 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Beg to Differ: Understanding Reasoning-Answer Misalignment Across Languages
Dec 27, 2025Large language models demonstrate strong reasoning capabilities through chain-of-thought prompting, but whether this reasoning quality transfers across languages remains underexplored. We introduce a human-validated framework to evaluate whether model-generated reasoning traces logically support their conclusions across languages. Analyzing 65k reasoning traces from GlobalMMLU questions across 6 languages and 6 frontier models, we uncover a critical blind spot: while models achieve high task accuracy, their reasoning can fail to support their conclusions. Reasoning traces in non-Latin scripts show at least twice as much misalignment between their reasoning and conclusions than those in Latin scripts. We develop an error taxonomy through human annotation to characterize these failures, finding they stem primarily from evidential errors (unsupported claims, ambiguous facts) followed by illogical reasoning steps. Our findings demonstrate that current multilingual evaluation practices provide an incomplete picture of model reasoning capabilities and highlight the need for reasoning-aware evaluation frameworks.
MENLO: From Preferences to Proficiency -- Evaluating and Modeling Native-like Quality Across 47 Languages
Sep 30, 2025



Ensuring native-like quality of large language model (LLM) responses across many languages is challenging. To address this, we introduce MENLO, a framework that operationalizes the evaluation of native-like response quality based on audience design-inspired mechanisms. Using MENLO, we create a dataset of 6,423 human-annotated prompt-response preference pairs covering four quality dimensions with high inter-annotator agreement in 47 language varieties. Our evaluation reveals that zero-shot LLM judges benefit significantly from pairwise evaluation and our structured annotation rubrics, yet they still underperform human annotators on our dataset. We demonstrate substantial improvements through fine-tuning with reinforcement learning, reward shaping, and multi-task learning approaches. Additionally, we show that RL-trained judges can serve as generative reward models to enhance LLMs' multilingual proficiency, though discrepancies with human judgment remain. Our findings suggest promising directions for scalable multilingual evaluation and preference alignment. We release our dataset and evaluation framework to support further research in multilingual LLM evaluation.
Arbiters of Ambivalence: Challenges of Using LLMs in No-Consensus Tasks
May 28, 2025The increasing use of LLMs as substitutes for humans in ``aligning'' LLMs has raised questions about their ability to replicate human judgments and preferences, especially in ambivalent scenarios where humans disagree. This study examines the biases and limitations of LLMs in three roles: answer generator, judge, and debater. These roles loosely correspond to previously described alignment frameworks: preference alignment (judge) and scalable oversight (debater), with the answer generator reflecting the typical setting with user interactions. We develop a ``no-consensus'' benchmark by curating examples that encompass a variety of a priori ambivalent scenarios, each presenting two possible stances. Our results show that while LLMs can provide nuanced assessments when generating open-ended answers, they tend to take a stance on no-consensus topics when employed as judges or debaters. These findings underscore the necessity for more sophisticated methods for aligning LLMs without human oversight, highlighting that LLMs cannot fully capture human disagreement even on topics where humans themselves are divided.
The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
Apr 24, 2025Sparse attention offers a promising strategy to extend long-context capabilities in Transformer LLMs, yet its viability, its efficiency-accuracy trade-offs, and systematic scaling studies remain unexplored. To address this gap, we perform a careful comparison of training-free sparse attention methods at varying model scales, sequence lengths, and sparsity levels on a diverse collection of long-sequence tasks-including novel ones that rely on natural language while remaining controllable and easy to evaluate. Based on our experiments, we report a series of key findings: 1) an isoFLOPS analysis reveals that for very long sequences, larger and highly sparse models are preferable to smaller and dense ones. 2) The level of sparsity attainable while statistically guaranteeing accuracy preservation is higher during decoding than prefilling, and correlates with model size in the former. 3) There is no clear strategy that performs best across tasks and phases, with different units of sparsification or budget adaptivity needed for different scenarios. Even moderate sparsity levels often result in significant performance degradation on at least one task, highlighting that sparse attention is not a universal solution. 4) We introduce and validate novel scaling laws specifically tailored for sparse attention, providing evidence that our findings are likely to hold true beyond our range of experiments. Through these insights, we demonstrate that sparse attention is a key tool to enhance the capabilities of Transformer LLMs for processing longer sequences, but requires careful evaluation of trade-offs for performance-sensitive applications.
