 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Learning to Route with Asymmetry-aware DistAnce Representations
Mar 05, 2026Recent neural solvers have achieved strong performance on vehicle routing problems (VRPs), yet they mainly assume symmetric Euclidean distances, restricting applicability to real-world scenarios. A core challenge is encoding the relational features in asymmetric distance matrices of VRPs. Early attempts directly encoded these matrices but often failed to produce compact embeddings and generalized poorly at scale. In this paper, we propose RADAR, a scalable neural framework that augments existing neural VRP solvers with the ability to handle asymmetric inputs. RADAR addresses asymmetry from both static and dynamic perspectives. It leverages Singular Value Decomposition (SVD) on the asymmetric distance matrix to initialize compact and generalizable embeddings that inherently encode the static asymmetry in the inbound and outbound costs of each node. To further model dynamic asymmetry in embedding interactions during encoding, it replaces the standard softmax with Sinkhorn normalization that imposes joint row and column distance awareness in attention weights. Extensive experiments on synthetic and real-world benchmarks across various VRPs show that RADAR outperforms strong baselines on both in-distribution and out-of-distribution instances, demonstrating robust generalization and superior performance in solving asymmetric VRPs.
WiCo-PG: Wireless Channel Foundation Model for Pathloss Map Generation via Synesthesia of Machines
Nov 19, 2025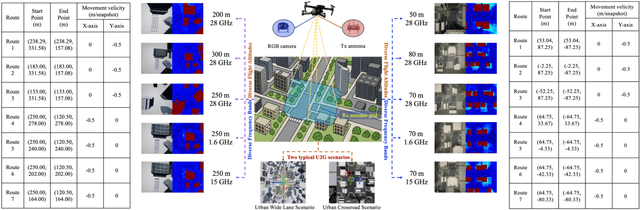
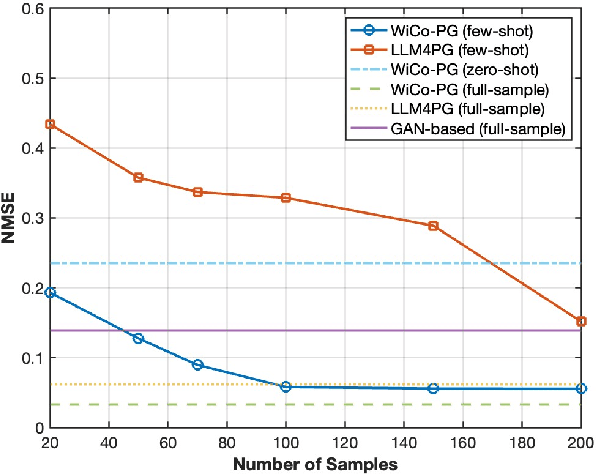
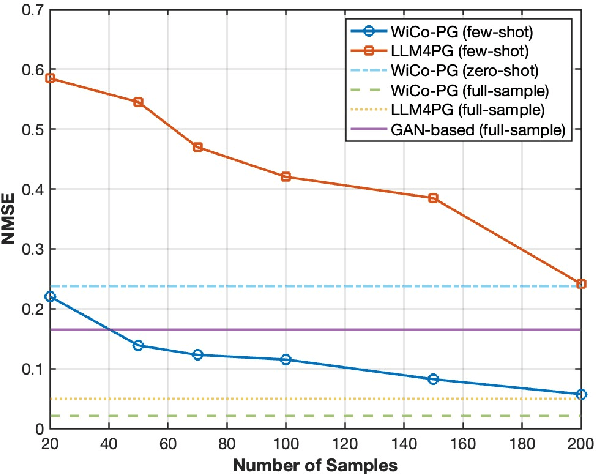
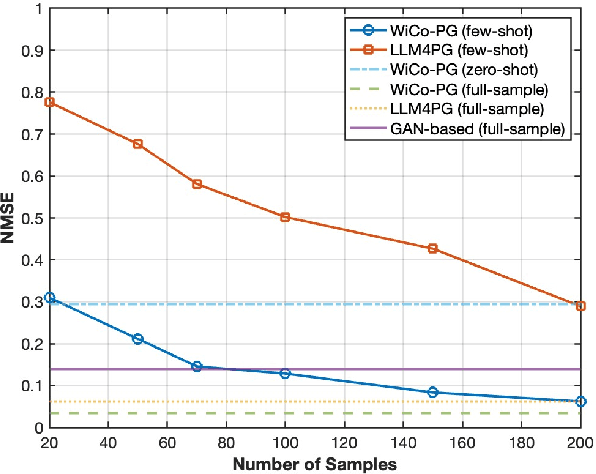
A wireless channel foundation model for pathloss map generation (WiCo-PG) via Synesthesia of Machines (SoM) is developed for the first time. Considering sixth-generation (6G) uncrewed aerial vehicle (UAV)-to-ground (U2G) scenarios, a new multi-modal sensing-communication dataset is constructed for WiCo-PG pre-training, including multiple U2G scenarios, diverse flight altitudes, and diverse frequency bands. Based on the constructed dataset, the proposed WiCo-PG enables cross-modal pathloss map generation by leveraging RGB images from different scenarios and flight altitudes. In WiCo-PG, a novel network architecture designed for cross-modal pathloss map generation based on dual vector quantized generative adversarial networks (VQGANs) and Transformer is proposed. Furthermore, a novel frequency-guided shared-routed mixture of experts (S-R MoE) architecture is designed for cross-modal pathloss map generation. Simulation results demonstrate that the proposed WiCo-PG achieves improved pathloss map generation accuracy through pre-training with a normalized mean squared error (NMSE) of 0.012, outperforming the large language model (LLM)-based scheme, i.e., LLM4PG, and the conventional deep learning-based scheme by more than 6.98 dB. The enhanced generality of the proposed WiCo-PG can further outperform the LLM4PG by at least 1.37 dB using 2.7% samples in few-shot generalization.
SynthSoM-Twin: A Multi-Modal Sensing-Communication Digital-Twin Dataset for Sim2Real Transfer via Synesthesia of Machines
Nov 14, 2025



This paper constructs a novel multi-modal sensing-communication digital-twin dataset, named SynthSoM-Twin, which is spatio-temporally consistent with the real world, for Sim2Real transfer via Synesthesia of Machines (SoM). To construct the SynthSoM-Twin dataset, we propose a new framework that can extend the quantity and missing modality of existing real-world multi-modal sensing-communication dataset. Specifically, we exploit multi-modal sensing-assisted object detection and tracking algorithms to ensure spatio-temporal consistency of static objects and dynamic objects across real world and simulation environments. The constructed scenario is imported into three high-fidelity simulators, i.e., AirSim, WaveFarer, and Sionna RT. The SynthSoM-Twin dataset contains spatio-temporally consistent data with the real world, including 66,868 snapshots of synthetic RGB images, depth maps, light detection and ranging (LiDAR) point clouds, millimeter wave (mmWave) radar point clouds, and large-scale and small-scale channel fading data. To validate the utility of SynthSoM-Twin dataset, we conduct Sim2Real transfer investigation by implementing two cross-modal downstream tasks via cross-modal generative models (CMGMs), i.e., cross-modal channel generation model and multi-modal sensing-assisted beam generation model. Based on the downstream tasks, we explore the threshold of real-world data injection that can achieve a decent trade-off between real-world data usage and models' practical performance. Experimental results show that the model training on the SynthSoM-Twin dataset achieves a decent practical performance, and the injection of real-world data further facilitates Sim2Real transferability. Based on the SynthSoM-Twin dataset, injecting less than 15% of real-world data can achieve similar and even better performance compared to that trained with all the real-world data only.
