 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Tesserae: Scalable Placement Policies for Deep Learning Workloads
Aug 07, 2025Training deep learning (DL) models has become a dominant workload in data-centers and improving resource utilization is a key goal of DL cluster schedulers. In order to do this, schedulers typically incorporate placement policies that govern where jobs are placed on the cluster. Existing placement policies are either designed as ad-hoc heuristics or incorporated as constraints within a complex optimization problem and thus either suffer from suboptimal performance or poor scalability. Our key insight is that many placement constraints can be formulated as graph matching problems and based on that we design novel placement policies for minimizing job migration overheads and job packing. We integrate these policies into Tesserae and describe how our design leads to a scalable and effective GPU cluster scheduler. Our experimental results show that Tesserae improves average JCT by up to 1.62x and the Makespan by up to 1.15x compared with the existing schedulers.
Scaling Inference-Efficient Language Models
Jan 30, 2025



Scaling laws are powerful tools to predict the performance of large language models. However, current scaling laws fall short of accounting for inference costs. In this work, we first show that model architecture affects inference latency, where models of the same size can have up to 3.5x difference in latency. To tackle this challenge, we modify the Chinchilla scaling laws to co-optimize the model parameter count, the number of training tokens, and the model architecture. Due to the reason that models of similar training loss exhibit gaps in downstream evaluation, we also propose a novel method to train inference-efficient models based on the revised scaling laws. We perform extensive empirical studies to fit and evaluate our inference-aware scaling laws. We vary model parameters from 80M to 1B, training tokens from 1.6B to 30B, and model shapes, training a total of 63 models. Guided by our inference-efficient scaling law and model selection method, we release the Morph-1B model, which improves inference latency by 1.8x while maintaining accuracy on downstream tasks compared to open-source models, pushing the Pareto frontier of accuracy-latency tradeoff.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Computing in the Era of Large Generative Models: From Cloud-Native to AI-Native
Jan 17, 2024

In this paper, we investigate the intersection of large generative AI models and cloud-native computing architectures. Recent large models such as ChatGPT, while revolutionary in their capabilities, face challenges like escalating costs and demand for high-end GPUs. Drawing analogies between large-model-as-a-service (LMaaS) and cloud database-as-a-service (DBaaS), we describe an AI-native computing paradigm that harnesses the power of both cloud-native technologies (e.g., multi-tenancy and serverless computing) and advanced machine learning runtime (e.g., batched LoRA inference). These joint efforts aim to optimize costs-of-goods-sold (COGS) and improve resource accessibility. The journey of merging these two domains is just at the beginning and we hope to stimulate future research and development in this area.
Federated Empirical Risk Minimization via Second-Order Method
May 27, 2023Many convex optimization problems with important applications in machine learning are formulated as empirical risk minimization (ERM). There are several examples: linear and logistic regression, LASSO, kernel regression, quantile regression, $p$-norm regression, support vector machines (SVM), and mean-field variational inference. To improve data privacy, federated learning is proposed in machine learning as a framework for training deep learning models on the network edge without sharing data between participating nodes. In this work, we present an interior point method (IPM) to solve a general ERM problem under the federated learning setting. We show that the communication complexity of each iteration of our IPM is $\tilde{O}(d^{3/2})$, where $d$ is the dimension (i.e., number of features) of the dataset.
Certifiable Robustness for Naive Bayes Classifiers
Mar 08, 2023Data cleaning is crucial but often laborious in most machine learning (ML) applications. However, task-agnostic data cleaning is sometimes unnecessary if certain inconsistencies in the dirty data will not affect the prediction of ML models to the test points. A test point is certifiably robust for an ML classifier if the prediction remains the same regardless of which (among exponentially many) cleaned dataset it is trained on. In this paper, we study certifiable robustness for the Naive Bayes classifier (NBC) on dirty datasets with missing values. We present (i) a linear time algorithm in the number of entries in the dataset that decides whether a test point is certifiably robust for NBC, (ii) an algorithm that counts for each label, the number of cleaned datasets on which the NBC can be trained to predict that label, and (iii) an efficient optimal algorithm that poisons a clean dataset by inserting the minimum number of missing values such that a test point is not certifiably robust for NBC. We prove that (iv) poisoning a clean dataset such that multiple test points become certifiably non-robust is NP-hard for any dataset with at least three features. Our experiments demonstrate that our algorithms for the decision and data poisoning problems achieve up to $19.5\times$ and $3.06\times$ speed-up over the baseline algorithms across different real-world datasets.
Does compressing activations help model parallel training?
