 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfrIFact: Cultural Information Retrieval, Evidence Extraction and Fact Checking for African Languages
Apr 01, 2026Assessing the veracity of a claim made online is a complex and important task with real-world implications. When these claims are directed at communities with limited access to information and the content concerns issues such as healthcare and culture, the consequences intensify, especially in low-resource languages. In this work, we introduce AfrIFact, a dataset that covers the necessary steps for automatic fact-checking (i.e., information retrieval, evidence extraction, and fact checking), in ten African languages and English. Our evaluation results show that even the best embedding models lack cross-lingual retrieval capabilities, and that cultural and news documents are easier to retrieve than healthcare-domain documents, both in large corpora and in single documents. We show that LLMs lack robust multilingual fact-verification capabilities in African languages, while few-shot prompting improves performance by up to 43% in AfriqueQwen-14B, and task-specific fine-tuning further improves fact-checking accuracy by up to 26%. These findings, along with our release of the AfrIFact dataset, encourage work on low-resource information retrieval, evidence retrieval, and fact checking.
AfriHate: A Multilingual Collection of Hate Speech and Abusive Language Datasets for African Languages
Jan 15, 2025



Hate speech and abusive language are global phenomena that need socio-cultural background knowledge to be understood, identified, and moderated. However, in many regions of the Global South, there have been several documented occurrences of (1) absence of moderation and (2) censorship due to the reliance on keyword spotting out of context. Further, high-profile individuals have frequently been at the center of the moderation process, while large and targeted hate speech campaigns against minorities have been overlooked. These limitations are mainly due to the lack of high-quality data in the local languages and the failure to include local communities in the collection, annotation, and moderation processes. To address this issue, we present AfriHate: a multilingual collection of hate speech and abusive language datasets in 15 African languages. Each instance in AfriHate is annotated by native speakers familiar with the local culture. We report the challenges related to the construction of the datasets and present various classification baseline results with and without using LLMs. The datasets, individual annotations, and hate speech and offensive language lexicons are available on https://github.com/AfriHate/AfriHate
Mitigating Translationese in Low-resource Languages: The Storyboard Approach
Jul 14, 2024Low-resource languages often face challenges in acquiring high-quality language data due to the reliance on translation-based methods, which can introduce the translationese effect. This phenomenon results in translated sentences that lack fluency and naturalness in the target language. In this paper, we propose a novel approach for data collection by leveraging storyboards to elicit more fluent and natural sentences. Our method involves presenting native speakers with visual stimuli in the form of storyboards and collecting their descriptions without direct exposure to the source text. We conducted a comprehensive evaluation comparing our storyboard-based approach with traditional text translation-based methods in terms of accuracy and fluency. Human annotators and quantitative metrics were used to assess translation quality. The results indicate a preference for text translation in terms of accuracy, while our method demonstrates worse accuracy but better fluency in the language focused.
* published at LREC-COLING 2024
A multilingual dataset for offensive language and hate speech detection for hausa, yoruba and igbo languages
Jun 04, 2024


The proliferation of online offensive language necessitates the development of effective detection mechanisms, especially in multilingual contexts. This study addresses the challenge by developing and introducing novel datasets for offensive language detection in three major Nigerian languages: Hausa, Yoruba, and Igbo. We collected data from Twitter and manually annotated it to create datasets for each of the three languages, using native speakers. We used pre-trained language models to evaluate their efficacy in detecting offensive language in our datasets. The best-performing model achieved an accuracy of 90\%. To further support research in offensive language detection, we plan to make the dataset and our models publicly available.
HausaNLP at SemEval-2023 Task 10: Transfer Learning, Synthetic Data and Side-Information for Multi-Level Sexism Classification
Apr 28, 2023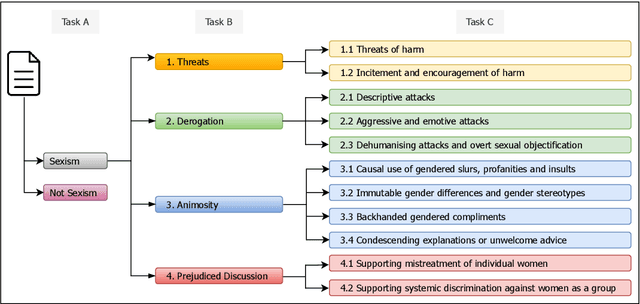

