 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Test-Time Scaling LLMs for Legal Reasoning: OpenAI o1, DeepSeek-R1, and Beyond
Mar 20, 2025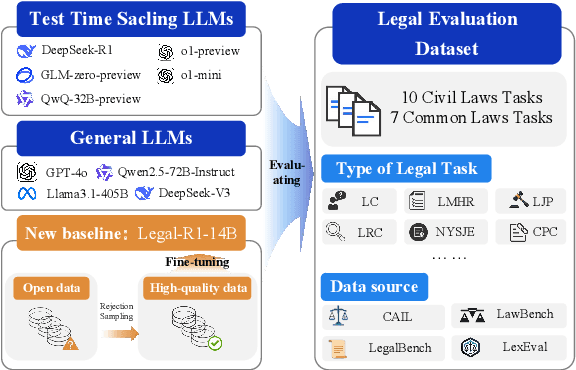
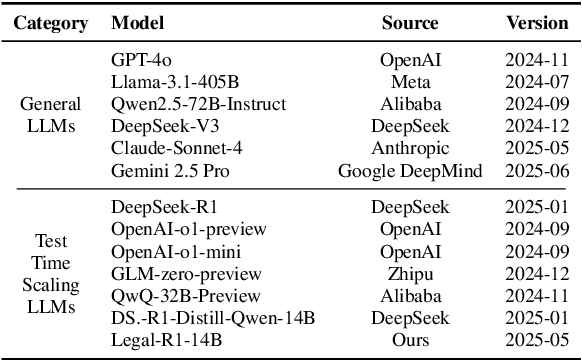
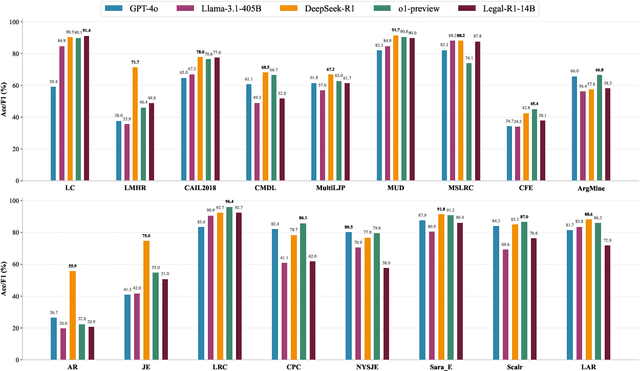
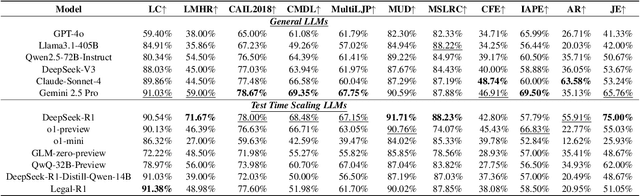
Recently, Test-Time Scaling Large Language Models (LLMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated exceptional capabilities across various domains and tasks, particularly in reasoning. While these models have shown impressive performance on general language tasks, their effectiveness in specialized fields like legal remains unclear. To address this, we present a preliminary evaluation of LLMs in various legal scenarios, covering both Chinese and English legal tasks. Our analysis includes 9 LLMs and 17 legal tasks, with a focus on newly published and more complex challenges such as multi-defendant legal judgments and legal argument reasoning. Our findings indicate that, despite DeepSeek-R1 and OpenAI o1 being among the most powerful models, their legal reasoning capabilities are still lacking. Specifically, these models score below 80\% on seven Chinese legal reasoning tasks and below 80\% on two English legal reasoning tasks. This suggests that, even among the most advanced reasoning models, legal reasoning abilities remain underdeveloped.
Machine Translation Advancements of Low-Resource Indian Languages by Transfer Learning
Sep 24, 2024



This paper introduces the submission by Huawei Translation Center (HW-TSC) to the WMT24 Indian Languages Machine Translation (MT) Shared Task. To develop a reliable machine translation system for low-resource Indian languages, we employed two distinct knowledge transfer strategies, taking into account the characteristics of the language scripts and the support available from existing open-source models for Indian languages. For Assamese(as) and Manipuri(mn), we fine-tuned the existing IndicTrans2 open-source model to enable bidirectional translation between English and these languages. For Khasi (kh) and Mizo (mz), We trained a multilingual model as a baseline using bilingual data from these four language pairs, along with an additional about 8kw English-Bengali bilingual data, all of which share certain linguistic features. This was followed by fine-tuning to achieve bidirectional translation between English and Khasi, as well as English and Mizo. Our transfer learning experiments produced impressive results: 23.5 BLEU for en-as, 31.8 BLEU for en-mn, 36.2 BLEU for as-en, and 47.9 BLEU for mn-en on their respective test sets. Similarly, the multilingual model transfer learning experiments yielded impressive outcomes, achieving 19.7 BLEU for en-kh, 32.8 BLEU for en-mz, 16.1 BLEU for kh-en, and 33.9 BLEU for mz-en on their respective test sets. These results not only highlight the effectiveness of transfer learning techniques for low-resource languages but also contribute to advancing machine translation capabilities for low-resource Indian languages.