TBStar-Edit: From Image Editing Pattern Shifting to Consistency Enhancement
Oct 06, 2025Recent advances in image generation and editing technologies have enabled state-of-the-art models to achieve impressive results in general domains. However, when applied to e-commerce scenarios, these general models often encounter consistency limitations. To address this challenge, we introduce TBStar-Edit, an new image editing model tailored for the e-commerce domain. Through rigorous data engineering, model architecture design and training strategy, TBStar-Edit achieves precise and high-fidelity image editing while maintaining the integrity of product appearance and layout. Specifically, for data engineering, we establish a comprehensive data construction pipeline, encompassing data collection, construction, filtering, and augmentation, to acquire high-quality, instruction-following, and strongly consistent editing data to support model training. For model architecture design, we design a hierarchical model framework consisting of a base model, pattern shifting modules, and consistency enhancement modules. For model training, we adopt a two-stage training strategy to enhance the consistency preservation: first stage for editing pattern shifting, and second stage for consistency enhancement. Each stage involves training different modules with separate datasets. Finally, we conduct extensive evaluations of TBStar-Edit on a self-proposed e-commerce benchmark, and the results demonstrate that TBStar-Edit outperforms existing general-domain editing models in both objective metrics (VIE Score) and subjective user preference.
LLM4MG: Adapting Large Language Model for Multipath Generation via Synesthesia of Machines
Sep 18, 2025Based on Synesthesia of Machines (SoM), a large language model (LLM) is adapted for multipath generation (LLM4MG) for the first time. Considering a typical sixth-generation (6G) vehicle-to-infrastructure (V2I) scenario, a new multi-modal sensing-communication dataset is constructed, named SynthSoM-V2I, including channel multipath information, millimeter wave (mmWave) radar sensory data, RGB-D images, and light detection and ranging (LiDAR) point clouds. Based on the SynthSoM-V2I dataset, the proposed LLM4MG leverages Large Language Model Meta AI (LLaMA) 3.2 for multipath generation via multi-modal sensory data. The proposed LLM4MG aligns the multi-modal feature space with the LLaMA semantic space through feature extraction and fusion networks. To further achieve general knowledge transfer from the pre-trained LLaMA for multipath generation via multi-modal sensory data, the low-rank adaptation (LoRA) parameter-efficient fine-tuning and propagation-aware prompt engineering are exploited. Simulation results demonstrate that the proposed LLM4MG outperforms conventional deep learning-based methods in terms of line-of-sight (LoS)/non-LoS (NLoS) classification with accuracy of 92.76%, multipath power/delay generation precision with normalized mean square error (NMSE) of 0.099/0.032, and cross-vehicular traffic density (VTD), cross-band, and cross-scenario generalization. The utility of the proposed LLM4MG is validated by real-world generalization. The necessity of high-precision multipath generation for system design is also demonstrated by channel capacity comparison.
Foundation Model Empowered Synesthesia of Machines (SoM): AI-native Intelligent Multi-Modal Sensing-Communication Integration
Jun 09, 2025To support future intelligent multifunctional sixth-generation (6G) wireless communication networks, Synesthesia of Machines (SoM) is proposed as a novel paradigm for artificial intelligence (AI)-native intelligent multi-modal sensing-communication integration. However, existing SoM system designs rely on task-specific AI models and face challenges such as scarcity of massive high-quality datasets, constrained modeling capability, poor generalization, and limited universality. Recently, foundation models (FMs) have emerged as a new deep learning paradigm and have been preliminarily applied to SoM-related tasks, but a systematic design framework is still lacking. In this paper, we for the first time present a systematic categorization of FMs for SoM system design, dividing them into general-purpose FMs, specifically large language models (LLMs), and SoM domain-specific FMs, referred to as wireless foundation models. Furthermore, we derive key characteristics of FMs in addressing existing challenges in SoM systems and propose two corresponding roadmaps, i.e., LLM-based and wireless foundation model-based design. For each roadmap, we provide a framework containing key design steps as a guiding pipeline and several representative case studies of FM-empowered SoM system design. Specifically, we propose LLM-based path loss generation (LLM4PG) and scatterer generation (LLM4SG) schemes, and wireless channel foundation model (WiCo) for SoM mechanism exploration, LLM-based wireless multi-task SoM transceiver (LLM4WM) and wireless foundation model (WiFo) for SoM-enhanced transceiver design, and wireless cooperative perception foundation model (WiPo) for SoM-enhanced cooperative perception, demonstrating the significant superiority of FMs over task-specific models. Finally, we summarize and highlight potential directions for future research.
