 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Sequence Models for Text Classification Tasks
Jul 18, 2022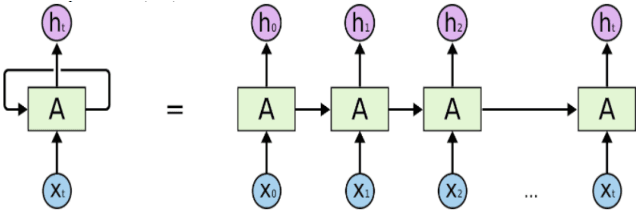
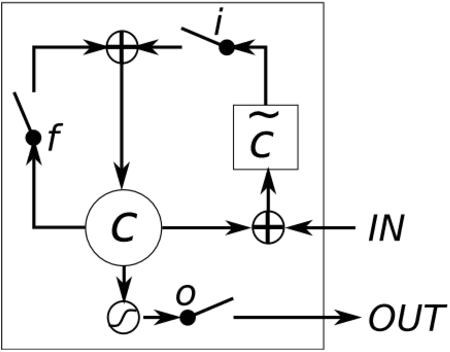
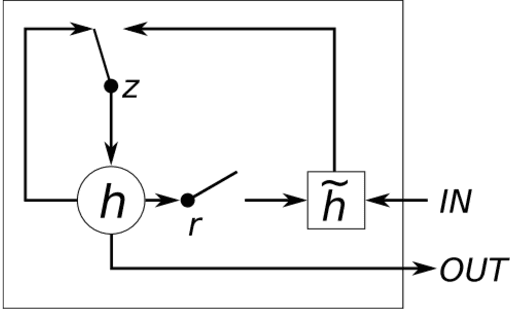

The exponential growth of data generated on the Internet in the current information age is a driving force for the digital economy. Extraction of information is the major value in an accumulated big data. Big data dependency on statistical analysis and hand-engineered rules machine learning algorithms are overwhelmed with vast complexities inherent in human languages. Natural Language Processing (NLP) is equipping machines to understand these human diverse and complicated languages. Text Classification is an NLP task which automatically identifies patterns based on predefined or undefined labeled sets. Common text classification application includes information retrieval, modeling news topic, theme extraction, sentiment analysis, and spam detection. In texts, some sequences of words depend on the previous or next word sequences to make full meaning; this is a challenging dependency task that requires the machine to be able to store some previous important information to impact future meaning. Sequence models such as RNN, GRU, and LSTM is a breakthrough for tasks with long-range dependencies. As such, we applied these models to Binary and Multi-class classification. Results generated were excellent with most of the models performing within the range of 80% and 94%. However, this result is not exhaustive as we believe there is room for improvement if machines are to compete with humans.