 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStellar: Scalable Multimodal Document Retrieval for Natural Language Queries
Jun 18, 2026Multimodal document retrieval--selecting the most relevant multimodal document from a large corpus to answer a natural language query--plays an essential role in Retrieval-Augmented Generation (RAG) systems. State-of-the-art methods represent each document and query with multiple token-level embeddings and use late interaction to achieve high effectiveness. However, such multi-vector representations incur substantial memory overhead during retrieval, leading to poor scalability and hindering real-world deployment. In this paper, we present Stellar, a scalable multimodal document retrieval framework that stores token-level document embeddings on disk and loads only a small set of candidate embeddings into memory for late interaction. Stellar comprises two key components: (i) Lexical Representation-based Filtering (LRF), which fine-tunes a Multimodal Large Language Model (MLLM) as a sparse encoder to produce high-quality lexical representations, enabling efficient and effective document filtering to significantly reduce the candidate set; (ii) Efficient Disk-backed Late Interaction (DLI), which designs an on-disk token embedding storage layout guided by a balanced clustering algorithm, and dynamically loads only the necessary token embeddings into memory using a simple yet effective cost model. Extensive experiments on four real-world benchmarks and a newly presented large-scale dataset demonstrate that Stellar reduces memory overhead and query latency by 1-2 orders of magnitude compared to existing methods without compromising retrieval effectiveness.
Unbiased Multimodal Reranking for Long-Tail Short-Video Search
Mar 26, 2026Kuaishou serving hundreds of millions of searches daily, the quality of short-video search is paramount. However, it suffers from a severe Matthew effect on long-tail queries: sparse user behavior data causes models to amplify low-quality content such as clickbait and shallow content. The recent advancements in Large Language Models (LLMs) offer a new paradigm, as their inherent world knowledge provides a powerful mechanism to assess content quality, agnostic to sparse user interactions. To this end, we propose a LLM-driven multimodal reranking framework, which estimates user experience without real user behavior. The approach involves a two-stage training process: the first stage uses multimodal evidence to construct high-quality annotations for supervised fine-tuning, while the second stage incorporates pairwise preference optimization to help the model learn partial orderings among candidates. At inference time, the resulting experience scores are used to promote high-quality but underexposed videos in reranking, and further guide page-level optimization through reinforcement learning. Experiments show that the proposed method achieves consistent improvements over strong baselines in offline metrics including AUC, NDCG@K, and human preference judgement. An online A/B test covering 15\% of traffic further demonstrates gains in both user experience and consumption metrics, confirming the practical value of the approach in long-tail video search scenarios.
OpenHospital: A Thing-in-itself Arena for Evolving and Benchmarking LLM-based Collective Intelligence
Mar 17, 2026Large Language Model (LLM)-based Collective Intelligence (CI) presents a promising approach to overcoming the data wall and continuously boosting the capabilities of LLM agents. However, there is currently no dedicated arena for evolving and benchmarking LLM-based CI. To address this gap, we introduce OpenHospital, an interactive arena where physician agents can evolve CI through interactions with patient agents. This arena employs a data-in-agent-self paradigm that rapidly enhances agent capabilities and provides robust evaluation metrics for benchmarking both medical proficiency and system efficiency. Experiments demonstrate the effectiveness of OpenHospital in both fostering and quantifying CI.
Can We Predict Before Executing Machine Learning Agents?
Jan 09, 2026Autonomous machine learning agents have revolutionized scientific discovery, yet they remain constrained by a Generate-Execute-Feedback paradigm. Previous approaches suffer from a severe Execution Bottleneck, as hypothesis evaluation relies strictly on expensive physical execution. To bypass these physical constraints, we internalize execution priors to substitute costly runtime checks with instantaneous predictive reasoning, drawing inspiration from World Models. In this work, we formalize the task of Data-centric Solution Preference and construct a comprehensive corpus of 18,438 pairwise comparisons. We demonstrate that LLMs exhibit significant predictive capabilities when primed with a Verified Data Analysis Report, achieving 61.5% accuracy and robust confidence calibration. Finally, we instantiate this framework in FOREAGENT, an agent that employs a Predict-then-Verify loop, achieving a 6x acceleration in convergence while surpassing execution-based baselines by +6%. Our code and dataset will be publicly available soon at https://github.com/zjunlp/predict-before-execute.
CT-Agent: A Multimodal-LLM Agent for 3D CT Radiology Question Answering
May 22, 2025Computed Tomography (CT) scan, which produces 3D volumetric medical data that can be viewed as hundreds of cross-sectional images (a.k.a. slices), provides detailed anatomical information for diagnosis. For radiologists, creating CT radiology reports is time-consuming and error-prone. A visual question answering (VQA) system that can answer radiologists' questions about some anatomical regions on the CT scan and even automatically generate a radiology report is urgently needed. However, existing VQA systems cannot adequately handle the CT radiology question answering (CTQA) task for: (1) anatomic complexity makes CT images difficult to understand; (2) spatial relationship across hundreds slices is difficult to capture. To address these issues, this paper proposes CT-Agent, a multimodal agentic framework for CTQA. CT-Agent adopts anatomically independent tools to break down the anatomic complexity; furthermore, it efficiently captures the across-slice spatial relationship with a global-local token compression strategy. Experimental results on two 3D chest CT datasets, CT-RATE and RadGenome-ChestCT, verify the superior performance of CT-Agent.