LLM4SP: Large Language Models for Scatterer Prediction via Synesthesia of Machines
May 23, 2025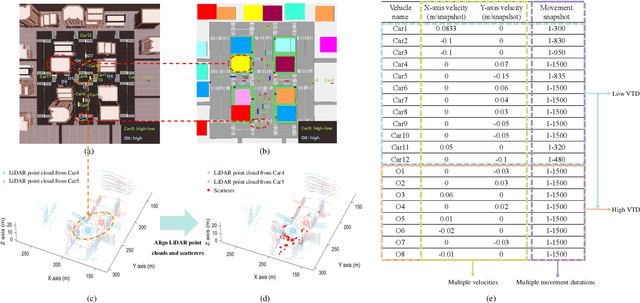
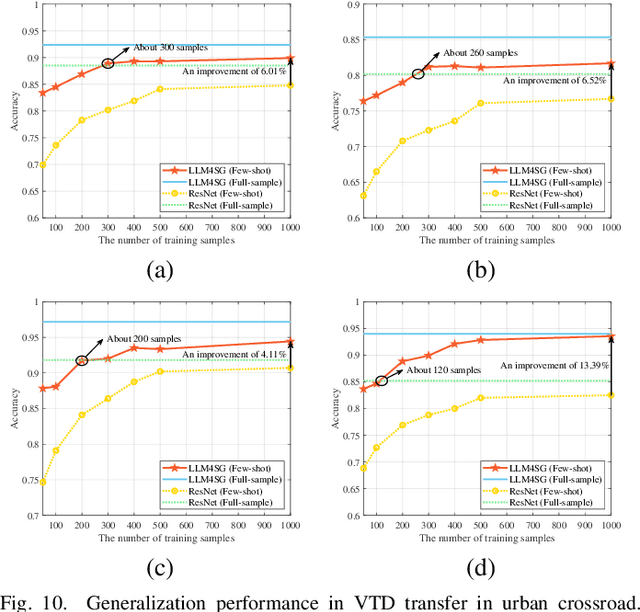
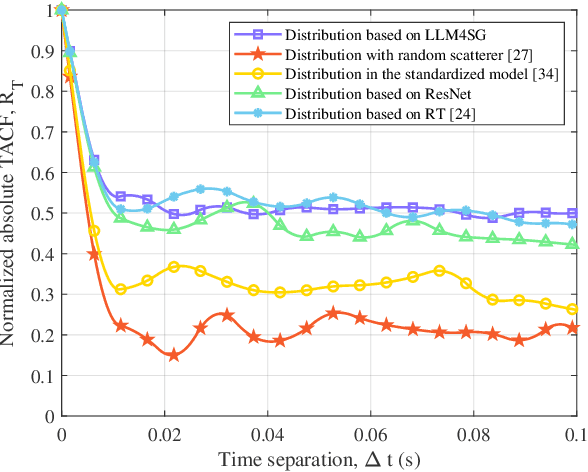
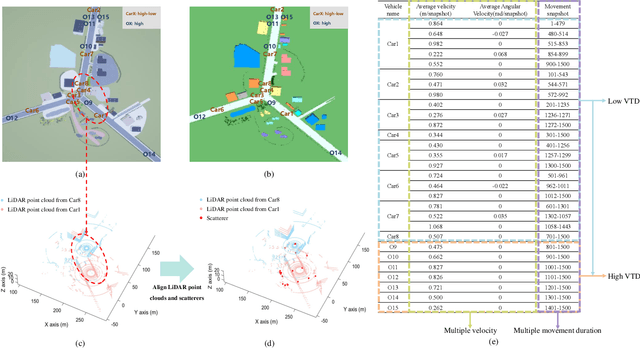
Guided by Synesthesia of Machines (SoM), the nonlinear mapping relationship between sensory and communication information serves as a powerful tool to enhance both the accuracy and generalization of vehicle-to-vehicle (V2V) multi-modal intelligent channel modeling (MMICM) in intelligent transportation systems (ITSs). To explore the general mapping relationship between physical environment and electromagnetic space, a new intelligent sensing-communication integration dataset, named V2V-M3, is constructed for multiple scenarios in V2V communications with multiple frequency bands and multiple vehicular traffic densities (VTDs). Leveraging the strong representation and cross-modal inference capabilities of large language models (LLMs), a novel LLM-based method for Scatterer Prediction (LLM4SP) from light detection and ranging (LiDAR) point clouds is developed. To address the inherent and significant differences across multi-modal data, synergistically optimized four-module architecture, i.e., preprocessor, embedding, backbone, and output modules, are designed by considering the sensing/channel characteristics and electromagnetic propagation mechanism. On the basis of cross-modal representation alignment and positional encoding, the network of LLM4SP is fine-tuned to capture the general mapping relationship between LiDAR point clouds and scatterers. Simulation results demonstrate that the proposed LLM4SP achieves superior performance in full-sample and generalization testing, significantly outperforming small models across different frequency bands, scenarios, and VTDs.
