 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiralFormer: Looped Transformers Can Learn Hierarchical Dependencies via Multi-Resolution Recursion
Feb 12, 2026Recursive (looped) Transformers decouple computational depth from parameter depth by repeatedly applying shared layers, providing an explicit architectural primitive for iterative refinement and latent reasoning. However, early looped Transformers often underperform non-recursive baselines of equal compute. While recent literature has introduced more effective recursion mechanisms to mitigate this gap, existing architectures still operate at a fixed, full-token resolution, neglecting the potential efficiency of computing over compressed latent representations. In this paper, we propose SpiralFormer, a looped Transformer that executes recurrence under a multi-resolution recursion schedule. We provide probing evidence that multi-resolution recursion enables the model to learn hierarchical dependencies by inducing iteration-wise functional specialization across different scales. Empirically, SpiralFormer achieves better parameter and compute efficiency than both looped and non-looped baselines across model scales from 160M to 1.4B, establishing sequence resolution as a potential axis for scaling recursive architectures.
Reasoning Palette: Modulating Reasoning via Latent Contextualization for Controllable Exploration for (V)LMs
Dec 19, 2025



Exploration capacity shapes both inference-time performance and reinforcement learning (RL) training for large (vision-) language models, as stochastic sampling often yields redundant reasoning paths with little high-level diversity. This paper proposes Reasoning Palette, a novel latent-modulation framework that endows the model with a stochastic latent variable for strategic contextualization, guiding its internal planning prior to token generation. This latent context is inferred from the mean-pooled embedding of a question-answer pair via a variational autoencoder (VAE), where each sampled latent potentially encodes a distinct reasoning context. During inference, a sampled latent is decoded into learnable token prefixes and prepended to the input prompt, modulating the model's internal reasoning trajectory. In this way, the model performs internal sampling over reasoning strategies prior to output generation, which shapes the style and structure of the entire response sequence. A brief supervised fine-tuning (SFT) warm-up phase allows the model to adapt to this latent conditioning. Within RL optimization, Reasoning Palette facilitates structured exploration by enabling on-demand injection for diverse reasoning modes, significantly enhancing exploration efficiency and sustained learning capability. Experiments across multiple reasoning benchmarks demonstrate that our method enables interpretable and controllable control over the (vision-) language model's strategic behavior, thereby achieving consistent performance gains over standard RL methods.
MeSH: Memory-as-State-Highways for Recursive Transformers
Oct 09, 2025Recursive transformers reuse parameters and iterate over hidden states multiple times, decoupling compute depth from parameter depth. However, under matched compute, recursive models with fewer parameters often lag behind non-recursive counterparts. By probing hidden states, we trace this performance gap to two primary bottlenecks: undifferentiated computation, where the core is forced to adopt a similar computational pattern at every iteration, and information overload, where long-lived and transient information must coexist in a single hidden state. To address the issues, we introduce a Memory-as-State-Highways (MeSH) scheme, which externalizes state management into an explicit memory buffer and employs lightweight routers to dynamically diversify computation across iterations. Probing visualizations confirm that MeSH successfully resolves the pathologies by inducing functional specialization across iterations. On the Pythia suite (160M-1.4B), MeSH-enhanced recursive transformers consistently improve over recursive baselines and outperforms its larger non-recursive counterpart at the 1.4B scale, improving average downstream accuracy by +1.06% with 33% fewer non-embedding parameters. Our analysis establishes MeSH as a scalable and principled architecture for building stronger recursive models.
ASPO: Adaptive Sentence-Level Preference Optimization for Fine-Grained Multimodal Reasoning
May 25, 2025Direct Preference Optimization (DPO) has gained significant attention for its simplicity and computational efficiency in aligning large language models (LLMs). Recent advancements have extended DPO to multimodal scenarios, achieving strong performance. However, traditional DPO relies on binary preference optimization, rewarding or penalizing entire responses without considering fine-grained segment correctness, leading to suboptimal solutions. The root of this issue lies in the absence of fine-grained supervision during the optimization process. To address this, we propose Adaptive Sentence-level Preference Optimization (ASPO), which evaluates individual sentences for more precise preference optimization. By dynamically calculating adaptive rewards at the sentence level based on model predictions, ASPO enhances response content assessment without additional models or parameters. This significantly improves the alignment of multimodal features. Extensive experiments show that ASPO substantially enhances the overall performance of multimodal models.
CoF: Coarse to Fine-Grained Image Understanding for Multi-modal Large Language Models
Dec 22, 2024