A Post-trainer's Guide to Multilingual Training Data: Uncovering Cross-lingual Transfer Dynamics
Apr 23, 2025In order for large language models to be useful across the globe, they are fine-tuned to follow instructions on multilingual data. Despite the ubiquity of such post-training, a clear understanding of the dynamics that enable cross-lingual transfer remains elusive. This study examines cross-lingual transfer (CLT) dynamics in realistic post-training settings. We study two model families of up to 35B parameters in size trained on carefully controlled mixtures of multilingual data on three generative tasks with varying levels of complexity (summarization, instruction following, and mathematical reasoning) in both single-task and multi-task instruction tuning settings. Overall, we find that the dynamics of cross-lingual transfer and multilingual performance cannot be explained by isolated variables, varying depending on the combination of post-training settings. Finally, we identify the conditions that lead to effective cross-lingual transfer in practice.
AL-QASIDA: Analyzing LLM Quality and Accuracy Systematically in Dialectal Arabic
Dec 05, 2024



Dialectal Arabic (DA) varieties are under-served by language technologies, particularly large language models (LLMs). This trend threatens to exacerbate existing social inequalities and limits language modeling applications, yet the research community lacks operationalized LLM performance measurements in DA. We present a method that comprehensively evaluates LLM fidelity, understanding, quality, and diglossia in modeling DA. We evaluate nine LLMs in eight DA varieties across these four dimensions and provide best practice recommendations. Our evaluation suggests that LLMs do not produce DA as well as they understand it, but does not suggest deterioration in quality when they do. Further analysis suggests that current post-training can degrade DA capabilities, that few-shot examples can overcome this and other LLM deficiencies, and that otherwise no measurable features of input text correlate well with LLM DA performance.
M-RewardBench: Evaluating Reward Models in Multilingual Settings
Oct 20, 2024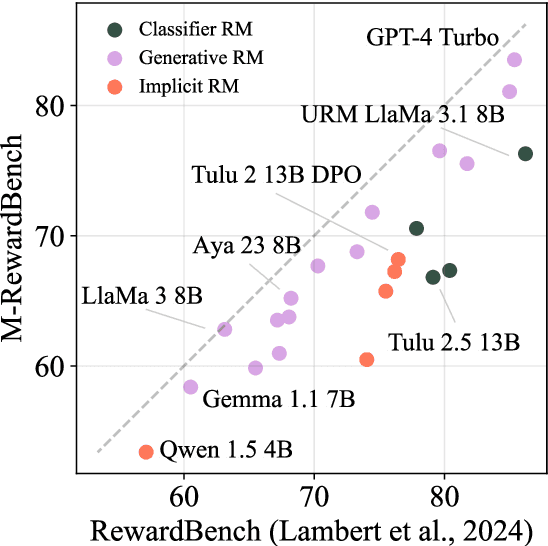



Reward models (RMs) have driven the state-of-the-art performance of LLMs today by enabling the integration of human feedback into the language modeling process. However, RMs are primarily trained and evaluated in English, and their capabilities in multilingual settings remain largely understudied. In this work, we conduct a systematic evaluation of several reward models in multilingual settings. We first construct the first-of-its-kind multilingual RM evaluation benchmark, M-RewardBench, consisting of 2.87k preference instances for 23 typologically diverse languages, that tests the chat, safety, reasoning, and translation capabilities of RMs. We then rigorously evaluate a wide range of reward models on M-RewardBench, offering fresh insights into their performance across diverse languages. We identify a significant gap in RMs' performances between English and non-English languages and show that RM preferences can change substantially from one language to another. We also present several findings on how different multilingual aspects impact RM performance. Specifically, we show that the performance of RMs is improved with improved translation quality. Similarly, we demonstrate that the models exhibit better performance for high-resource languages. We release M-RewardBench dataset and the codebase in this study to facilitate a better understanding of RM evaluation in multilingual settings.
