 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASPO: Adaptive Sentence-Level Preference Optimization for Fine-Grained Multimodal Reasoning
May 25, 2025Direct Preference Optimization (DPO) has gained significant attention for its simplicity and computational efficiency in aligning large language models (LLMs). Recent advancements have extended DPO to multimodal scenarios, achieving strong performance. However, traditional DPO relies on binary preference optimization, rewarding or penalizing entire responses without considering fine-grained segment correctness, leading to suboptimal solutions. The root of this issue lies in the absence of fine-grained supervision during the optimization process. To address this, we propose Adaptive Sentence-level Preference Optimization (ASPO), which evaluates individual sentences for more precise preference optimization. By dynamically calculating adaptive rewards at the sentence level based on model predictions, ASPO enhances response content assessment without additional models or parameters. This significantly improves the alignment of multimodal features. Extensive experiments show that ASPO substantially enhances the overall performance of multimodal models.
Instruction-Aligned Visual Attention for Mitigating Hallucinations in Large Vision-Language Models
Mar 24, 2025Despite the significant success of Large Vision-Language models(LVLMs), these models still suffer hallucinations when describing images, generating answers that include non-existent objects. It is reported that these models tend to over-focus on certain irrelevant image tokens that do not contain critical information for answering the question and distort the output. To address this, we propose an Instruction-Aligned Visual Attention(IAVA) approach, which identifies irrelevant tokens by comparing changes in attention weights under two different instructions. By applying contrastive decoding, we dynamically adjust the logits generated from original image tokens and irrelevant image tokens, reducing the model's over-attention to irrelevant information. The experimental results demonstrate that IAVA consistently outperforms existing decoding techniques on benchmarks such as MME, POPE, and TextVQA in mitigating object hallucinations. Our IAVA approach is available online at https://github.com/Lee-lab558/IAVA.
MADiff: Text-Guided Fashion Image Editing with Mask Prediction and Attention-Enhanced Diffusion
Dec 28, 2024
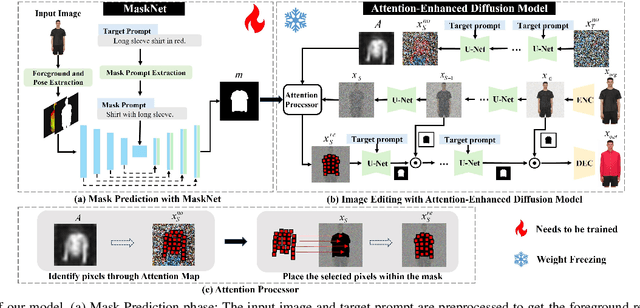

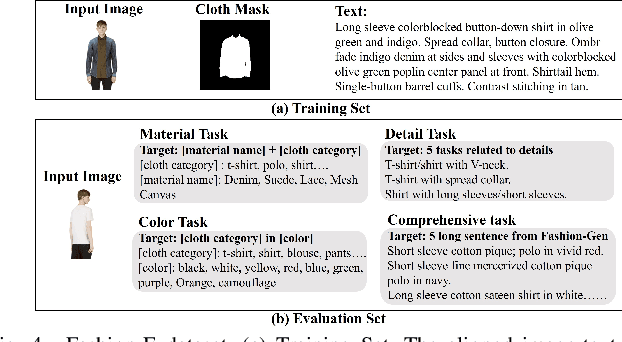
Text-guided image editing model has achieved great success in general domain. However, directly applying these models to the fashion domain may encounter two issues: (1) Inaccurate localization of editing region; (2) Weak editing magnitude. To address these issues, the MADiff model is proposed. Specifically, to more accurately identify editing region, the MaskNet is proposed, in which the foreground region, densepose and mask prompts from large language model are fed into a lightweight UNet to predict the mask for editing region. To strengthen the editing magnitude, the Attention-Enhanced Diffusion Model is proposed, where the noise map, attention map, and the mask from MaskNet are fed into the proposed Attention Processor to produce a refined noise map. By integrating the refined noise map into the diffusion model, the edited image can better align with the target prompt. Given the absence of benchmarks in fashion image editing, we constructed a dataset named Fashion-E, comprising 28390 image-text pairs in the training set, and 2639 image-text pairs for four types of fashion tasks in the evaluation set. Extensive experiments on Fashion-E demonstrate that our proposed method can accurately predict the mask of editing region and significantly enhance editing magnitude in fashion image editing compared to the state-of-the-art methods.
