 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVikingMem: A Memory Base Management System for Stateful LLM-based Applications
May 28, 2026Large Language Models have revolutionized interactive applications; however, their finite context windows pose a critical data management challenge for maintaining stateful, long-term interactions. Existing memory approaches often rely on simplistic extraction methods that lead to incomplete memories or use rigid, single-purpose memory extraction prompts tailored to a single use case, such as chatbots. Consequently, they lack generalizability and perform poorly across diverse downstream tasks. To bridge this gap, we introduce the Memory Base, a novel data management paradigm for managing the persistent state of long-term interactions. It is characterized by three core principles: selective extraction of high-value memories from raw information streams; inherent statefulness and evolution, where memory content is progressively summarized, corrected, and temporally weighted to prioritize recent interactions; and a generalizable abstraction paradigm designed for robust transferability across diverse applications, including education, recommendation, and agent memory. Building on this foundation, we present VikingMem, an end-to-end Memory Base Management System implemented on the VikingDB vector engine. VikingMem materializes this paradigm through interconnected event and entity abstractions. It features event-centric memory extraction to selectively handle complex information streams, while entities are dynamically updated by events to achieve stateful evolution. Using temporal compression via a topic-wise timeline and time-weighted recall, the system progressively produces high-level summary memories, prioritizes recent items, and compresses and fades older ones. Extensive evaluations on long-term memory benchmarks demonstrate that VikingMem outperformes baselines by up to 30% in memory retrieval effectiveness while maintaining the low latency essential for interactive applications.
Unbiased Multimodal Reranking for Long-Tail Short-Video Search
Mar 26, 2026Kuaishou serving hundreds of millions of searches daily, the quality of short-video search is paramount. However, it suffers from a severe Matthew effect on long-tail queries: sparse user behavior data causes models to amplify low-quality content such as clickbait and shallow content. The recent advancements in Large Language Models (LLMs) offer a new paradigm, as their inherent world knowledge provides a powerful mechanism to assess content quality, agnostic to sparse user interactions. To this end, we propose a LLM-driven multimodal reranking framework, which estimates user experience without real user behavior. The approach involves a two-stage training process: the first stage uses multimodal evidence to construct high-quality annotations for supervised fine-tuning, while the second stage incorporates pairwise preference optimization to help the model learn partial orderings among candidates. At inference time, the resulting experience scores are used to promote high-quality but underexposed videos in reranking, and further guide page-level optimization through reinforcement learning. Experiments show that the proposed method achieves consistent improvements over strong baselines in offline metrics including AUC, NDCG@K, and human preference judgement. An online A/B test covering 15\% of traffic further demonstrates gains in both user experience and consumption metrics, confirming the practical value of the approach in long-tail video search scenarios.
OpenHospital: A Thing-in-itself Arena for Evolving and Benchmarking LLM-based Collective Intelligence
Mar 17, 2026Large Language Model (LLM)-based Collective Intelligence (CI) presents a promising approach to overcoming the data wall and continuously boosting the capabilities of LLM agents. However, there is currently no dedicated arena for evolving and benchmarking LLM-based CI. To address this gap, we introduce OpenHospital, an interactive arena where physician agents can evolve CI through interactions with patient agents. This arena employs a data-in-agent-self paradigm that rapidly enhances agent capabilities and provides robust evaluation metrics for benchmarking both medical proficiency and system efficiency. Experiments demonstrate the effectiveness of OpenHospital in both fostering and quantifying CI.
