 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023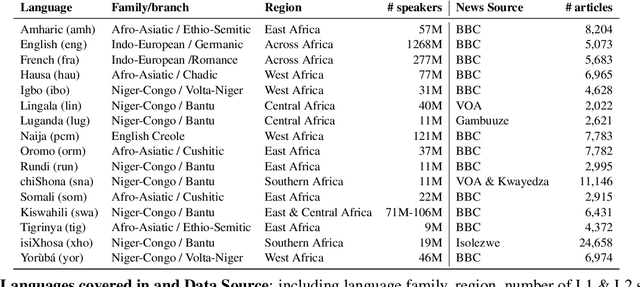
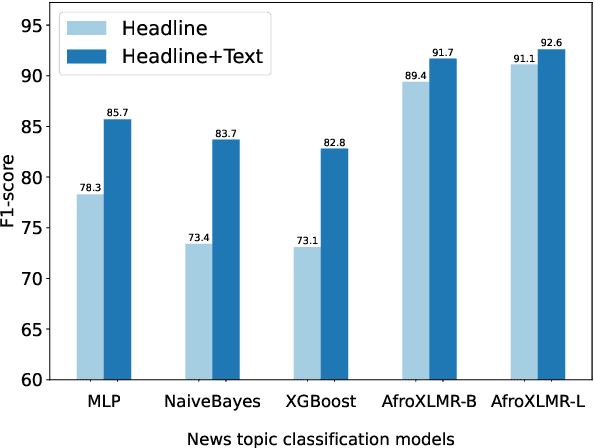
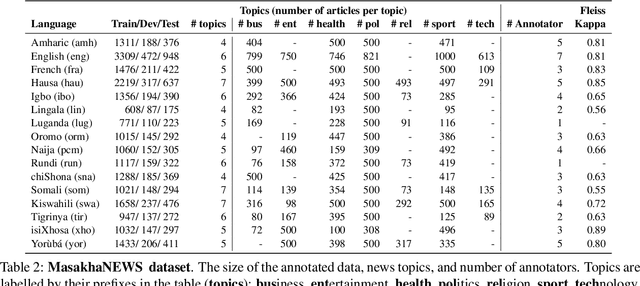
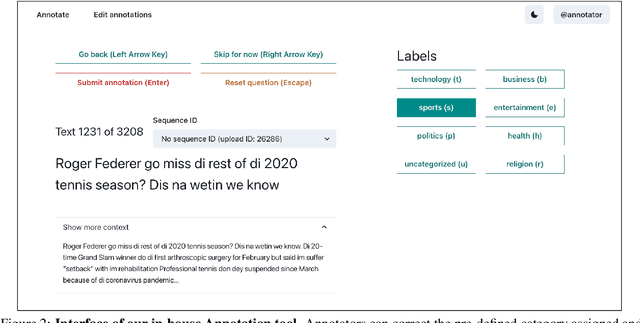
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
Deep Sequence Models for Text Classification Tasks
Jul 18, 2022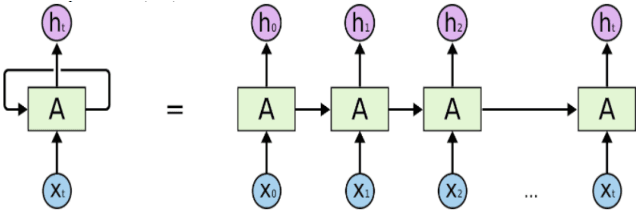
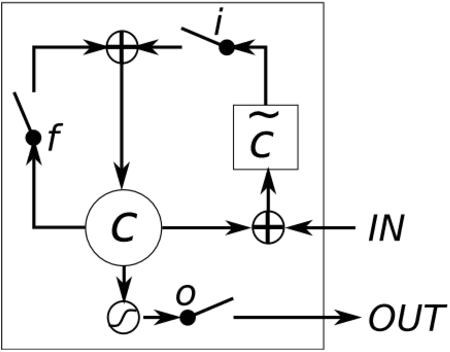
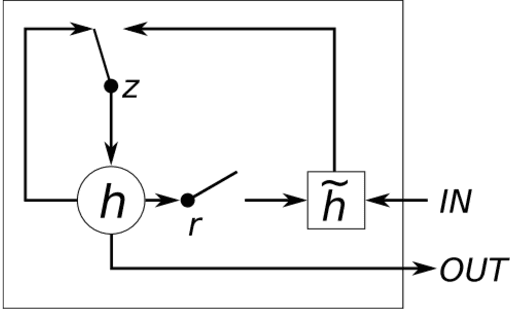

The exponential growth of data generated on the Internet in the current information age is a driving force for the digital economy. Extraction of information is the major value in an accumulated big data. Big data dependency on statistical analysis and hand-engineered rules machine learning algorithms are overwhelmed with vast complexities inherent in human languages. Natural Language Processing (NLP) is equipping machines to understand these human diverse and complicated languages. Text Classification is an NLP task which automatically identifies patterns based on predefined or undefined labeled sets. Common text classification application includes information retrieval, modeling news topic, theme extraction, sentiment analysis, and spam detection. In texts, some sequences of words depend on the previous or next word sequences to make full meaning; this is a challenging dependency task that requires the machine to be able to store some previous important information to impact future meaning. Sequence models such as RNN, GRU, and LSTM is a breakthrough for tasks with long-range dependencies. As such, we applied these models to Binary and Multi-class classification. Results generated were excellent with most of the models performing within the range of 80% and 94%. However, this result is not exhaustive as we believe there is room for improvement if machines are to compete with humans.
NaijaSenti: A Nigerian Twitter Sentiment Corpus for Multilingual Sentiment Analysis
Jan 28, 2022
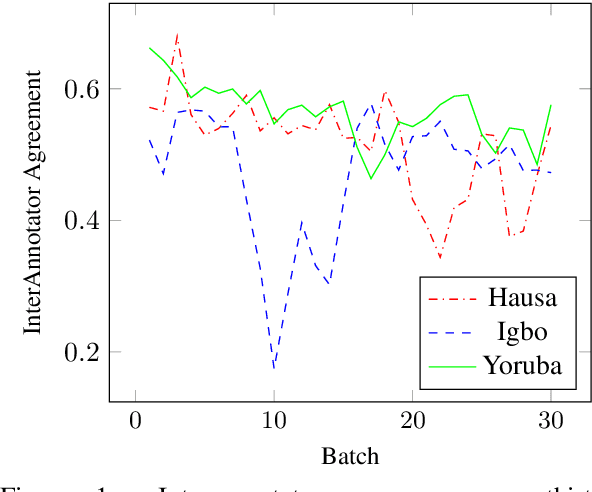

Sentiment analysis is one of the most widely studied applications in NLP, but most work focuses on languages with large amounts of data. We introduce the first large-scale human-annotated Twitter sentiment dataset for the four most widely spoken languages in Nigeria (Hausa, Igbo, Nigerian-Pidgin, and Yor\`ub\'a ) consisting of around 30,000 annotated tweets per language (and 14,000 for Nigerian-Pidgin), including a significant fraction of code-mixed tweets. We propose text collection, filtering, processing and labeling methods that enable us to create datasets for these low-resource languages. We evaluate a rangeof pre-trained models and transfer strategies on the dataset. We find that language-specific models and language-adaptivefine-tuning generally perform best. We release the datasets, trained models, sentiment lexicons, and code to incentivizeresearch on sentiment analysis in under-represented languages.