Jan 06, 2023Large-scale Transformer models are known for their exceptional performance in a range of tasks, but training them can be difficult due to the requirement for communication-intensive model parallelism. One way to improve training speed is to compress the message size in communication. Previous approaches have primarily focused on compressing gradients in a data parallelism setting, but compression in a model-parallel setting is an understudied area. We have discovered that model parallelism has fundamentally different characteristics than data parallelism. In this work, we present the first empirical study on the effectiveness of compression methods for model parallelism. We implement and evaluate three common classes of compression algorithms - pruning-based, learning-based, and quantization-based - using a popular Transformer training framework. We evaluate these methods across more than 160 settings and 8 popular datasets, taking into account different hyperparameters, hardware, and both fine-tuning and pre-training stages. We also provide analysis when the model is scaled up. Finally, we provide insights for future development of model parallelism compression algorithms.
FedNNNN: Norm-Normalized Neural Network Aggregation for Fast and Accurate Federated Learning
Aug 11, 2020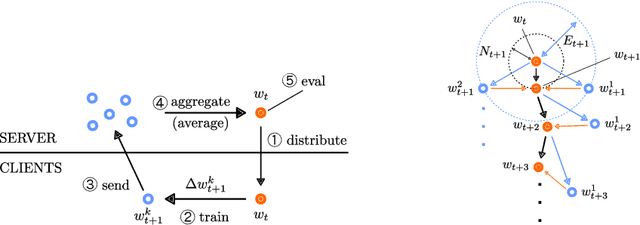
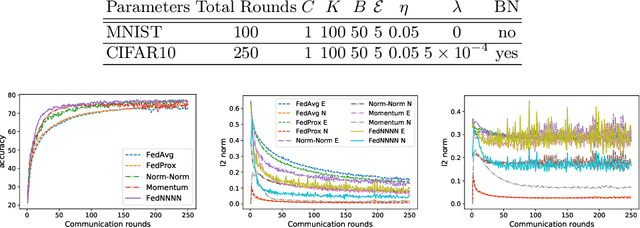
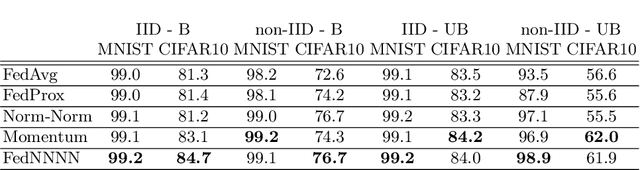
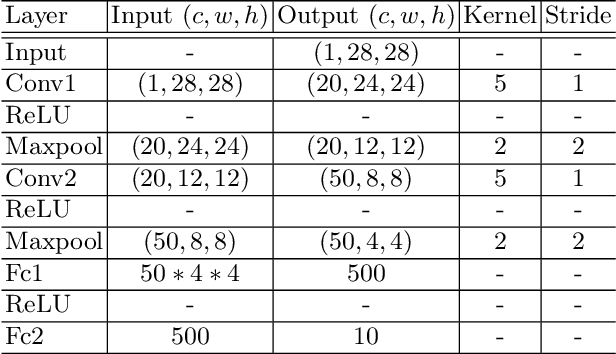
Federated learning (FL) is a distributed learning protocol in which a server needs to aggregate a set of models learned some independent clients to proceed the learning process. At present, model averaging, known as FedAvg, is one of the most widely adapted aggregation techniques. However, it is known to yield the models with degraded prediction accuracy and slow convergence. In this work, we find out that averaging models from different clients significantly diminishes the norm of the update vectors, resulting in slow learning rate and low prediction accuracy. Therefore, we propose a new aggregation method called FedNNNN. Instead of simple model averaging, we adjust the norm of the update vector and introduce momentum control techniques to improve the aggregation effectiveness of FL. As a demonstration, we evaluate FedNNNN on multiple datasets and scenarios with different neural network models, and observe up to 5.4% accuracy improvement.