Fast-Slow Thinking for Large Vision-Language Model Reasoning
Apr 25, 2025Recent advances in large vision-language models (LVLMs) have revealed an \textit{overthinking} phenomenon, where models generate verbose reasoning across all tasks regardless of questions. To address this issue, we present \textbf{FAST}, a novel \textbf{Fa}st-\textbf{S}low \textbf{T}hinking framework that dynamically adapts reasoning depth based on question characteristics. Through empirical analysis, we establish the feasibility of fast-slow thinking in LVLMs by investigating how response length and data distribution affect performance. We develop FAST-GRPO with three components: model-based metrics for question characterization, an adaptive thinking reward mechanism, and difficulty-aware KL regularization. Experiments across seven reasoning benchmarks demonstrate that FAST achieves state-of-the-art accuracy with over 10\% relative improvement compared to the base model, while reducing token usage by 32.7-67.3\% compared to previous slow-thinking approaches, effectively balancing reasoning length and accuracy.
MINT: Multi-modal Chain of Thought in Unified Generative Models for Enhanced Image Generation
Mar 03, 2025Unified generative models have demonstrated extraordinary performance in both text and image generation. However, they tend to underperform when generating intricate images with various interwoven conditions, which is hard to solely rely on straightforward text-to-image generation. In response to this challenge, we introduce MINT, an innovative unified generative model, empowered with native multimodal chain of thought (MCoT) for enhanced image generation for the first time. Firstly, we design Mixture of Transformer Experts (MTXpert), an expert-parallel structure that effectively supports both natural language generation (NLG) and visual capabilities, while avoiding potential modality conflicts that could hinder the full potential of each modality. Building on this, we propose an innovative MCoT training paradigm, a step-by-step approach to multimodal thinking, reasoning, and reflection specifically designed to enhance image generation. This paradigm equips MINT with nuanced, element-wise decoupled alignment and a comprehensive understanding of textual and visual components. Furthermore, it fosters advanced multimodal reasoning and self-reflection, enabling the construction of images that are firmly grounded in the logical relationships between these elements. Notably, MINT has been validated to exhibit superior performance across multiple benchmarks for text-to-image (T2I) and image-to-text (I2T) tasks.
A Multi-modal Intelligent Channel Model for 6G Multi-UAV-to-Multi-Vehicle Communications
Jan 15, 2025



In this paper, a novel multi-modal intelligent channel model for sixth-generation (6G) multiple-unmanned aerial vehicle (multi-UAV)-to-multi-vehicle communications is proposed. To thoroughly explore the mapping relationship between the physical environment and the electromagnetic space in the complex multi-UAV-to-multi-vehicle scenario, two new parameters, i.e., terrestrial traffic density (TTD) and aerial traffic density (ATD), are developed and a new sensing-communication intelligent integrated dataset is constructed in suburban scenario under different TTD and ATD conditions. With the aid of sensing data, i.e., light detection and ranging (LiDAR) point clouds, the parameters of static scatterers, terrestrial dynamic scatterers, and aerial dynamic scatterers in the electromagnetic space, e.g., number, distance, angle, and power, are quantified under different TTD and ATD conditions in the physical environment. In the proposed model, the channel non-stationarity and consistency on the time and space domains and the channel non-stationarity on the frequency domain are simultaneously mimicked. The channel statistical properties, such as time-space-frequency correlation function (TSF-CF), time stationary interval (TSI), and Doppler power spectral density (DPSD), are derived and simulated. Simulation results match ray-tracing (RT) results well, which verifies the accuracy of the proposed multi-UAV-to-multi-vehicle channel model.