Exploring the traditional NMT model and Large Language Model for chat translation
Sep 24, 2024



This paper describes the submissions of Huawei Translation Services Center(HW-TSC) to WMT24 chat translation shared task on English$\leftrightarrow$Germany (en-de) bidirection. The experiments involved fine-tuning models using chat data and exploring various strategies, including Minimum Bayesian Risk (MBR) decoding and self-training. The results show significant performance improvements in certain directions, with the MBR self-training method achieving the best results. The Large Language Model also discusses the challenges and potential avenues for further research in the field of chat translation.
MAVIS: Mathematical Visual Instruction Tuning
Jul 11, 2024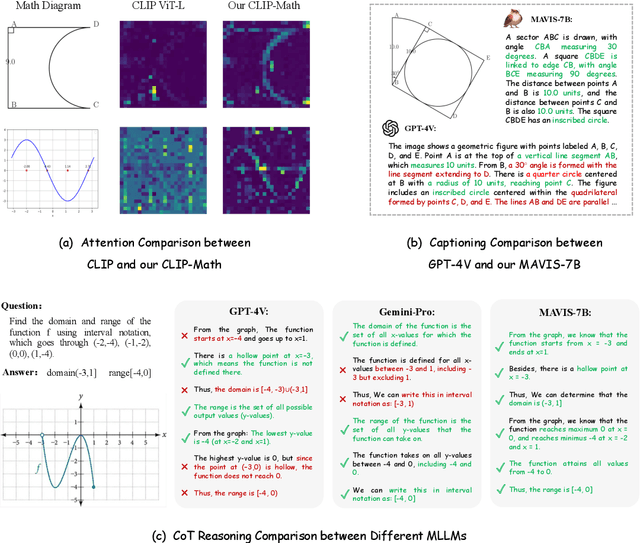
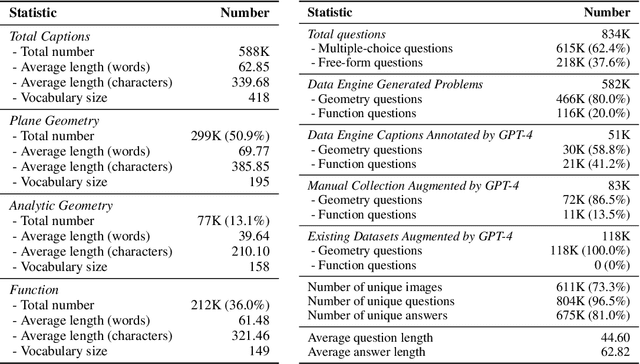
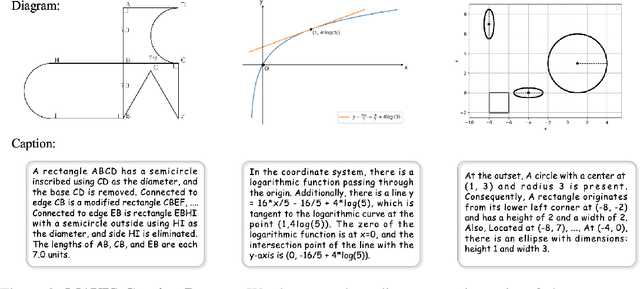

Multi-modal Large Language Models (MLLMs) have recently emerged as a significant focus in academia and industry. Despite their proficiency in general multi-modal scenarios, the mathematical problem-solving capabilities in visual contexts remain insufficiently explored. We identify three key areas within MLLMs that need to be improved: visual encoding of math diagrams, diagram-language alignment, and mathematical reasoning skills. This draws forth an urgent demand for large-scale, high-quality data and training pipelines in visual mathematics. In this paper, we propose MAVIS, the first MAthematical VISual instruction tuning paradigm for MLLMs, involving a series of mathematical visual datasets and specialized MLLMs. Targeting the three issues, MAVIS contains three progressive training stages from scratch. First, we curate MAVIS-Caption, consisting of 558K diagram-caption pairs, to fine-tune a math-specific vision encoder (CLIP-Math) through contrastive learning, tailored for improved diagram visual encoding. Second, we utilize MAVIS-Caption to align the CLIP-Math with a large language model (LLM) by a projection layer, enhancing vision-language alignment in mathematical domains. Third, we introduce MAVIS-Instruct, including 900K meticulously collected and annotated visual math problems, which is adopted to finally instruct-tune the MLLM for robust mathematical reasoning skills. In MAVIS-Instruct, we incorporate complete chain-of-thought (CoT) rationales for each problem, and minimize textual redundancy, thereby concentrating the model towards the visual elements. Data and Models are released at https://github.com/ZrrSkywalker/MAVIS
Knowledge-enhanced Relation Graph and Task Sampling for Few-shot Molecular Property Prediction
May 24, 2024
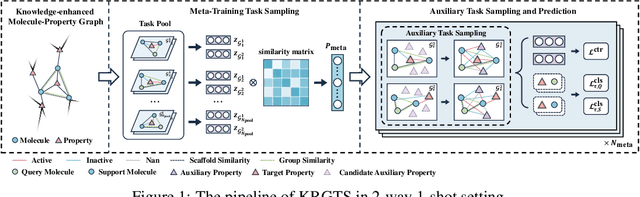
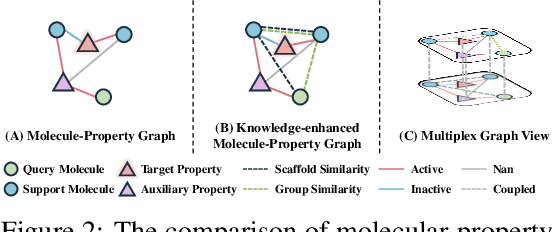
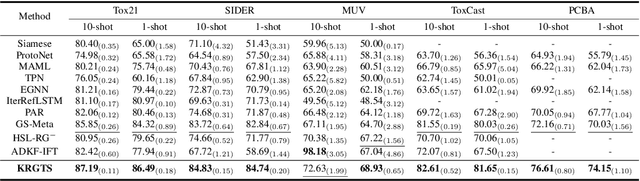