The impressive performance of Large Language Model (LLM) has prompted researchers to develop Multi-modal LLM (MLLM), which has shown great potential for various multi-modal tasks. However, current MLLM often struggles to effectively address fine-grained multi-modal challenges. We argue that this limitation is closely linked to the models' visual grounding capabilities. The restricted spatial awareness and perceptual acuity of visual encoders frequently lead to interference from irrelevant background information in images, causing the models to overlook subtle but crucial details. As a result, achieving fine-grained regional visual comprehension becomes difficult. In this paper, we break down multi-modal understanding into two stages, from Coarse to Fine (CoF). In the first stage, we prompt the MLLM to locate the approximate area of the answer. In the second stage, we further enhance the model's focus on relevant areas within the image through visual prompt engineering, adjusting attention weights of pertinent regions. This, in turn, improves both visual grounding and overall performance in downstream tasks. Our experiments show that this approach significantly boosts the performance of baseline models, demonstrating notable generalization and effectiveness. Our CoF approach is available online at https://github.com/Gavin001201/CoF.
HIP: Hierarchical Point Modeling and Pre-training for Visual Information Extraction
Nov 02, 2024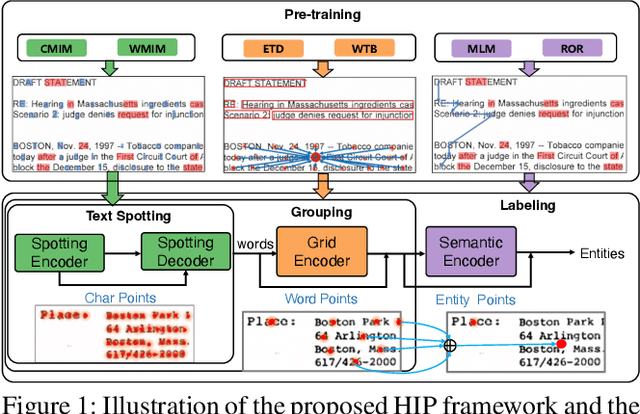



End-to-end visual information extraction (VIE) aims at integrating the hierarchical subtasks of VIE, including text spotting, word grouping, and entity labeling, into a unified framework. Dealing with the gaps among the three subtasks plays a pivotal role in designing an effective VIE model. OCR-dependent methods heavily rely on offline OCR engines and inevitably suffer from OCR errors, while OCR-free methods, particularly those employing a black-box model, might produce outputs that lack interpretability or contain hallucinated content. Inspired by CenterNet, DeepSolo, and ESP, we propose HIP, which models entities as HIerarchical Points to better conform to the hierarchical nature of the end-to-end VIE task. Specifically, such hierarchical points can be flexibly encoded and subsequently decoded into desired text transcripts, centers of various regions, and categories of entities. Furthermore, we devise corresponding hierarchical pre-training strategies, categorized as image reconstruction, layout learning, and language enhancement, to reinforce the cross-modality representation of the hierarchical encoders. Quantitative experiments on public benchmarks demonstrate that HIP outperforms previous state-of-the-art methods, while qualitative results show its excellent interpretability.
LORE++: Logical Location Regression Network for Table Structure Recognition with Pre-training
Jan 03, 2024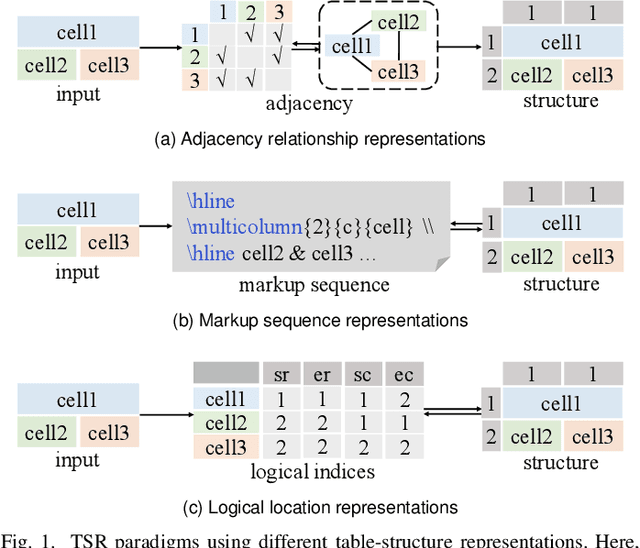

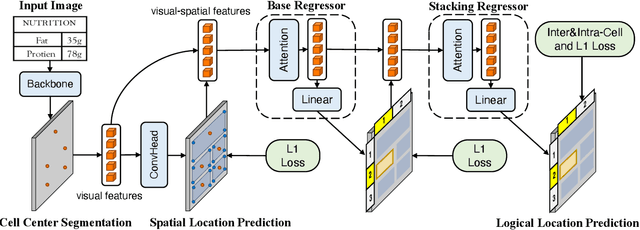
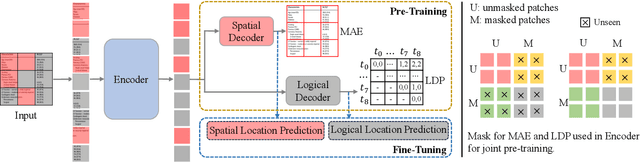
Table structure recognition (TSR) aims at extracting tables in images into machine-understandable formats. Recent methods solve this problem by predicting the adjacency relations of detected cell boxes or learning to directly generate the corresponding markup sequences from the table images. However, existing approaches either count on additional heuristic rules to recover the table structures, or face challenges in capturing long-range dependencies within tables, resulting in increased complexity. In this paper, we propose an alternative paradigm. We model TSR as a logical location regression problem and propose a new TSR framework called LORE, standing for LOgical location REgression network, which for the first time regresses logical location as well as spatial location of table cells in a unified network. Our proposed LORE is conceptually simpler, easier to train, and more accurate than other paradigms of TSR. Moreover, inspired by the persuasive success of pre-trained models on a number of computer vision and natural language processing tasks, we propose two pre-training tasks to enrich the spatial and logical representations at the feature level of LORE, resulting in an upgraded version called LORE++. The incorporation of pre-training in LORE++ has proven to enjoy significant advantages, leading to a substantial enhancement in terms of accuracy, generalization, and few-shot capability compared to its predecessor. Experiments on standard benchmarks against methods of previous paradigms demonstrate the superiority of LORE++, which highlights the potential and promising prospect of the logical location regression paradigm for TSR.
Modeling Entities as Semantic Points for Visual Information Extraction in the Wild
Mar 29, 2023



