 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Noisy Data and LLM Pretraining Loss Divergence
Feb 02, 2026Large-scale pretraining datasets drive the success of large language models (LLMs). However, these web-scale corpora inevitably contain large amounts of noisy data due to unregulated web content or randomness inherent in data. Although LLM pretrainers often speculate that such noise contributes to instabilities in large-scale LLM pretraining and, in the worst cases, loss divergence, this phenomenon remains poorly understood.In this work, we present a systematic empirical study of whether noisy data causes LLM pretraining divergences and how it does so. By injecting controlled synthetic uniformly random noise into otherwise clean datasets, we analyze training dynamics across model sizes ranging from 480M to 5.2B parameters. We show that noisy data indeed induces training loss divergence, and that the probability of divergence depends strongly on the noise type, amount of noise, and model scale. We further find that noise-induced divergences exhibit activation patterns distinct from those caused by high learning rates, and we provide diagnostics that differentiate these two failure modes. Together, these results provide a large-scale, controlled characterization of how noisy data affects loss divergence in LLM pretraining.
An Empirical Study of the Impact of Federated Learning on Machine Learning Model Accuracy
Mar 27, 2025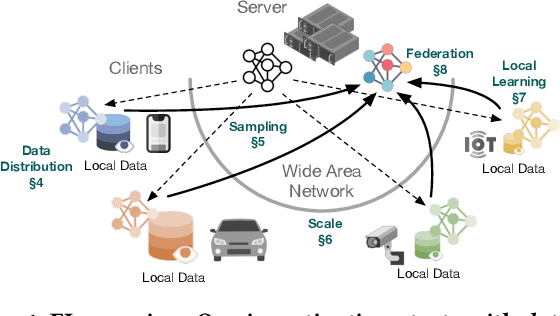
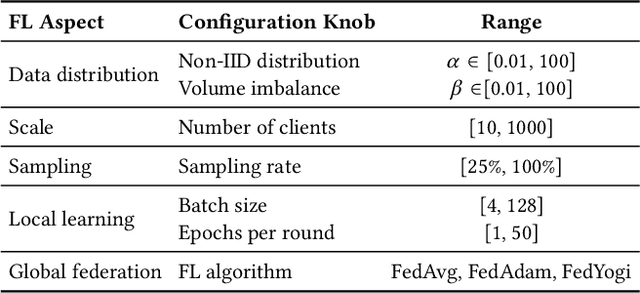

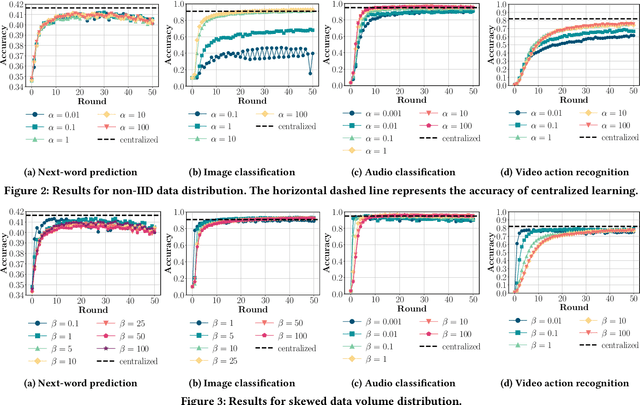
Federated Learning (FL) enables distributed ML model training on private user data at the global scale. Despite the potential of FL demonstrated in many domains, an in-depth view of its impact on model accuracy remains unclear. In this paper, we investigate, systematically, how this learning paradigm can affect the accuracy of state-of-the-art ML models for a variety of ML tasks. We present an empirical study that involves various data types: text, image, audio, and video, and FL configuration knobs: data distribution, FL scale, client sampling, and local and global computations. Our experiments are conducted in a unified FL framework to achieve high fidelity, with substantial human efforts and resource investments. Based on the results, we perform a quantitative analysis of the impact of FL, and highlight challenging scenarios where applying FL degrades the accuracy of the model drastically and identify cases where the impact is negligible. The detailed and extensive findings can benefit practical deployments and future development of FL.