Recently, few-shot molecular property prediction (FSMPP) has garnered increasing attention. Despite impressive breakthroughs achieved by existing methods, they often overlook the inherent many-to-many relationships between molecules and properties, which limits their performance. For instance, similar substructures of molecules can inspire the exploration of new compounds. Additionally, the relationships between properties can be quantified, with high-related properties providing more information in exploring the target property than those low-related. To this end, this paper proposes a novel meta-learning FSMPP framework (KRGTS), which comprises the Knowledge-enhanced Relation Graph module and the Task Sampling module. The knowledge-enhanced relation graph module constructs the molecule-property multi-relation graph (MPMRG) to capture the many-to-many relationships between molecules and properties. The task sampling module includes a meta-training task sampler and an auxiliary task sampler, responsible for scheduling the meta-training process and sampling high-related auxiliary tasks, respectively, thereby achieving efficient meta-knowledge learning and reducing noise introduction. Empirically, extensive experiments on five datasets demonstrate the superiority of KRGTS over a variety of state-of-the-art methods. The code is available in https://github.com/Vencent-Won/KRGTS-public.
FIT-RAG: Black-Box RAG with Factual Information and Token Reduction
Mar 21, 2024Due to the extraordinarily large number of parameters, fine-tuning Large Language Models (LLMs) to update long-tail or out-of-date knowledge is impractical in lots of applications. To avoid fine-tuning, we can alternatively treat a LLM as a black-box (i.e., freeze the parameters of the LLM) and augment it with a Retrieval-Augmented Generation (RAG) system, namely black-box RAG. Recently, black-box RAG has achieved success in knowledge-intensive tasks and has gained much attention. Existing black-box RAG methods typically fine-tune the retriever to cater to LLMs' preferences and concatenate all the retrieved documents as the input, which suffers from two issues: (1) Ignorance of Factual Information. The LLM preferred documents may not contain the factual information for the given question, which can mislead the retriever and hurt the effectiveness of black-box RAG; (2) Waste of Tokens. Simply concatenating all the retrieved documents brings large amounts of unnecessary tokens for LLMs, which degenerates the efficiency of black-box RAG. To address these issues, this paper proposes a novel black-box RAG framework which utilizes the factual information in the retrieval and reduces the number of tokens for augmentation, dubbed FIT-RAG. FIT-RAG utilizes the factual information by constructing a bi-label document scorer. Besides, it reduces the tokens by introducing a self-knowledge recognizer and a sub-document-level token reducer. FIT-RAG achieves both superior effectiveness and efficiency, which is validated by extensive experiments across three open-domain question-answering datasets: TriviaQA, NQ and PopQA. FIT-RAG can improve the answering accuracy of Llama2-13B-Chat by 14.3\% on TriviaQA, 19.9\% on NQ and 27.5\% on PopQA, respectively. Furthermore, it can save approximately half of the tokens on average across the three datasets.