 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of the Impact of Federated Learning on Machine Learning Model Accuracy
Mar 27, 2025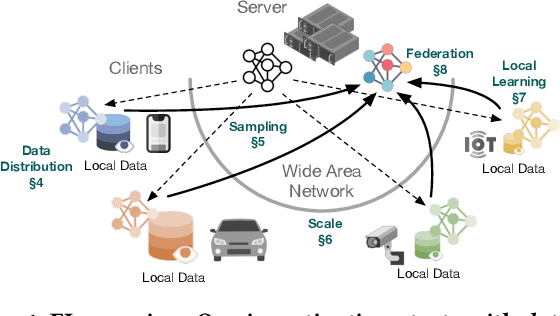
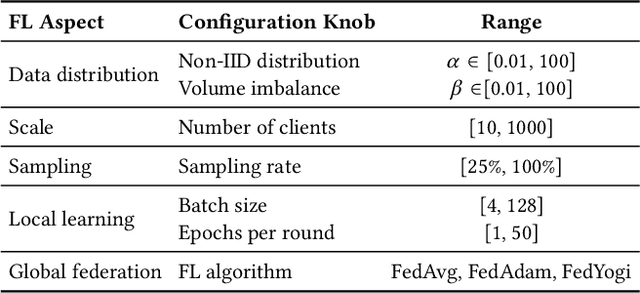

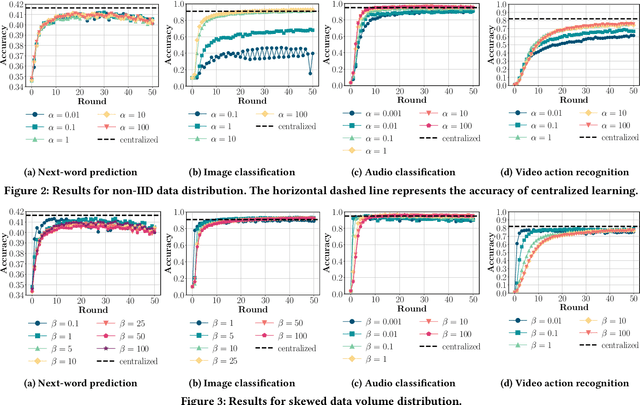
Federated Learning (FL) enables distributed ML model training on private user data at the global scale. Despite the potential of FL demonstrated in many domains, an in-depth view of its impact on model accuracy remains unclear. In this paper, we investigate, systematically, how this learning paradigm can affect the accuracy of state-of-the-art ML models for a variety of ML tasks. We present an empirical study that involves various data types: text, image, audio, and video, and FL configuration knobs: data distribution, FL scale, client sampling, and local and global computations. Our experiments are conducted in a unified FL framework to achieve high fidelity, with substantial human efforts and resource investments. Based on the results, we perform a quantitative analysis of the impact of FL, and highlight challenging scenarios where applying FL degrades the accuracy of the model drastically and identify cases where the impact is negligible. The detailed and extensive findings can benefit practical deployments and future development of FL.
A tutorial on fairness in machine learning in healthcare
Jun 15, 2024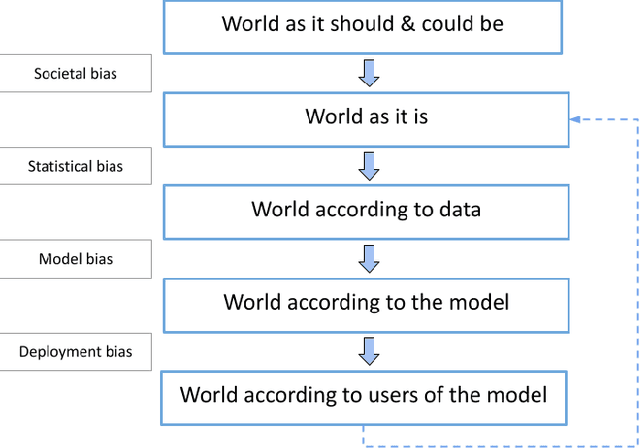