DTBench: A Synthetic Benchmark for Document-to-Table Extraction
Feb 17, 2026Document-to-table (Doc2Table) extraction derives structured tables from unstructured documents under a target schema, enabling reliable and verifiable SQL-based data analytics. Although large language models (LLMs) have shown promise in flexible information extraction, their ability to produce precisely structured tables remains insufficiently understood, particularly for indirect extraction that requires complex capabilities such as reasoning and conflict resolution. Existing benchmarks neither explicitly distinguish nor comprehensively cover the diverse capabilities required in Doc2Table extraction. We argue that a capability-aware benchmark is essential for systematic evaluation. However, constructing such benchmarks using human-annotated document-table pairs is costly, difficult to scale, and limited in capability coverage. To address this, we adopt a reverse Table2Doc paradigm and design a multi-agent synthesis workflow to generate documents from ground-truth tables. Based on this approach, we present DTBench, a synthetic benchmark that adopts a proposed two-level taxonomy of Doc2Table capabilities, covering 5 major categories and 13 subcategories. We evaluate several mainstream LLMs on DTBench, and demonstrate substantial performance gaps across models, as well as persistent challenges in reasoning, faithfulness, and conflict resolution. DTBench provides a comprehensive testbed for data generation and evaluation, facilitating future research on Doc2Table extraction. The benchmark is publicly available at https://github.com/ZJU-DAILY/DTBench.
Can We Predict Before Executing Machine Learning Agents?
Jan 09, 2026Autonomous machine learning agents have revolutionized scientific discovery, yet they remain constrained by a Generate-Execute-Feedback paradigm. Previous approaches suffer from a severe Execution Bottleneck, as hypothesis evaluation relies strictly on expensive physical execution. To bypass these physical constraints, we internalize execution priors to substitute costly runtime checks with instantaneous predictive reasoning, drawing inspiration from World Models. In this work, we formalize the task of Data-centric Solution Preference and construct a comprehensive corpus of 18,438 pairwise comparisons. We demonstrate that LLMs exhibit significant predictive capabilities when primed with a Verified Data Analysis Report, achieving 61.5% accuracy and robust confidence calibration. Finally, we instantiate this framework in FOREAGENT, an agent that employs a Predict-then-Verify loop, achieving a 6x acceleration in convergence while surpassing execution-based baselines by +6%. Our code and dataset will be publicly available soon at https://github.com/zjunlp/predict-before-execute.
VICTOR: Dataset Copyright Auditing in Video Recognition Systems
Dec 16, 2025Video recognition systems are increasingly being deployed in daily life, such as content recommendation and security monitoring. To enhance video recognition development, many institutions have released high-quality public datasets with open-source licenses for training advanced models. At the same time, these datasets are also susceptible to misuse and infringement. Dataset copyright auditing is an effective solution to identify such unauthorized use. However, existing dataset copyright solutions primarily focus on the image domain; the complex nature of video data leaves dataset copyright auditing in the video domain unexplored. Specifically, video data introduces an additional temporal dimension, which poses significant challenges to the effectiveness and stealthiness of existing methods. In this paper, we propose VICTOR, the first dataset copyright auditing approach for video recognition systems. We develop a general and stealthy sample modification strategy that enhances the output discrepancy of the target model. By modifying only a small proportion of samples (e.g., 1%), VICTOR amplifies the impact of published modified samples on the prediction behavior of the target models. Then, the difference in the model's behavior for published modified and unpublished original samples can serve as a key basis for dataset auditing. Extensive experiments on multiple models and datasets highlight the superiority of VICTOR. Finally, we show that VICTOR is robust in the presence of several perturbation mechanisms to the training videos or the target models.