Recently, Visual Information Extraction (VIE) has been becoming increasingly important in both the academia and industry, due to the wide range of real-world applications. Previously, numerous works have been proposed to tackle this problem. However, the benchmarks used to assess these methods are relatively plain, i.e., scenarios with real-world complexity are not fully represented in these benchmarks. As the first contribution of this work, we curate and release a new dataset for VIE, in which the document images are much more challenging in that they are taken from real applications, and difficulties such as blur, partial occlusion, and printing shift are quite common. All these factors may lead to failures in information extraction. Therefore, as the second contribution, we explore an alternative approach to precisely and robustly extract key information from document images under such tough conditions. Specifically, in contrast to previous methods, which usually either incorporate visual information into a multi-modal architecture or train text spotting and information extraction in an end-to-end fashion, we explicitly model entities as semantic points, i.e., center points of entities are enriched with semantic information describing the attributes and relationships of different entities, which could largely benefit entity labeling and linking. Extensive experiments on standard benchmarks in this field as well as the proposed dataset demonstrate that the proposed method can achieve significantly enhanced performance on entity labeling and linking, compared with previous state-of-the-art models. Dataset is available at https://www.modelscope.cn/datasets/damo/SIBR/summary.
LORE: Logical Location Regression Network for Table Structure Recognition
Mar 07, 2023



Table structure recognition (TSR) aims at extracting tables in images into machine-understandable formats. Recent methods solve this problem by predicting the adjacency relations of detected cell boxes, or learning to generate the corresponding markup sequences from the table images. However, they either count on additional heuristic rules to recover the table structures, or require a huge amount of training data and time-consuming sequential decoders. In this paper, we propose an alternative paradigm. We model TSR as a logical location regression problem and propose a new TSR framework called LORE, standing for LOgical location REgression network, which for the first time combines logical location regression together with spatial location regression of table cells. Our proposed LORE is conceptually simpler, easier to train and more accurate than previous TSR models of other paradigms. Experiments on standard benchmarks demonstrate that LORE consistently outperforms prior arts. Code is available at https:// github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LORE-TSR.
Revisiting Document Image Dewarping by Grid Regularization
Mar 31, 2022

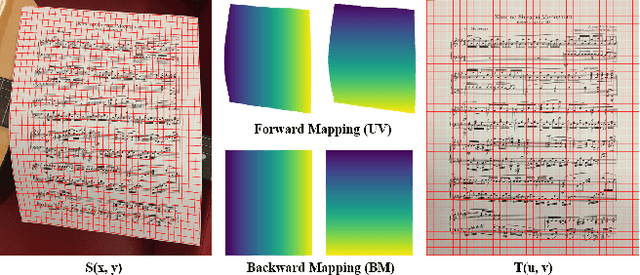
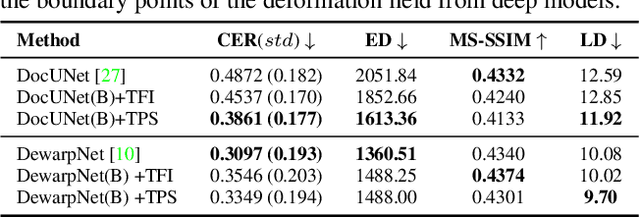
This paper addresses the problem of document image dewarping, which aims at eliminating the geometric distortion in document images for document digitization. Instead of designing a better neural network to approximate the optical flow fields between the inputs and outputs, we pursue the best readability by taking the text lines and the document boundaries into account from a constrained optimization perspective. Specifically, our proposed method first learns the boundary points and the pixels in the text lines and then follows the most simple observation that the boundaries and text lines in both horizontal and vertical directions should be kept after dewarping to introduce a novel grid regularization scheme. To obtain the final forward mapping for dewarping, we solve an optimization problem with our proposed grid regularization. The experiments comprehensively demonstrate that our proposed approach outperforms the prior arts by large margins in terms of readability (with the metrics of Character Errors Rate and the Edit Distance) while maintaining the best image quality on the publicly-available DocUNet benchmark.