Text-to-Pipeline: Bridging Natural Language and Data Preparation Pipelines
May 21, 2025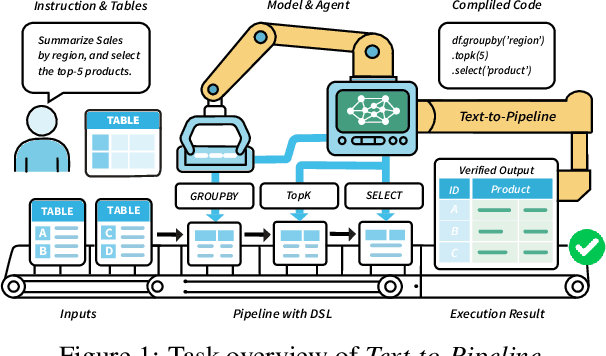


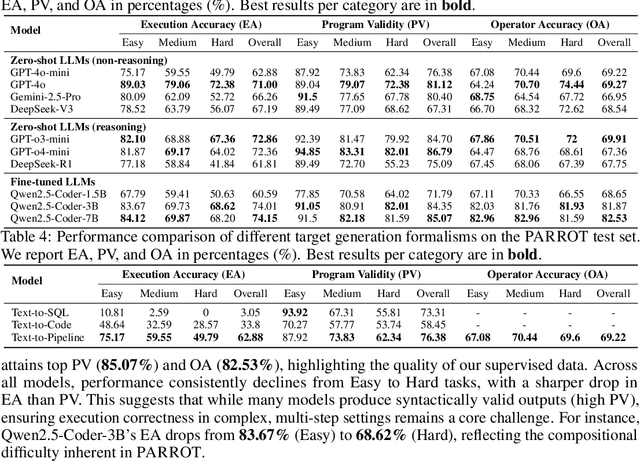
Data preparation (DP) transforms raw data into a form suitable for downstream applications, typically by composing operations into executable pipelines. Building such pipelines is time-consuming and requires sophisticated programming skills. If we can build the pipelines with natural language (NL), the technical barrier of DP will be significantly reduced. However, constructing DP pipelines from NL instructions remains underexplored. To fill the gap, we introduce Text-to-Pipeline, a new task that translates NL data preparation instructions into DP pipelines. Furthermore, we develop a benchmark named PARROT to support systematic evaluation. To simulate realistic DP scenarios, we mined transformation patterns from production pipelines and instantiated them on 23,009 real-world tables collected from six public sources. The resulting benchmark comprises ~18,000 pipelines covering 16 core DP operators. We evaluated cutting-edge large language models on PARROTand observed that they only solved 72.86% of the cases, revealing notable limitations in instruction understanding and multi-step reasoning. To address this, we propose Pipeline-Agent, a stronger baseline that iteratively predicts and executes operations with intermediate table feedback, achieving the best performance of 76.17%. Despite this improvement, there remains substantial room for progress on Text-to-Pipeline. Our data, codes, and evaluation tools are available at https://anonymous.4open.science/r/Text-to-Pipeline.
scAgent: Universal Single-Cell Annotation via a LLM Agent
Apr 07, 2025Cell type annotation is critical for understanding cellular heterogeneity. Based on single-cell RNA-seq data and deep learning models, good progress has been made in annotating a fixed number of cell types within a specific tissue. However, universal cell annotation, which can generalize across tissues, discover novel cell types, and extend to novel cell types, remains less explored. To fill this gap, this paper proposes scAgent, a universal cell annotation framework based on Large Language Models (LLMs). scAgent can identify cell types and discover novel cell types in diverse tissues; furthermore, it is data efficient to learn novel cell types. Experimental studies in 160 cell types and 35 tissues demonstrate the superior performance of scAgent in general cell-type annotation, novel cell discovery, and extensibility to novel cell type.
G-Boost: Boosting Private SLMs with General LLMs
Mar 13, 2025Due to the limited computational resources, most Large Language Models (LLMs) developers can only fine-tune Small Language Models (SLMs) on their own data. These private SLMs typically have limited effectiveness. To boost the performance of private SLMs, this paper proposes to ask general LLMs for help. The general LLMs can be APIs or larger LLMs whose inference cost the developers can afford. Specifically, we propose the G-Boost framework where a private SLM adaptively performs collaborative inference with a general LLM under the guide of process reward. Experiments demonstrate that our framework can significantly boost the performance of private SLMs.