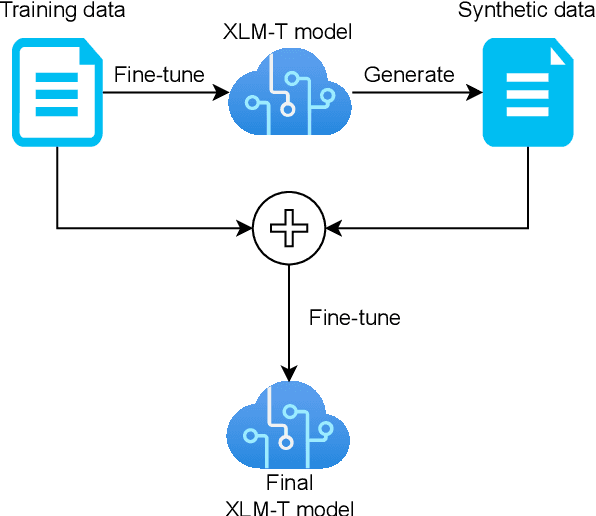
We present the findings of our participation in the SemEval-2023 Task 10: Explainable Detection of Online Sexism (EDOS) task, a shared task on offensive language (sexism) detection on English Gab and Reddit dataset. We investigated the effects of transferring two language models: XLM-T (sentiment classification) and HateBERT (same domain -- Reddit) for multi-level classification into Sexist or not Sexist, and other subsequent sub-classifications of the sexist data. We also use synthetic classification of unlabelled dataset and intermediary class information to maximize the performance of our models. We submitted a system in Task A, and it ranked 49th with F1-score of 0.82. This result showed to be competitive as it only under-performed the best system by 0.052% F1-score.
HausaNLP at SemEval-2023 Task 12: Leveraging African Low Resource TweetData for Sentiment Analysis
Apr 26, 2023We present the findings of SemEval-2023 Task 12, a shared task on sentiment analysis for low-resource African languages using Twitter dataset. The task featured three subtasks; subtask A is monolingual sentiment classification with 12 tracks which are all monolingual languages, subtask B is multilingual sentiment classification using the tracks in subtask A and subtask C is a zero-shot sentiment classification. We present the results and findings of subtask A, subtask B and subtask C. We also release the code on github. Our goal is to leverage low-resource tweet data using pre-trained Afro-xlmr-large, AfriBERTa-Large, Bert-base-arabic-camelbert-da-sentiment (Arabic-camelbert), Multilingual-BERT (mBERT) and BERT models for sentiment analysis of 14 African languages. The datasets for these subtasks consists of a gold standard multi-class labeled Twitter datasets from these languages. Our results demonstrate that Afro-xlmr-large model performed better compared to the other models in most of the languages datasets. Similarly, Nigerian languages: Hausa, Igbo, and Yoruba achieved better performance compared to other languages and this can be attributed to the higher volume of data present in the languages.
HERDPhobia: A Dataset for Hate Speech against Fulani in Nigeria
Nov 28, 2022



Social media platforms allow users to freely share their opinions about issues or anything they feel like. However, they also make it easier to spread hate and abusive content. The Fulani ethnic group has been the victim of this unfortunate phenomenon. This paper introduces the HERDPhobia - the first annotated hate speech dataset on Fulani herders in Nigeria - in three languages: English, Nigerian-Pidgin, and Hausa. We present a benchmark experiment using pre-trained languages models to classify the tweets as either hateful or non-hateful. Our experiment shows that the XML-T model provides better performance with 99.83% weighted F1. We released the dataset at https://github.com/hausanlp/HERDPhobia for further research.
Deep Sequence Models for Text Classification Tasks
Jul 18, 2022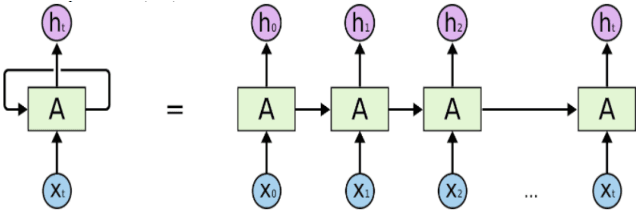

The exponential growth of data generated on the Internet in the current information age is a driving force for the digital economy. Extraction of information is the major value in an accumulated big data. Big data dependency on statistical analysis and hand-engineered rules machine learning algorithms are overwhelmed with vast complexities inherent in human languages. Natural Language Processing (NLP) is equipping machines to understand these human diverse and complicated languages. Text Classification is an NLP task which automatically identifies patterns based on predefined or undefined labeled sets. Common text classification application includes information retrieval, modeling news topic, theme extraction, sentiment analysis, and spam detection. In texts, some sequences of words depend on the previous or next word sequences to make full meaning; this is a challenging dependency task that requires the machine to be able to store some previous important information to impact future meaning. Sequence models such as RNN, GRU, and LSTM is a breakthrough for tasks with long-range dependencies. As such, we applied these models to Binary and Multi-class classification. Results generated were excellent with most of the models performing within the range of 80% and 94%. However, this result is not exhaustive as we believe there is room for improvement if machines are to compete with humans.