Reveal Hidden Pitfalls and Navigate Next Generation of Vector Similarity Search from Task-Centric Views
Dec 15, 2025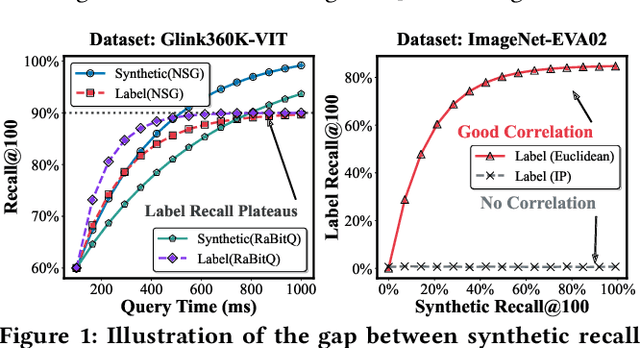

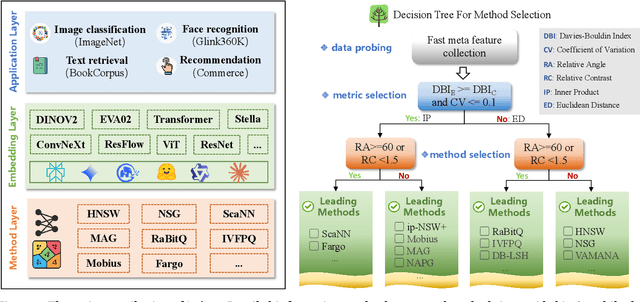
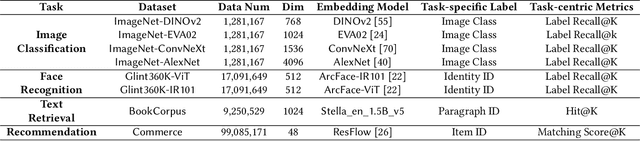
Vector Similarity Search (VSS) in high-dimensional spaces is rapidly emerging as core functionality in next-generation database systems for numerous data-intensive services -- from embedding lookups in large language models (LLMs), to semantic information retrieval and recommendation engines. Current benchmarks, however, evaluate VSS primarily on the recall-latency trade-off against a ground truth defined solely by distance metrics, neglecting how retrieval quality ultimately impacts downstream tasks. This disconnect can mislead both academic research and industrial practice. We present Iceberg, a holistic benchmark suite for end-to-end evaluation of VSS methods in realistic application contexts. From a task-centric view, Iceberg uncovers the Information Loss Funnel, which identifies three principal sources of end-to-end performance degradation: (1) Embedding Loss during feature extraction; (2) Metric Misuse, where distances poorly reflect task relevance; (3) Data Distribution Sensitivity, highlighting index robustness across skews and modalities. For a more comprehensive assessment, Iceberg spans eight diverse datasets across key domains such as image classification, face recognition, text retrieval, and recommendation systems. Each dataset, ranging from 1M to 100M vectors, includes rich, task-specific labels and evaluation metrics, enabling assessment of retrieval algorithms within the full application pipeline rather than in isolation. Iceberg benchmarks 13 state-of-the-art VSS methods and re-ranks them based on application-level metrics, revealing substantial deviations from traditional rankings derived purely from recall-latency evaluations. Building on these insights, we define a set of task-centric meta-features and derive an interpretable decision tree to guide practitioners in selecting and tuning VSS methods for their specific workloads.
Moon: A Modality Conversion-based Efficient Multivariate Time Series Anomaly Detection
Oct 02, 2025Multivariate time series (MTS) anomaly detection identifies abnormal patterns where each timestamp contains multiple variables. Existing MTS anomaly detection methods fall into three categories: reconstruction-based, prediction-based, and classifier-based methods. However, these methods face two key challenges: (1) Unsupervised learning methods, such as reconstruction-based and prediction-based methods, rely on error thresholds, which can lead to inaccuracies; (2) Semi-supervised methods mainly model normal data and often underuse anomaly labels, limiting detection of subtle anomalies;(3) Supervised learning methods, such as classifier-based approaches, often fail to capture local relationships, incur high computational costs, and are constrained by the scarcity of labeled data. To address these limitations, we propose Moon, a supervised modality conversion-based multivariate time series anomaly detection framework. Moon enhances the efficiency and accuracy of anomaly detection while providing detailed anomaly analysis reports. First, Moon introduces a novel multivariate Markov Transition Field (MV-MTF) technique to convert numeric time series data into image representations, capturing relationships across variables and timestamps. Since numeric data retains unique patterns that cannot be fully captured by image conversion alone, Moon employs a Multimodal-CNN to integrate numeric and image data through a feature fusion model with parameter sharing, enhancing training efficiency. Finally, a SHAP-based anomaly explainer identifies key variables contributing to anomalies, improving interpretability. Extensive experiments on six real-world MTS datasets demonstrate that Moon outperforms six state-of-the-art methods by up to 93% in efficiency, 4% in accuracy and, 10.8% in interpretation performance.