Snoopy: Effective and Efficient Semantic Join Discovery via Proxy Columns
Feb 24, 2025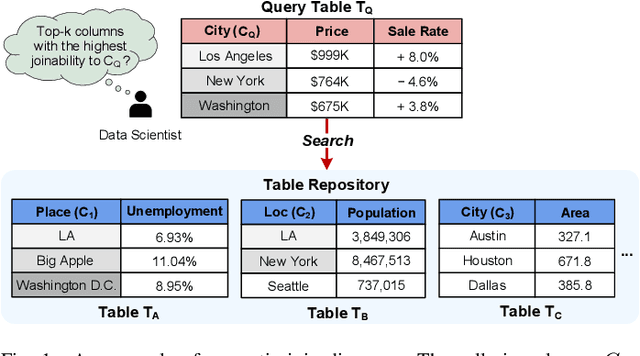
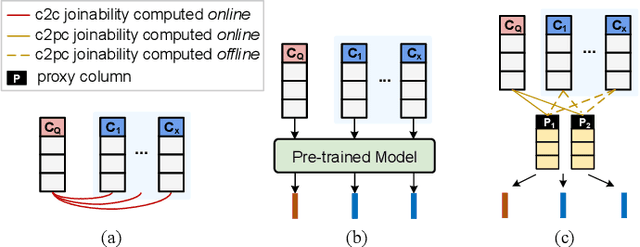
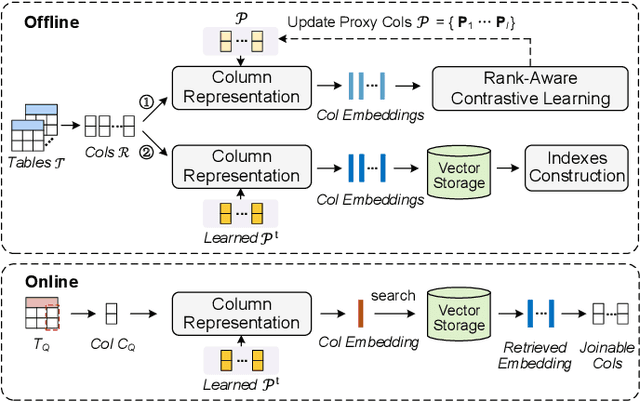

Semantic join discovery, which aims to find columns in a table repository with high semantic joinabilities to a query column, is crucial for dataset discovery. Existing methods can be divided into two categories: cell-level methods and column-level methods. However, neither of them ensures both effectiveness and efficiency simultaneously. Cell-level methods, which compute the joinability by counting cell matches between columns, enjoy ideal effectiveness but suffer poor efficiency. In contrast, column-level methods, which determine joinability only by computing the similarity of column embeddings, enjoy proper efficiency but suffer poor effectiveness due to the issues occurring in their column embeddings: (i) semantics-joinability-gap, (ii) size limit, and (iii) permutation sensitivity. To address these issues, this paper proposes to compute column embeddings via proxy columns; furthermore, a novel column-level semantic join discovery framework, Snoopy, is presented, leveraging proxy-column-based embeddings to bridge effectiveness and efficiency. Specifically, the proposed column embeddings are derived from the implicit column-to-proxy-column relationships, which are captured by the lightweight approximate-graph-matching-based column projection.To acquire good proxy columns for guiding the column projection, we introduce a rank-aware contrastive learning paradigm. Extensive experiments on four real-world datasets demonstrate that Snoopy outperforms SOTA column-level methods by 16% in Recall@25 and 10% in NDCG@25, and achieves superior efficiency--being at least 5 orders of magnitude faster than cell-level solutions, and 3.5x faster than existing column-level methods.
FIT-RAG: Black-Box RAG with Factual Information and Token Reduction
Mar 21, 2024Due to the extraordinarily large number of parameters, fine-tuning Large Language Models (LLMs) to update long-tail or out-of-date knowledge is impractical in lots of applications. To avoid fine-tuning, we can alternatively treat a LLM as a black-box (i.e., freeze the parameters of the LLM) and augment it with a Retrieval-Augmented Generation (RAG) system, namely black-box RAG. Recently, black-box RAG has achieved success in knowledge-intensive tasks and has gained much attention. Existing black-box RAG methods typically fine-tune the retriever to cater to LLMs' preferences and concatenate all the retrieved documents as the input, which suffers from two issues: (1) Ignorance of Factual Information. The LLM preferred documents may not contain the factual information for the given question, which can mislead the retriever and hurt the effectiveness of black-box RAG; (2) Waste of Tokens. Simply concatenating all the retrieved documents brings large amounts of unnecessary tokens for LLMs, which degenerates the efficiency of black-box RAG. To address these issues, this paper proposes a novel black-box RAG framework which utilizes the factual information in the retrieval and reduces the number of tokens for augmentation, dubbed FIT-RAG. FIT-RAG utilizes the factual information by constructing a bi-label document scorer. Besides, it reduces the tokens by introducing a self-knowledge recognizer and a sub-document-level token reducer. FIT-RAG achieves both superior effectiveness and efficiency, which is validated by extensive experiments across three open-domain question-answering datasets: TriviaQA, NQ and PopQA. FIT-RAG can improve the answering accuracy of Llama2-13B-Chat by 14.3\% on TriviaQA, 19.9\% on NQ and 27.5\% on PopQA, respectively. Furthermore, it can save approximately half of the tokens on average across the three datasets.