Nexus: Specialization meets Adaptability for Efficiently Training Mixture of Experts
Aug 28, 2024



Efficiency, specialization, and adaptability to new data distributions are qualities that are hard to combine in current Large Language Models. The Mixture of Experts (MoE) architecture has been the focus of significant research because its inherent conditional computation enables such desirable properties. In this work, we focus on "upcycling" dense expert models into an MoE, aiming to improve specialization while also adding the ability to adapt to new tasks easily. We introduce Nexus, an enhanced MoE architecture with adaptive routing where the model learns to project expert embeddings from domain representations. This approach allows Nexus to flexibly add new experts after the initial upcycling through separately trained dense models, without requiring large-scale MoE training for unseen data domains. Our experiments show that Nexus achieves a relative gain of up to 2.1% over the baseline for initial upcycling, and a 18.8% relative gain for extending the MoE with a new expert by using limited finetuning data. This flexibility of Nexus is crucial to enable an open-source ecosystem where every user continuously assembles their own MoE-mix according to their needs.
BAM! Just Like That: Simple and Efficient Parameter Upcycling for Mixture of Experts
Aug 15, 2024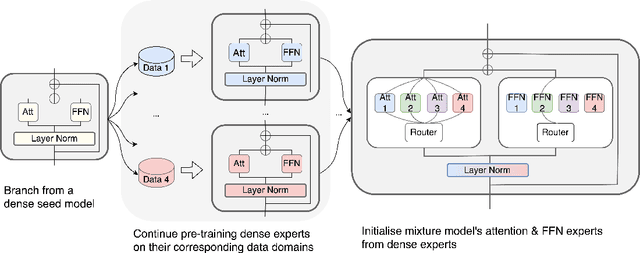
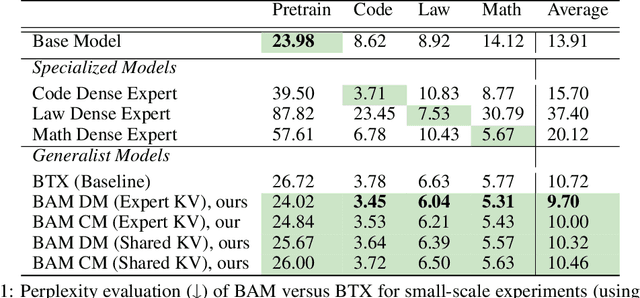
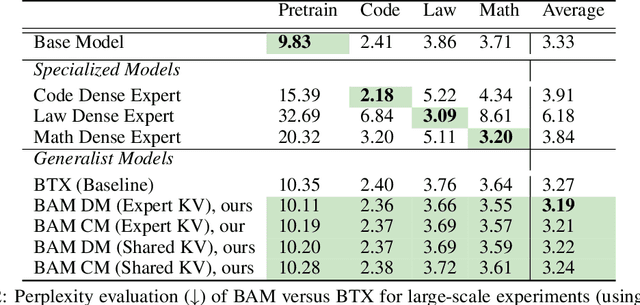
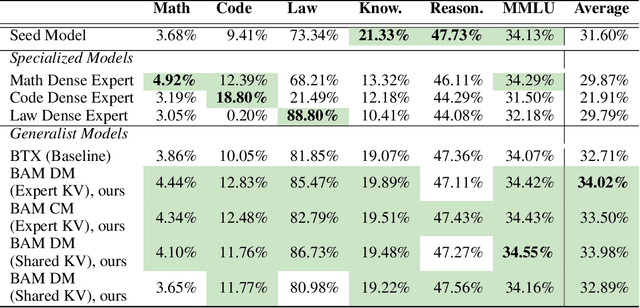
The Mixture of Experts (MoE) framework has become a popular architecture for large language models due to its superior performance over dense models. However, training MoEs from scratch in a large-scale regime is prohibitively expensive. Existing methods mitigate this by pre-training multiple dense expert models independently and using them to initialize an MoE. This is done by using experts' feed-forward network (FFN) to initialize the MoE's experts while merging other parameters. However, this method limits the reuse of dense model parameters to only the FFN layers, thereby constraining the advantages when "upcycling" these models into MoEs. We propose BAM (Branch-Attend-Mix), a simple yet effective method that addresses this shortcoming. BAM makes full use of specialized dense models by not only using their FFN to initialize the MoE layers but also leveraging experts' attention parameters fully by initializing them into a soft-variant of Mixture of Attention (MoA) layers. We explore two methods for upcycling attention parameters: 1) initializing separate attention experts from dense models including all attention parameters for the best model performance; and 2) sharing key and value parameters across all experts to facilitate for better inference efficiency. To further improve efficiency, we adopt a parallel attention transformer architecture to MoEs, which allows the attention experts and FFN experts to be computed concurrently. Our experiments on seed models ranging from 590 million to 2 billion parameters demonstrate that BAM surpasses baselines in both perplexity and downstream task performance, within the same computational and data constraints.