FashionFAE: Fine-grained Attributes Enhanced Fashion Vision-Language Pre-training
Dec 28, 2024Large-scale Vision-Language Pre-training (VLP) has demonstrated remarkable success in the general domain. However, in the fashion domain, items are distinguished by fine-grained attributes like texture and material, which are crucial for tasks such as retrieval. Existing models often fail to leverage these fine-grained attributes from both text and image modalities. To address the above issues, we propose a novel approach for the fashion domain, Fine-grained Attributes Enhanced VLP (FashionFAE), which focuses on the detailed characteristics of fashion data. An attribute-emphasized text prediction task is proposed to predict fine-grained attributes of the items. This forces the model to focus on the salient attributes from the text modality. Additionally, a novel attribute-promoted image reconstruction task is proposed, which further enhances the fine-grained ability of the model by leveraging the representative attributes from the image modality. Extensive experiments show that FashionFAE significantly outperforms State-Of-The-Art (SOTA) methods, achieving 2.9% and 5.2% improvements in retrieval on sub-test and full test sets, respectively, and a 1.6% average improvement in recognition tasks.
CoF: Coarse to Fine-Grained Image Understanding for Multi-modal Large Language Models
Dec 22, 2024



The impressive performance of Large Language Model (LLM) has prompted researchers to develop Multi-modal LLM (MLLM), which has shown great potential for various multi-modal tasks. However, current MLLM often struggles to effectively address fine-grained multi-modal challenges. We argue that this limitation is closely linked to the models' visual grounding capabilities. The restricted spatial awareness and perceptual acuity of visual encoders frequently lead to interference from irrelevant background information in images, causing the models to overlook subtle but crucial details. As a result, achieving fine-grained regional visual comprehension becomes difficult. In this paper, we break down multi-modal understanding into two stages, from Coarse to Fine (CoF). In the first stage, we prompt the MLLM to locate the approximate area of the answer. In the second stage, we further enhance the model's focus on relevant areas within the image through visual prompt engineering, adjusting attention weights of pertinent regions. This, in turn, improves both visual grounding and overall performance in downstream tasks. Our experiments show that this approach significantly boosts the performance of baseline models, demonstrating notable generalization and effectiveness. Our CoF approach is available online at https://github.com/Gavin001201/CoF.
Enhancing Fine-Grained Vision-Language Pretraining with Negative Augmented Samples
Dec 13, 2024



Existing Vision-Language Pretraining (VLP) methods have achieved remarkable improvements across a variety of vision-language tasks, confirming their effectiveness in capturing coarse-grained semantic correlations. However, their capability for fine-grained understanding, which is critical for many nuanced vision-language applications, remains limited. Prevailing VLP models often overlook the intricate distinctions in expressing different modal features and typically depend on the similarity of holistic features for cross-modal interactions. Moreover, these models directly align and integrate features from different modalities, focusing more on coarse-grained general representations, thus failing to capture the nuanced differences necessary for tasks demanding a more detailed perception. In response to these limitations, we introduce Negative Augmented Samples(NAS), a refined vision-language pretraining model that innovatively incorporates NAS to specifically address the challenge of fine-grained understanding. NAS utilizes a Visual Dictionary(VD) as a semantic bridge between visual and linguistic domains. Additionally, it employs a Negative Visual Augmentation(NVA) method based on the VD to generate challenging negative image samples. These samples deviate from positive samples exclusively at the token level, thereby necessitating that the model discerns the subtle disparities between positive and negative samples with greater precision. Comprehensive experiments validate the efficacy of NAS components and underscore its potential to enhance fine-grained vision-language comprehension.