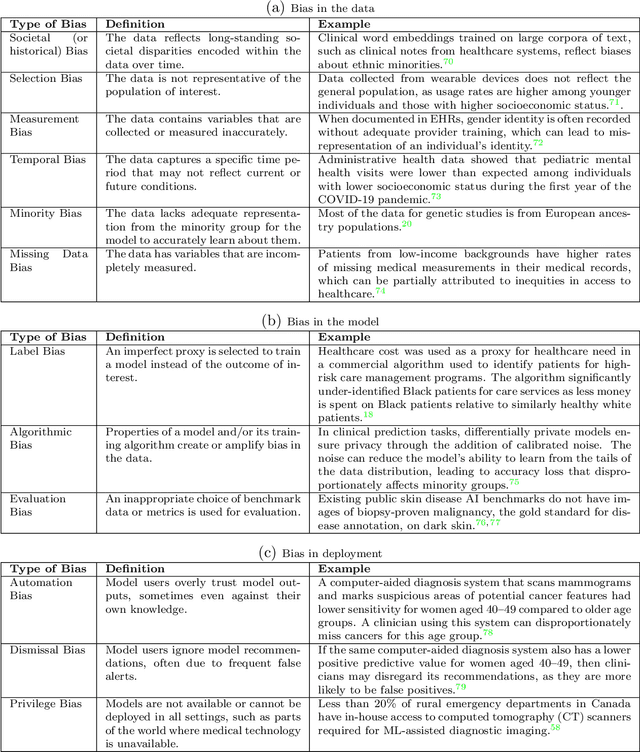
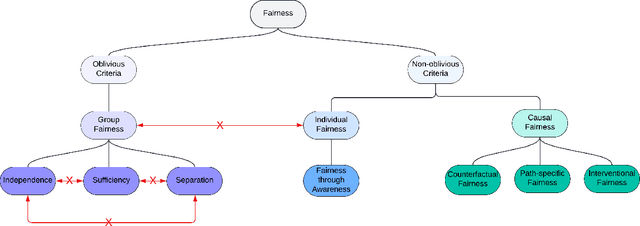
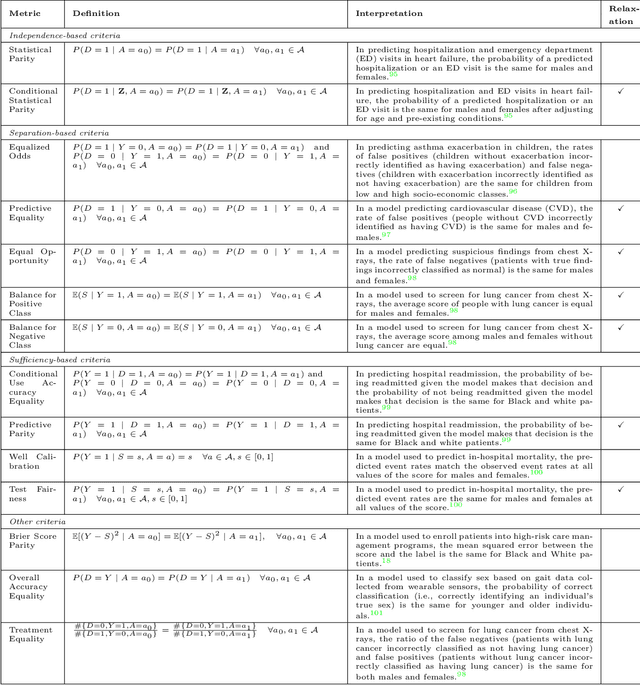
$\textbf{OBJECTIVE}$: Ensuring that machine learning (ML) algorithms are safe and effective within all patient groups, and do not disadvantage particular patients, is essential to clinical decision making and preventing the reinforcement of existing healthcare inequities. The objective of this tutorial is to introduce the medical informatics community to the common notions of fairness within ML, focusing on clinical applications and implementation in practice. $\textbf{TARGET AUDIENCE}$: As gaps in fairness arise in a variety of healthcare applications, this tutorial is designed to provide an understanding of fairness, without assuming prior knowledge, to researchers and clinicians who make use of modern clinical data. $\textbf{SCOPE}$: We describe the fundamental concepts and methods used to define fairness in ML, including an overview of why models in healthcare may be unfair, a summary and comparison of the metrics used to quantify fairness, and a discussion of some ongoing research. We illustrate some of the fairness methods introduced through a case study of mortality prediction in a publicly available electronic health record dataset. Finally, we provide a user-friendly R package for comprehensive group fairness evaluation, enabling researchers and clinicians to assess fairness in their own ML work.