 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Nexus: Specialization meets Adaptability for Efficiently Training Mixture of Experts
Aug 28, 2024



Efficiency, specialization, and adaptability to new data distributions are qualities that are hard to combine in current Large Language Models. The Mixture of Experts (MoE) architecture has been the focus of significant research because its inherent conditional computation enables such desirable properties. In this work, we focus on "upcycling" dense expert models into an MoE, aiming to improve specialization while also adding the ability to adapt to new tasks easily. We introduce Nexus, an enhanced MoE architecture with adaptive routing where the model learns to project expert embeddings from domain representations. This approach allows Nexus to flexibly add new experts after the initial upcycling through separately trained dense models, without requiring large-scale MoE training for unseen data domains. Our experiments show that Nexus achieves a relative gain of up to 2.1% over the baseline for initial upcycling, and a 18.8% relative gain for extending the MoE with a new expert by using limited finetuning data. This flexibility of Nexus is crucial to enable an open-source ecosystem where every user continuously assembles their own MoE-mix according to their needs.
BAM! Just Like That: Simple and Efficient Parameter Upcycling for Mixture of Experts
Aug 15, 2024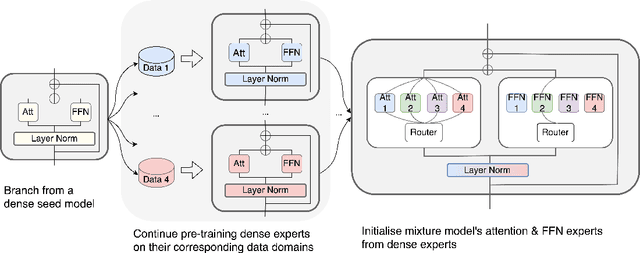
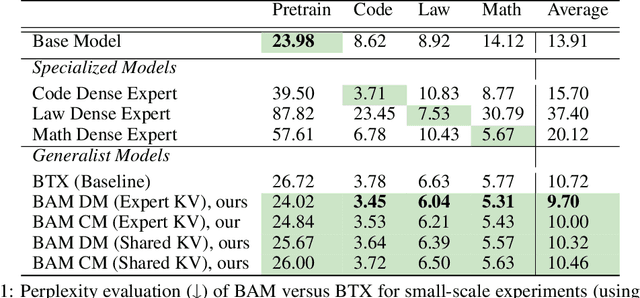
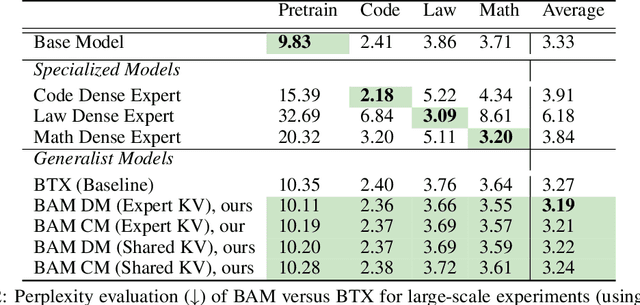
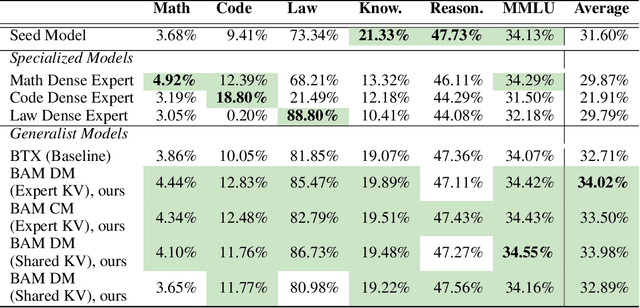
The Mixture of Experts (MoE) framework has become a popular architecture for large language models due to its superior performance over dense models. However, training MoEs from scratch in a large-scale regime is prohibitively expensive. Existing methods mitigate this by pre-training multiple dense expert models independently and using them to initialize an MoE. This is done by using experts' feed-forward network (FFN) to initialize the MoE's experts while merging other parameters. However, this method limits the reuse of dense model parameters to only the FFN layers, thereby constraining the advantages when "upcycling" these models into MoEs. We propose BAM (Branch-Attend-Mix), a simple yet effective method that addresses this shortcoming. BAM makes full use of specialized dense models by not only using their FFN to initialize the MoE layers but also leveraging experts' attention parameters fully by initializing them into a soft-variant of Mixture of Attention (MoA) layers. We explore two methods for upcycling attention parameters: 1) initializing separate attention experts from dense models including all attention parameters for the best model performance; and 2) sharing key and value parameters across all experts to facilitate for better inference efficiency. To further improve efficiency, we adopt a parallel attention transformer architecture to MoEs, which allows the attention experts and FFN experts to be computed concurrently. Our experiments on seed models ranging from 590 million to 2 billion parameters demonstrate that BAM surpasses baselines in both perplexity and downstream task performance, within the same computational and data constraints.
Divergent Token Metrics: Measuring degradation to prune away LLM components -- and optimize quantization
Nov 13, 2023Large Language Models (LLMs) have reshaped natural language processing with their impressive capabilities. Their ever-increasing size, however, raised concerns about their effective deployment and the need for LLM compressions. This study introduces the Divergent Token metrics (DTMs), a novel approach for assessing compressed LLMs, addressing the limitations of traditional perplexity or accuracy measures that fail to accurately reflect text generation quality. DTMs focus on token divergence, that allow deeper insights into the subtleties of model compression, i.p. when evaluating component's impacts individually. Utilizing the First Divergent Token metric (FDTM) in model sparsification reveals that a quarter of all attention components can be pruned beyond 90% on the Llama-2 model family, still keeping SOTA performance. For quantization FDTM suggests that over 80% of parameters can naively be transformed to int8 without special outlier management. These evaluations indicate the necessity of choosing appropriate compressions for parameters individually-and that FDTM can identify those-while standard metrics result in deteriorated outcomes.