MoDULA: Mixture of Domain-Specific and Universal LoRA for Multi-Task Learning
Dec 10, 2024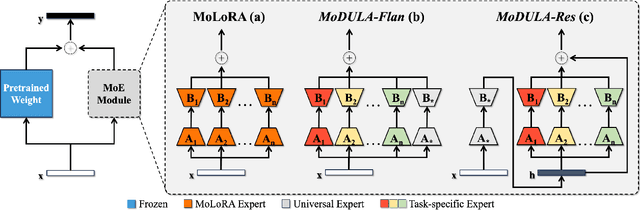
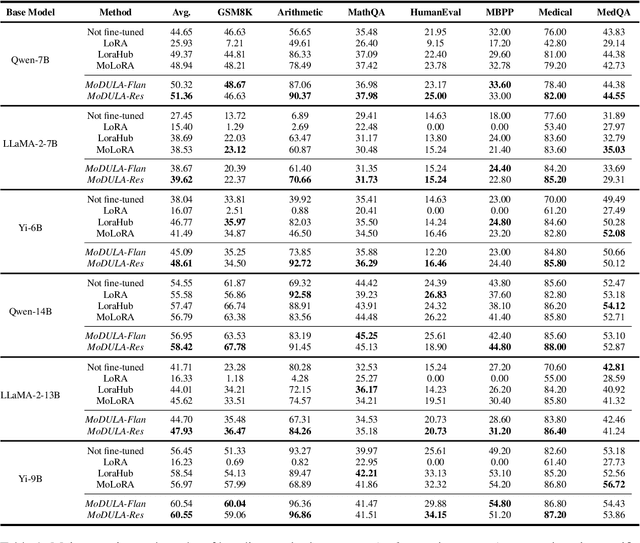
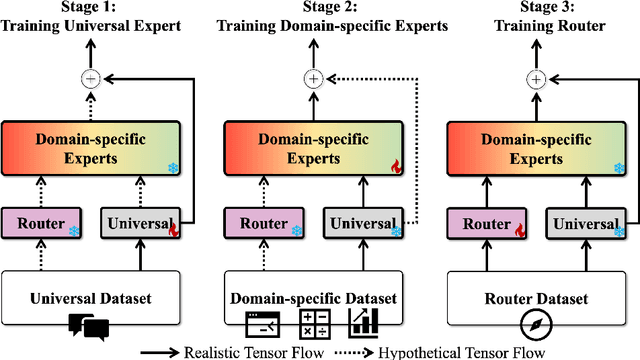
The growing demand for larger-scale models in the development of \textbf{L}arge \textbf{L}anguage \textbf{M}odels (LLMs) poses challenges for efficient training within limited computational resources. Traditional fine-tuning methods often exhibit instability in multi-task learning and rely heavily on extensive training resources. Here, we propose MoDULA (\textbf{M}ixture \textbf{o}f \textbf{D}omain-Specific and \textbf{U}niversal \textbf{L}oR\textbf{A}), a novel \textbf{P}arameter \textbf{E}fficient \textbf{F}ine-\textbf{T}uning (PEFT) \textbf{M}ixture-\textbf{o}f-\textbf{E}xpert (MoE) paradigm for improved fine-tuning and parameter efficiency in multi-task learning. The paradigm effectively improves the multi-task capability of the model by training universal experts, domain-specific experts, and routers separately. MoDULA-Res is a new method within the MoDULA paradigm, which maintains the model's general capability by connecting universal and task-specific experts through residual connections. The experimental results demonstrate that the overall performance of the MoDULA-Flan and MoDULA-Res methods surpasses that of existing fine-tuning methods on various LLMs. Notably, MoDULA-Res achieves more significant performance improvements in multiple tasks while reducing training costs by over 80\% without losing general capability. Moreover, MoDULA displays flexible pluggability, allowing for the efficient addition of new tasks without retraining existing experts from scratch. This progressive training paradigm circumvents data balancing issues, enhancing training efficiency and model stability. Overall, MoDULA provides a scalable, cost-effective solution for fine-tuning LLMs with enhanced parameter efficiency and generalization capability.
MLoRA: Multi-Domain Low-Rank Adaptive Network for CTR Prediction
Aug 14, 2024



Click-through rate (CTR) prediction is one of the fundamental tasks in the industry, especially in e-commerce, social media, and streaming media. It directly impacts website revenues, user satisfaction, and user retention. However, real-world production platforms often encompass various domains to cater for diverse customer needs. Traditional CTR prediction models struggle in multi-domain recommendation scenarios, facing challenges of data sparsity and disparate data distributions across domains. Existing multi-domain recommendation approaches introduce specific-domain modules for each domain, which partially address these issues but often significantly increase model parameters and lead to insufficient training. In this paper, we propose a Multi-domain Low-Rank Adaptive network (MLoRA) for CTR prediction, where we introduce a specialized LoRA module for each domain. This approach enhances the model's performance in multi-domain CTR prediction tasks and is able to be applied to various deep-learning models. We evaluate the proposed method on several multi-domain datasets. Experimental results demonstrate our MLoRA approach achieves a significant improvement compared with state-of-the-art baselines. Furthermore, we deploy it in the production environment of the Alibaba.COM. The online A/B testing results indicate the superiority and flexibility in real-world production environments. The code of our MLoRA is publicly available.