PARDEN, Can You Repeat That? Defending against Jailbreaks via Repetition
May 14, 2024Large language models (LLMs) have shown success in many natural language processing tasks. Despite rigorous safety alignment processes, supposedly safety-aligned LLMs like Llama 2 and Claude 2 are still susceptible to jailbreaks, leading to security risks and abuse of the models. One option to mitigate such risks is to augment the LLM with a dedicated "safeguard", which checks the LLM's inputs or outputs for undesired behaviour. A promising approach is to use the LLM itself as the safeguard. Nonetheless, baseline methods, such as prompting the LLM to self-classify toxic content, demonstrate limited efficacy. We hypothesise that this is due to domain shift: the alignment training imparts a self-censoring behaviour to the model ("Sorry I can't do that"), while the self-classify approach shifts it to a classification format ("Is this prompt malicious"). In this work, we propose PARDEN, which avoids this domain shift by simply asking the model to repeat its own outputs. PARDEN neither requires finetuning nor white box access to the model. We empirically verify the effectiveness of our method and show that PARDEN significantly outperforms existing jailbreak detection baselines for Llama-2 and Claude-2. Code and data are available at https://github.com/Ed-Zh/PARDEN. We find that PARDEN is particularly powerful in the relevant regime of high True Positive Rate (TPR) and low False Positive Rate (FPR). For instance, for Llama2-7B, at TPR equal to 90%, PARDEN accomplishes a roughly 11x reduction in the FPR from 24.8% to 2.0% on the harmful behaviours dataset.
Analysing the Sample Complexity of Opponent Shaping
Feb 08, 2024



Learning in general-sum games often yields collectively sub-optimal results. Addressing this, opponent shaping (OS) methods actively guide the learning processes of other agents, empirically leading to improved individual and group performances in many settings. Early OS methods use higher-order derivatives to shape the learning of co-players, making them unsuitable for shaping multiple learning steps. Follow-up work, Model-free Opponent Shaping (M-FOS), addresses these by reframing the OS problem as a meta-game. In contrast to early OS methods, there is little theoretical understanding of the M-FOS framework. Providing theoretical guarantees for M-FOS is hard because A) there is little literature on theoretical sample complexity bounds for meta-reinforcement learning B) M-FOS operates in continuous state and action spaces, so theoretical analysis is challenging. In this work, we present R-FOS, a tabular version of M-FOS that is more suitable for theoretical analysis. R-FOS discretises the continuous meta-game MDP into a tabular MDP. Within this discretised MDP, we adapt the $R_{max}$ algorithm, most prominently used to derive PAC-bounds for MDPs, as the meta-learner in the R-FOS algorithm. We derive a sample complexity bound that is exponential in the cardinality of the inner state and action space and the number of agents. Our bound guarantees that, with high probability, the final policy learned by an R-FOS agent is close to the optimal policy, apart from a constant factor. Finally, we investigate how R-FOS's sample complexity scales in the size of state-action space. Our theoretical results on scaling are supported empirically in the Matching Pennies environment.
Computing in the Era of Large Generative Models: From Cloud-Native to AI-Native
Jan 17, 2024

In this paper, we investigate the intersection of large generative AI models and cloud-native computing architectures. Recent large models such as ChatGPT, while revolutionary in their capabilities, face challenges like escalating costs and demand for high-end GPUs. Drawing analogies between large-model-as-a-service (LMaaS) and cloud database-as-a-service (DBaaS), we describe an AI-native computing paradigm that harnesses the power of both cloud-native technologies (e.g., multi-tenancy and serverless computing) and advanced machine learning runtime (e.g., batched LoRA inference). These joint efforts aim to optimize costs-of-goods-sold (COGS) and improve resource accessibility. The journey of merging these two domains is just at the beginning and we hope to stimulate future research and development in this area.
