 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Verification Dilemma: Experience-Driven Suppression of Overused Checking in LLM Reasoning
Feb 03, 2026Large Reasoning Models (LRMs) achieve strong performance by generating long reasoning traces with reflection. Through a large-scale empirical analysis, we find that a substantial fraction of reflective steps consist of self-verification (recheck) that repeatedly confirm intermediate results. These rechecks occur frequently across models and benchmarks, yet the vast majority are confirmatory rather than corrective, rarely identifying errors and altering reasoning outcomes. This reveals a mismatch between how often self-verification is activated and how often it is actually useful. Motivated by this, we propose a novel, experience-driven test-time framework that reduces the overused verification. Our method detects the activation of recheck behavior, consults an offline experience pool of past verification outcomes, and estimates whether a recheck is likely unnecessary via efficient retrieval. When historical experience suggests unnecessary, a suppression signal redirects the model to proceed. Across multiple model and benchmarks, our approach reduces token usage up to 20.3% while maintaining the accuracy, and in some datasets even yields accuracy improvements.
V2P: Visual Attention Calibration for GUI Grounding via Background Suppression and Center Peaking
Jan 11, 2026Precise localization of GUI elements is crucial for the development of GUI agents. Traditional methods rely on bounding box or center-point regression, neglecting spatial interaction uncertainty and visual-semantic hierarchies. Recent methods incorporate attention mechanisms but still face two key issues: (1) ignoring processing background regions causes attention drift from the desired area, and (2) uniform modeling the target UI element fails to distinguish between its center and edges, leading to click imprecision. Inspired by how humans visually process and interact with GUI elements, we propose the Valley-to-Peak (V2P) method to address these issues. To mitigate background distractions, V2P introduces a suppression attention mechanism that minimizes the model's focus on irrelevant regions to highlight the intended region. For the issue of center-edge distinction, V2P applies a Fitts' Law-inspired approach by modeling GUI interactions as 2D Gaussian heatmaps where the weight gradually decreases from the center towards the edges. The weight distribution follows a Gaussian function, with the variance determined by the target's size. Consequently, V2P effectively isolates the target area and teaches the model to concentrate on the most essential point of the UI element. The model trained by V2P achieves the performance with 92.4\% and 52.5\% on two benchmarks ScreenSpot-v2 and ScreenSpot-Pro (see Fig.~\ref{fig:main_results_charts}). Ablations further confirm each component's contribution, underscoring V2P's generalizability in precise GUI grounding tasks and its potential for real-world deployment in future GUI agents.
REVEALER: Reinforcement-Guided Visual Reasoning for Element-Level Text-Image Alignment Evaluation
Dec 29, 2025Evaluating the alignment between textual prompts and generated images is critical for ensuring the reliability and usability of text-to-image (T2I) models. However, most existing evaluation methods rely on coarse-grained metrics or static QA pipelines, which lack fine-grained interpretability and struggle to reflect human preferences. To address this, we propose REVEALER, a unified framework for element-level alignment evaluation based on reinforcement-guided visual reasoning. Adopting a structured "grounding-reasoning-conclusion" paradigm, our method enables Multimodal Large Language Models (MLLMs) to explicitly localize semantic elements and derive interpretable alignment judgments. We optimize the model via Group Relative Policy Optimization(GRPO) using a composite reward function that incorporates structural format, grounding accuracy, and alignment fidelity. Extensive experiments across four benchmarks-EvalMuse-40K, RichHF, MHaluBench, and GenAI-Bench-demonstrate that REVEALER achieves state-of-the-art performance. Our approach consistently outperforms both strong proprietary models and supervised baselines while demonstrating superior inference efficiency compared to existing iterative visual reasoning methods.
Fast-Slow Thinking for Large Vision-Language Model Reasoning
Apr 25, 2025Recent advances in large vision-language models (LVLMs) have revealed an \textit{overthinking} phenomenon, where models generate verbose reasoning across all tasks regardless of questions. To address this issue, we present \textbf{FAST}, a novel \textbf{Fa}st-\textbf{S}low \textbf{T}hinking framework that dynamically adapts reasoning depth based on question characteristics. Through empirical analysis, we establish the feasibility of fast-slow thinking in LVLMs by investigating how response length and data distribution affect performance. We develop FAST-GRPO with three components: model-based metrics for question characterization, an adaptive thinking reward mechanism, and difficulty-aware KL regularization. Experiments across seven reasoning benchmarks demonstrate that FAST achieves state-of-the-art accuracy with over 10\% relative improvement compared to the base model, while reducing token usage by 32.7-67.3\% compared to previous slow-thinking approaches, effectively balancing reasoning length and accuracy.
