 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTBStar-Edit: From Image Editing Pattern Shifting to Consistency Enhancement
Oct 06, 2025Recent advances in image generation and editing technologies have enabled state-of-the-art models to achieve impressive results in general domains. However, when applied to e-commerce scenarios, these general models often encounter consistency limitations. To address this challenge, we introduce TBStar-Edit, an new image editing model tailored for the e-commerce domain. Through rigorous data engineering, model architecture design and training strategy, TBStar-Edit achieves precise and high-fidelity image editing while maintaining the integrity of product appearance and layout. Specifically, for data engineering, we establish a comprehensive data construction pipeline, encompassing data collection, construction, filtering, and augmentation, to acquire high-quality, instruction-following, and strongly consistent editing data to support model training. For model architecture design, we design a hierarchical model framework consisting of a base model, pattern shifting modules, and consistency enhancement modules. For model training, we adopt a two-stage training strategy to enhance the consistency preservation: first stage for editing pattern shifting, and second stage for consistency enhancement. Each stage involves training different modules with separate datasets. Finally, we conduct extensive evaluations of TBStar-Edit on a self-proposed e-commerce benchmark, and the results demonstrate that TBStar-Edit outperforms existing general-domain editing models in both objective metrics (VIE Score) and subjective user preference.
MADiff: Text-Guided Fashion Image Editing with Mask Prediction and Attention-Enhanced Diffusion
Dec 28, 2024
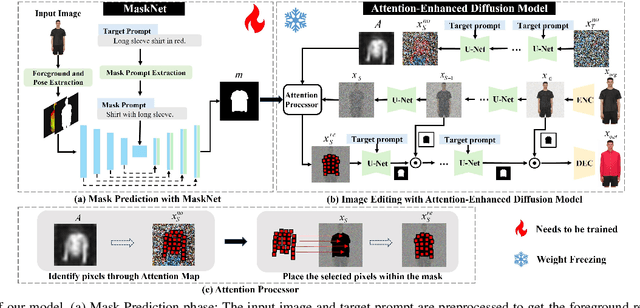

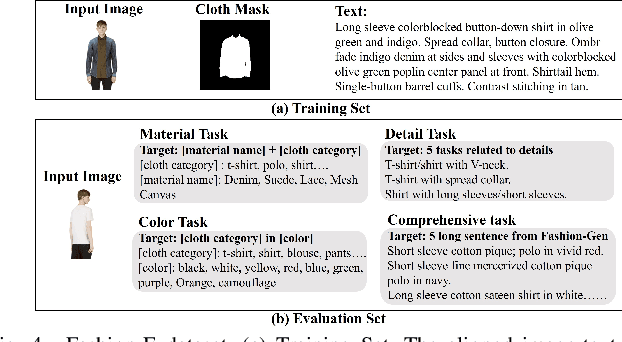
Text-guided image editing model has achieved great success in general domain. However, directly applying these models to the fashion domain may encounter two issues: (1) Inaccurate localization of editing region; (2) Weak editing magnitude. To address these issues, the MADiff model is proposed. Specifically, to more accurately identify editing region, the MaskNet is proposed, in which the foreground region, densepose and mask prompts from large language model are fed into a lightweight UNet to predict the mask for editing region. To strengthen the editing magnitude, the Attention-Enhanced Diffusion Model is proposed, where the noise map, attention map, and the mask from MaskNet are fed into the proposed Attention Processor to produce a refined noise map. By integrating the refined noise map into the diffusion model, the edited image can better align with the target prompt. Given the absence of benchmarks in fashion image editing, we constructed a dataset named Fashion-E, comprising 28390 image-text pairs in the training set, and 2639 image-text pairs for four types of fashion tasks in the evaluation set. Extensive experiments on Fashion-E demonstrate that our proposed method can accurately predict the mask of editing region and significantly enhance editing magnitude in fashion image editing compared to the state-of-the-art methods.
FashionFAE: Fine-grained Attributes Enhanced Fashion Vision-Language Pre-training
Dec 28, 2024Large-scale Vision-Language Pre-training (VLP) has demonstrated remarkable success in the general domain. However, in the fashion domain, items are distinguished by fine-grained attributes like texture and material, which are crucial for tasks such as retrieval. Existing models often fail to leverage these fine-grained attributes from both text and image modalities. To address the above issues, we propose a novel approach for the fashion domain, Fine-grained Attributes Enhanced VLP (FashionFAE), which focuses on the detailed characteristics of fashion data. An attribute-emphasized text prediction task is proposed to predict fine-grained attributes of the items. This forces the model to focus on the salient attributes from the text modality. Additionally, a novel attribute-promoted image reconstruction task is proposed, which further enhances the fine-grained ability of the model by leveraging the representative attributes from the image modality. Extensive experiments show that FashionFAE significantly outperforms State-Of-The-Art (SOTA) methods, achieving 2.9% and 5.2% improvements in retrieval on sub-test and full test sets, respectively, and a 1.6% average improvement in recognition tasks.