Centralized Model and Exploration Policy for Multi-Agent RL
Jul 14, 2021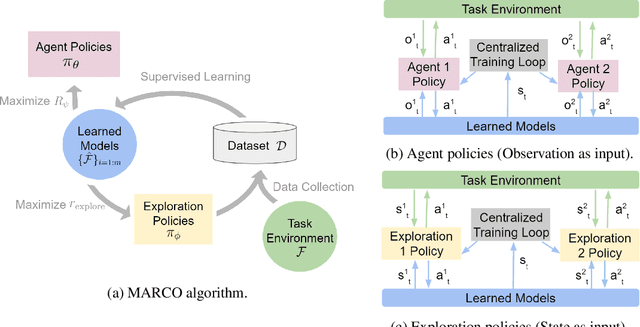
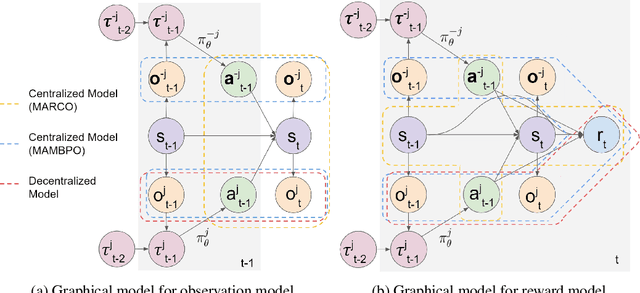
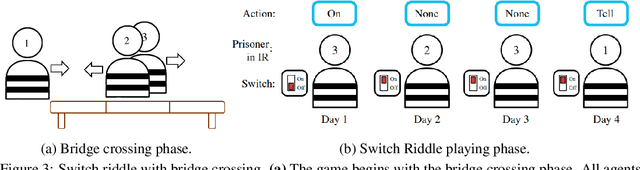
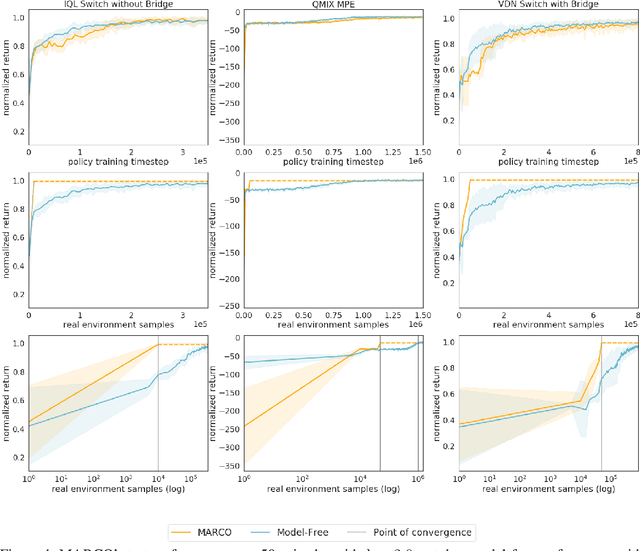
Reinforcement learning (RL) in partially observable, fully cooperative multi-agent settings (Dec-POMDPs) can in principle be used to address many real-world challenges such as controlling a swarm of rescue robots or a synchronous team of quadcopters. However, Dec-POMDPs are significantly harder to solve than single-agent problems, with the former being NEXP-complete and the latter, MDPs, being just P-complete. Hence, current RL algorithms for Dec-POMDPs suffer from poor sample complexity, thereby reducing their applicability to practical problems where environment interaction is costly. Our key insight is that using just a polynomial number of samples, one can learn a centralized model that generalizes across different policies. We can then optimize the policy within the learned model instead of the true system, reducing the number of environment interactions. We also learn a centralized exploration policy within our model that learns to collect additional data in state-action regions with high model uncertainty. Finally, we empirically evaluate the proposed model-based algorithm, MARCO, in three cooperative communication tasks, where it improves sample efficiency by up to 20x.