General2Specialized LLMs Translation for E-commerce
Mar 06, 2024Existing Neural Machine Translation (NMT) models mainly handle translation in the general domain, while overlooking domains with special writing formulas, such as e-commerce and legal documents. Taking e-commerce as an example, the texts usually include amounts of domain-related words and have more grammar problems, which leads to inferior performances of current NMT methods. To address these problems, we collect two domain-related resources, including a set of term pairs (aligned Chinese-English bilingual terms) and a parallel corpus annotated for the e-commerce domain. Furthermore, we propose a two-step fine-tuning paradigm (named G2ST) with self-contrastive semantic enhancement to transfer one general NMT model to the specialized NMT model for e-commerce. The paradigm can be used for the NMT models based on Large language models (LLMs). Extensive evaluations on real e-commerce titles demonstrate the superior translation quality and robustness of our G2ST approach, as compared with state-of-the-art NMT models such as LLaMA, Qwen, GPT-3.5, and even GPT-4.
Bilateral Reference for High-Resolution Dichotomous Image Segmentation
Jan 07, 2024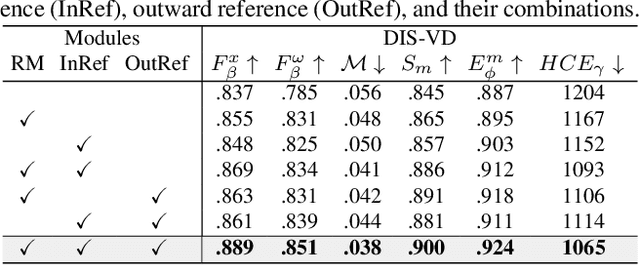
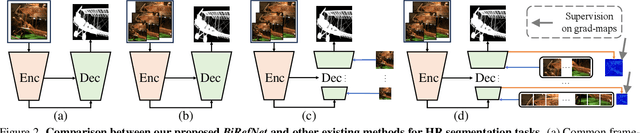
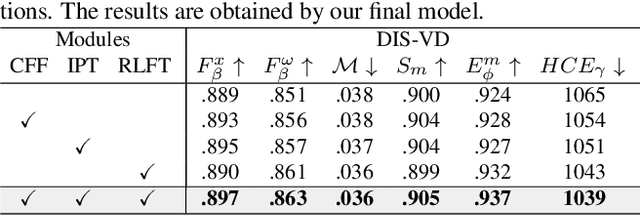
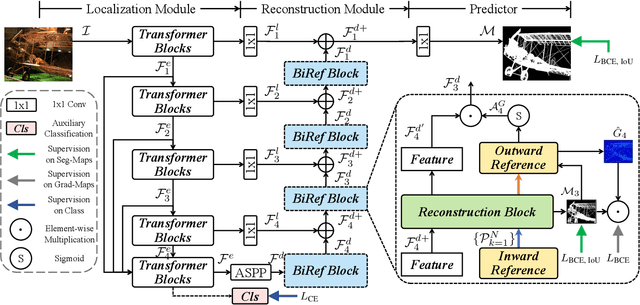
We introduce a novel bilateral reference framework (***BiRefNet***) for high-resolution dichotomous image segmentation (DIS). It comprises two essential components: the localization module (LM) and the reconstruction module (RM) with our proposed bilateral reference (BiRef). The LM aids in object localization using global semantic information. Within the RM, we utilize BiRef for the reconstruction process, where hierarchical patches of images provide the source reference and gradient maps serve as the target reference. These components collaborate to generate the final predicted maps. We also introduce auxiliary gradient supervision to enhance focus on regions with finer details. Furthermore, we outline practical training strategies tailored for DIS to improve map quality and training process. To validate the general applicability of our approach, we conduct extensive experiments on four tasks to evince that *BiRefNet* exhibits remarkable performance, outperforming task-specific cutting-edge methods across all benchmarks.