Evaluating Test-Time Scaling LLMs for Legal Reasoning: OpenAI o1, DeepSeek-R1, and Beyond
Mar 20, 2025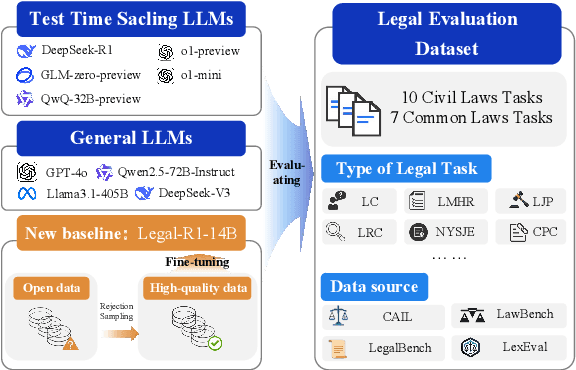
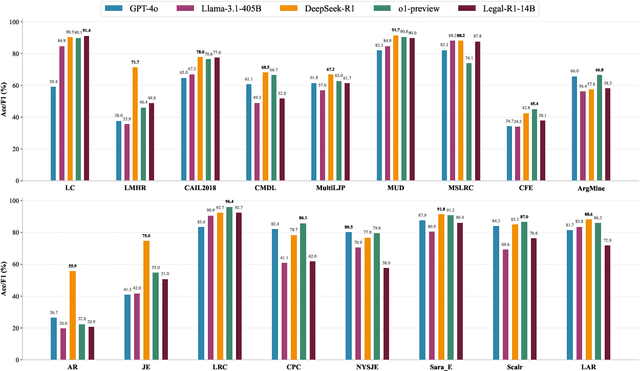
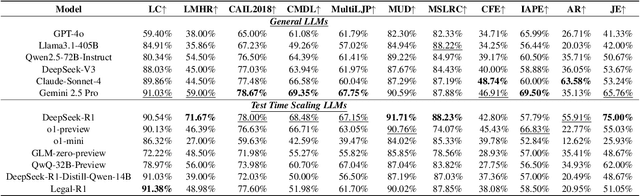
Recently, Test-Time Scaling Large Language Models (LLMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated exceptional capabilities across various domains and tasks, particularly in reasoning. While these models have shown impressive performance on general language tasks, their effectiveness in specialized fields like legal remains unclear. To address this, we present a preliminary evaluation of LLMs in various legal scenarios, covering both Chinese and English legal tasks. Our analysis includes 9 LLMs and 17 legal tasks, with a focus on newly published and more complex challenges such as multi-defendant legal judgments and legal argument reasoning. Our findings indicate that, despite DeepSeek-R1 and OpenAI o1 being among the most powerful models, their legal reasoning capabilities are still lacking. Specifically, these models score below 80\% on seven Chinese legal reasoning tasks and below 80\% on two English legal reasoning tasks. This suggests that, even among the most advanced reasoning models, legal reasoning abilities remain underdeveloped.
SQLCritic: Correcting Text-to-SQL Generation via Clause-wise Critic
Mar 11, 2025Recent advancements in Text-to-SQL systems have improved the conversion of natural language queries into SQL, but challenges remain in ensuring accuracy and reliability. While self-correction techniques refine outputs, they often introduce new errors. Existing methods focused on execution feedback mainly address syntax issues, leaving semantic errors -- where the query's logic fails to align with the user's intent -- largely unaddressed. We propose a novel approach combining structured execution feedback with a trained critic agent that provides detailed, interpretable critiques. This method effectively identifies and corrects both syntactic and semantic errors, enhancing accuracy and interpretability. Experimental results show significant improvements on two major Text-to-SQL benchmarks, Spider and BIRD, demonstrating the effectiveness of our approach.