BUNET: Blind Medical Image Segmentation Based on Secure UNET
Jul 14, 2020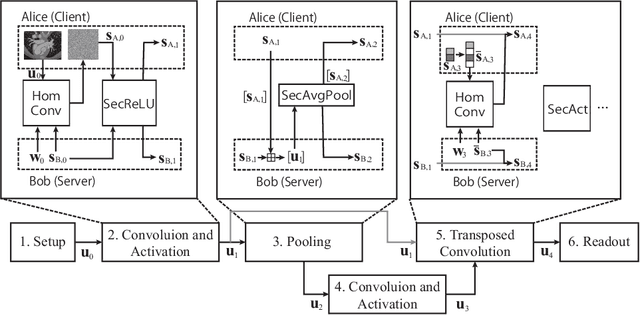
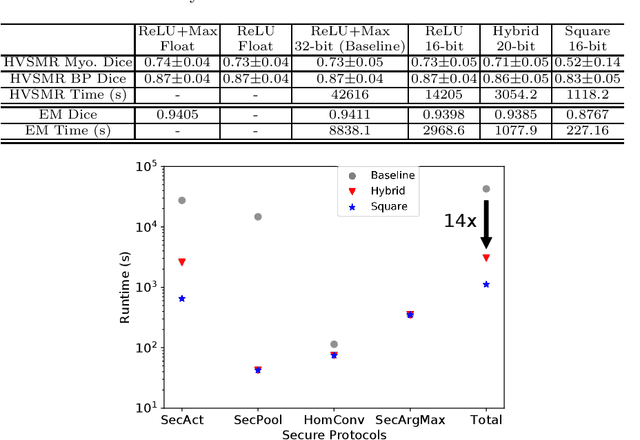
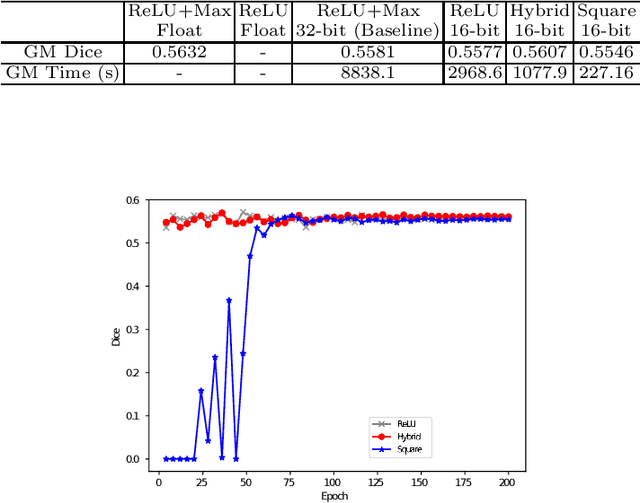
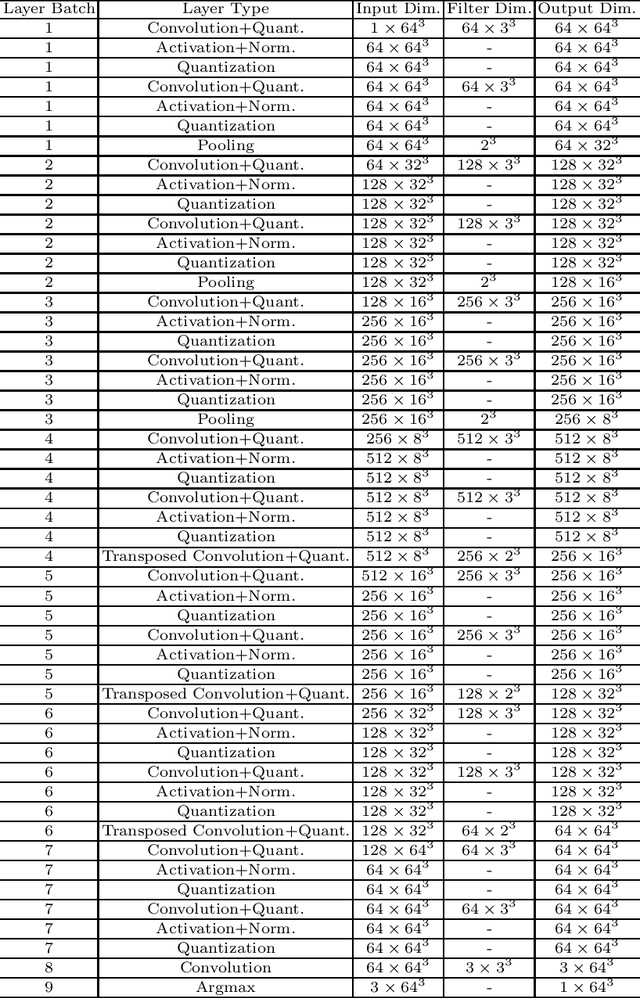
The strict security requirements placed on medical records by various privacy regulations become major obstacles in the age of big data. To ensure efficient machine learning as a service schemes while protecting data confidentiality, in this work, we propose blind UNET (BUNET), a secure protocol that implements privacy-preserving medical image segmentation based on the UNET architecture. In BUNET, we efficiently utilize cryptographic primitives such as homomorphic encryption and garbled circuits (GC) to design a complete secure protocol for the UNET neural architecture. In addition, we perform extensive architectural search in reducing the computational bottleneck of GC-based secure activation protocols with high-dimensional input data. In the experiment, we thoroughly examine the parameter space of our protocol, and show that we can achieve up to 14x inference time reduction compared to the-state-of-the-art secure inference technique on a baseline architecture with negligible accuracy degradation.