 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of the Impact of Federated Learning on Machine Learning Model Accuracy
Mar 27, 2025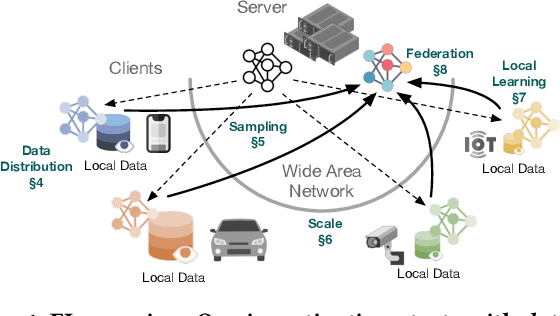
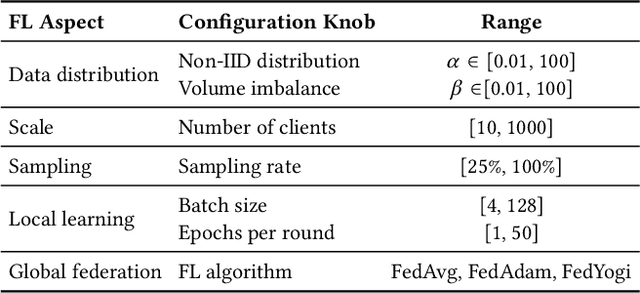

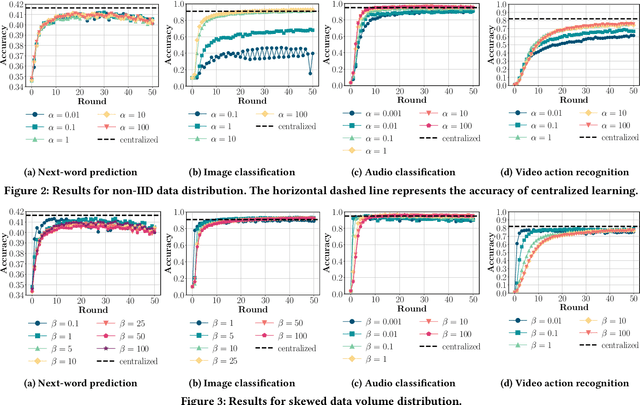
Federated Learning (FL) enables distributed ML model training on private user data at the global scale. Despite the potential of FL demonstrated in many domains, an in-depth view of its impact on model accuracy remains unclear. In this paper, we investigate, systematically, how this learning paradigm can affect the accuracy of state-of-the-art ML models for a variety of ML tasks. We present an empirical study that involves various data types: text, image, audio, and video, and FL configuration knobs: data distribution, FL scale, client sampling, and local and global computations. Our experiments are conducted in a unified FL framework to achieve high fidelity, with substantial human efforts and resource investments. Based on the results, we perform a quantitative analysis of the impact of FL, and highlight challenging scenarios where applying FL degrades the accuracy of the model drastically and identify cases where the impact is negligible. The detailed and extensive findings can benefit practical deployments and future development of FL.