T2I-FactualBench: Benchmarking the Factuality of Text-to-Image Models with Knowledge-Intensive Concepts
Dec 05, 2024



Evaluating the quality of synthesized images remains a significant challenge in the development of text-to-image (T2I) generation. Most existing studies in this area primarily focus on evaluating text-image alignment, image quality, and object composition capabilities, with comparatively fewer studies addressing the evaluation of the factuality of T2I models, particularly when the concepts involved are knowledge-intensive. To mitigate this gap, we present T2I-FactualBench in this work - the largest benchmark to date in terms of the number of concepts and prompts specifically designed to evaluate the factuality of knowledge-intensive concept generation. T2I-FactualBench consists of a three-tiered knowledge-intensive text-to-image generation framework, ranging from the basic memorization of individual knowledge concepts to the more complex composition of multiple knowledge concepts. We further introduce a multi-round visual question answering (VQA) based evaluation framework to assess the factuality of three-tiered knowledge-intensive text-to-image generation tasks. Experiments on T2I-FactualBench indicate that current state-of-the-art (SOTA) T2I models still leave significant room for improvement.
A Comprehensive Survey of Datasets, Theories, Variants, and Applications in Direct Preference Optimization
Oct 21, 2024With the rapid advancement of large language models (LLMs), aligning policy models with human preferences has become increasingly critical. Direct Preference Optimization (DPO) has emerged as a promising approach for alignment, acting as an RL-free alternative to Reinforcement Learning from Human Feedback (RLHF). Despite DPO's various advancements and inherent limitations, an in-depth review of these aspects is currently lacking in the literature. In this work, we present a comprehensive review of the challenges and opportunities in DPO, covering theoretical analyses, variants, relevant preference datasets, and applications. Specifically, we categorize recent studies on DPO based on key research questions to provide a thorough understanding of DPO's current landscape. Additionally, we propose several future research directions to offer insights on model alignment for the research community.
Weak-To-Strong Backdoor Attacks for LLMs with Contrastive Knowledge Distillation
Sep 26, 2024Despite being widely applied due to their exceptional capabilities, Large Language Models (LLMs) have been proven to be vulnerable to backdoor attacks. These attacks introduce targeted vulnerabilities into LLMs by poisoning training samples and full-parameter fine-tuning. However, this kind of backdoor attack is limited since they require significant computational resources, especially as the size of LLMs increases. Besides, parameter-efficient fine-tuning (PEFT) offers an alternative but the restricted parameter updating may impede the alignment of triggers with target labels. In this study, we first verify that backdoor attacks with PEFT may encounter challenges in achieving feasible performance. To address these issues and improve the effectiveness of backdoor attacks with PEFT, we propose a novel backdoor attack algorithm from weak to strong based on contrastive knowledge distillation (W2SAttack). Specifically, we poison small-scale language models through full-parameter fine-tuning to serve as the teacher model. The teacher model then covertly transfers the backdoor to the large-scale student model through contrastive knowledge distillation, which employs PEFT. Theoretical analysis reveals that W2SAttack has the potential to augment the effectiveness of backdoor attacks. We demonstrate the superior performance of W2SAttack on classification tasks across four language models, four backdoor attack algorithms, and two different architectures of teacher models. Experimental results indicate success rates close to 100% for backdoor attacks targeting PEFT.
Retrieval-Augmented Mixture of LoRA Experts for Uploadable Machine Learning
Jun 24, 2024



Low-Rank Adaptation (LoRA) offers an efficient way to fine-tune large language models (LLMs). Its modular and plug-and-play nature allows the integration of various domain-specific LoRAs, enhancing LLM capabilities. Open-source platforms like Huggingface and Modelscope have introduced a new computational paradigm, Uploadable Machine Learning (UML). In UML, contributors use decentralized data to train specialized adapters, which are then uploaded to a central platform to improve LLMs. This platform uses these domain-specific adapters to handle mixed-task requests requiring personalized service. Previous research on LoRA composition either focuses on specific tasks or fixes the LoRA selection during training. However, in UML, the pool of LoRAs is dynamically updated with new uploads, requiring a generalizable selection mechanism for unseen LoRAs. Additionally, the mixed-task nature of downstream requests necessitates personalized services. To address these challenges, we propose Retrieval-Augmented Mixture of LoRA Experts (RAMoLE), a framework that adaptively retrieves and composes multiple LoRAs based on input prompts. RAMoLE has three main components: LoraRetriever for identifying and retrieving relevant LoRAs, an on-the-fly MoLE mechanism for coordinating the retrieved LoRAs, and efficient batch inference for handling heterogeneous requests. Experimental results show that RAMoLE consistently outperforms baselines, highlighting its effectiveness and scalability.