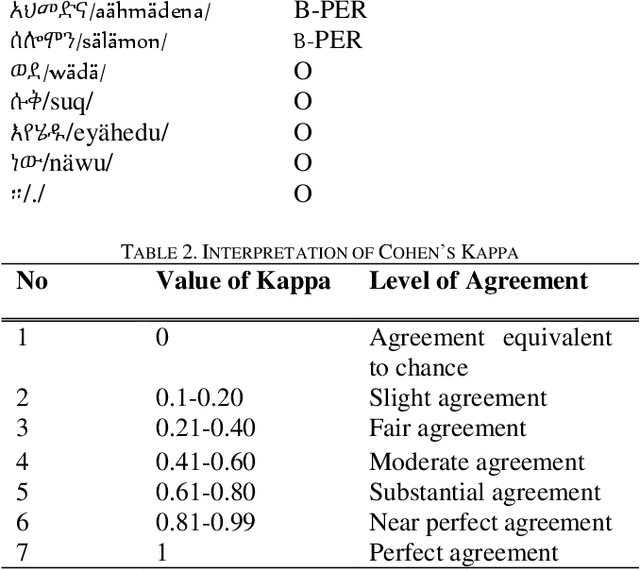
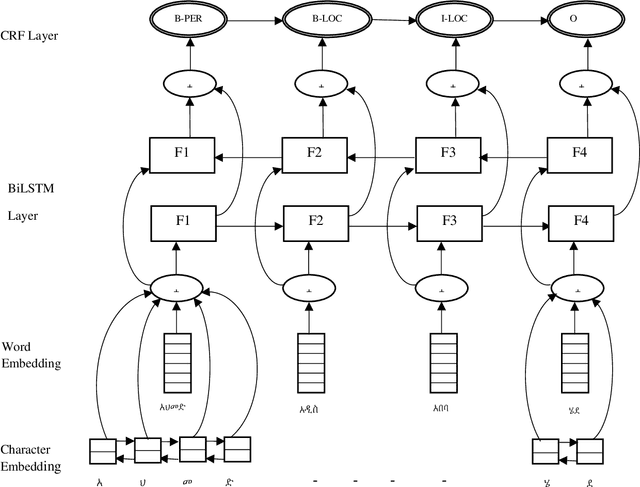
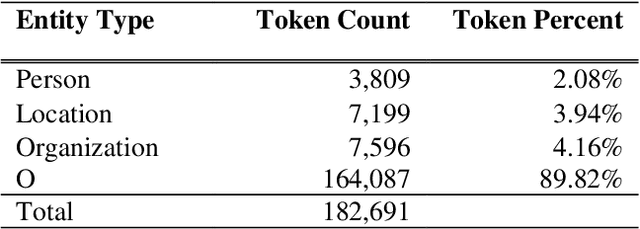
Named Entity Recognition is an information extraction task that serves as a preprocessing step for other natural language processing tasks, such as machine translation, information retrieval, and question answering. Named entity recognition enables the identification of proper names as well as temporal and numeric expressions in an open domain text. For Semitic languages such as Arabic, Amharic, and Hebrew, the named entity recognition task is more challenging due to the heavily inflected structure of these languages. In this paper, we present an Amharic named entity recognition system based on bidirectional long short-term memory with a conditional random fields layer. We annotate a new Amharic named entity recognition dataset (8,070 sentences, which has 182,691 tokens) and apply Synthetic Minority Over-sampling Technique to our dataset to mitigate the imbalanced classification problem. Our named entity recognition system achieves an F_1 score of 93%, which is the new state-of-the-art result for Amharic named entity recognition.