CLGNN: A Contrastive Learning-based GNN Model for Betweenness Centrality Prediction on Temporal Graphs
Jun 17, 2025Temporal Betweenness Centrality (TBC) measures how often a node appears on optimal temporal paths, reflecting its importance in temporal networks. However, exact computation is highly expensive, and real-world TBC distributions are extremely imbalanced. The severe imbalance leads learning-based models to overfit to zero-centrality nodes, resulting in inaccurate TBC predictions and failure to identify truly central nodes. Existing graph neural network (GNN) methods either fail to handle such imbalance or ignore temporal dependencies altogether. To address these issues, we propose a scalable and inductive contrastive learning-based GNN (CLGNN) for accurate and efficient TBC prediction. CLGNN builds an instance graph to preserve path validity and temporal order, then encodes structural and temporal features using dual aggregation, i.e., mean and edge-to-node multi-head attention mechanisms, enhanced by temporal path count and time encodings. A stability-based clustering-guided contrastive module (KContrastNet) is introduced to separate high-, median-, and low-centrality nodes in representation space, mitigating class imbalance, while a regression module (ValueNet) estimates TBC values. CLGNN also supports multiple optimal path definitions to accommodate diverse temporal semantics. Extensive experiments demonstrate the effectiveness and efficiency of CLGNN across diverse benchmarks. CLGNN achieves up to a 663.7~$\times$ speedup compared to state-of-the-art exact TBC computation methods. It outperforms leading static GNN baselines with up to 31.4~$\times$ lower MAE and 16.7~$\times$ higher Spearman correlation, and surpasses state-of-the-art temporal GNNs with up to 5.7~$\times$ lower MAE and 3.9~$\times$ higher Spearman correlation.
Causal Spatio-Temporal Prediction: An Effective and Efficient Multi-Modal Approach
May 23, 2025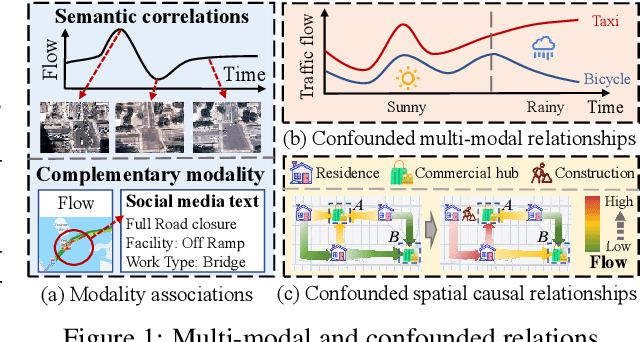



Spatio-temporal prediction plays a crucial role in intelligent transportation, weather forecasting, and urban planning. While integrating multi-modal data has shown potential for enhancing prediction accuracy, key challenges persist: (i) inadequate fusion of multi-modal information, (ii) confounding factors that obscure causal relations, and (iii) high computational complexity of prediction models. To address these challenges, we propose E^2-CSTP, an Effective and Efficient Causal multi-modal Spatio-Temporal Prediction framework. E^2-CSTP leverages cross-modal attention and gating mechanisms to effectively integrate multi-modal data. Building on this, we design a dual-branch causal inference approach: the primary branch focuses on spatio-temporal prediction, while the auxiliary branch mitigates bias by modeling additional modalities and applying causal interventions to uncover true causal dependencies. To improve model efficiency, we integrate GCN with the Mamba architecture for accelerated spatio-temporal encoding. Extensive experiments on 4 real-world datasets show that E^2-CSTP significantly outperforms 9 state-of-the-art methods, achieving up to 9.66% improvements in accuracy as well as 17.37%-56.11% reductions in computational overhead.