BAM! Just Like That: Simple and Efficient Parameter Upcycling for Mixture of Experts
Aug 15, 2024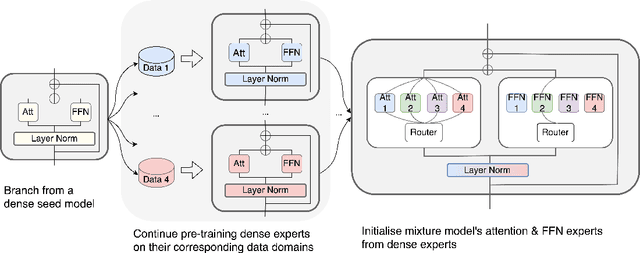
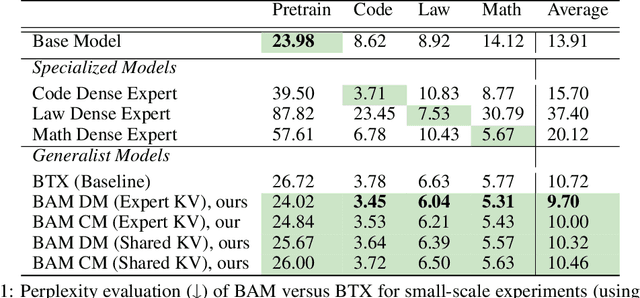
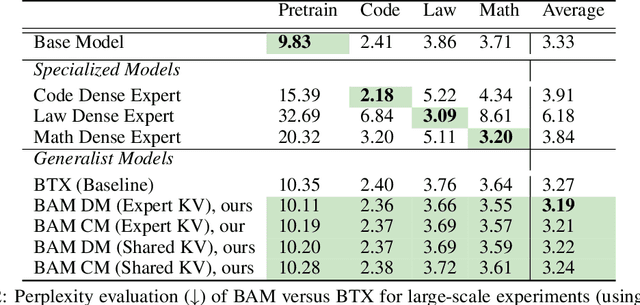
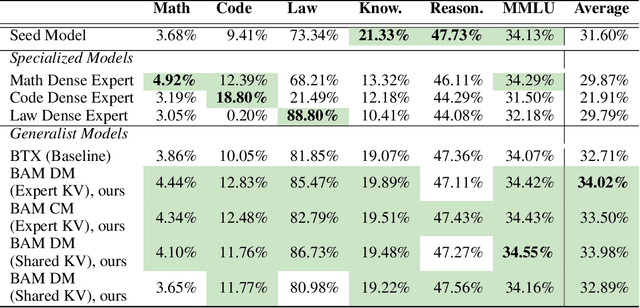
The Mixture of Experts (MoE) framework has become a popular architecture for large language models due to its superior performance over dense models. However, training MoEs from scratch in a large-scale regime is prohibitively expensive. Existing methods mitigate this by pre-training multiple dense expert models independently and using them to initialize an MoE. This is done by using experts' feed-forward network (FFN) to initialize the MoE's experts while merging other parameters. However, this method limits the reuse of dense model parameters to only the FFN layers, thereby constraining the advantages when "upcycling" these models into MoEs. We propose BAM (Branch-Attend-Mix), a simple yet effective method that addresses this shortcoming. BAM makes full use of specialized dense models by not only using their FFN to initialize the MoE layers but also leveraging experts' attention parameters fully by initializing them into a soft-variant of Mixture of Attention (MoA) layers. We explore two methods for upcycling attention parameters: 1) initializing separate attention experts from dense models including all attention parameters for the best model performance; and 2) sharing key and value parameters across all experts to facilitate for better inference efficiency. To further improve efficiency, we adopt a parallel attention transformer architecture to MoEs, which allows the attention experts and FFN experts to be computed concurrently. Our experiments on seed models ranging from 590 million to 2 billion parameters demonstrate that BAM surpasses baselines in both perplexity and downstream task performance, within the same computational and data constraints.
How Does Quantization Affect Multilingual LLMs?
Jul 03, 2024Quantization techniques are widely used to improve inference speed and deployment of large language models. While a wide body of work examines the impact of quantized LLMs on English tasks, none have examined the effect of quantization across languages. We conduct a thorough analysis of quantized multilingual LLMs, focusing on their performance across languages and at varying scales. We use automatic benchmarks, LLM-as-a-Judge methods, and human evaluation, finding that (1) harmful effects of quantization are apparent in human evaluation, and automatic metrics severely underestimate the detriment: a 1.7% average drop in Japanese across automatic tasks corresponds to a 16.0% drop reported by human evaluators on realistic prompts; (2) languages are disparately affected by quantization, with non-Latin script languages impacted worst; and (3) challenging tasks such as mathematical reasoning degrade fastest. As the ability to serve low-compute models is critical for wide global adoption of NLP technologies, our results urge consideration of multilingual performance as a key evaluation criterion for efficient models.