 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIP: Hierarchical Point Modeling and Pre-training for Visual Information Extraction
Paper and Code
Nov 02, 2024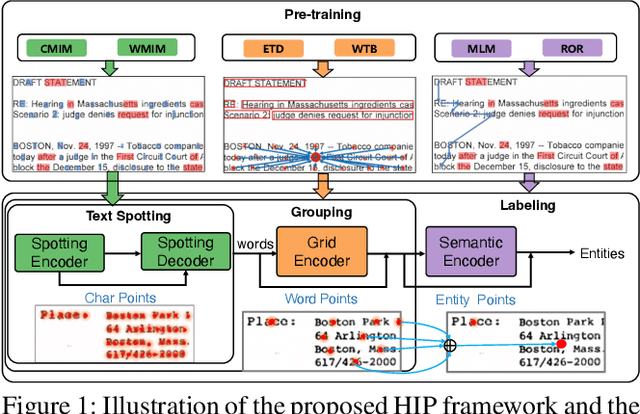



End-to-end visual information extraction (VIE) aims at integrating the hierarchical subtasks of VIE, including text spotting, word grouping, and entity labeling, into a unified framework. Dealing with the gaps among the three subtasks plays a pivotal role in designing an effective VIE model. OCR-dependent methods heavily rely on offline OCR engines and inevitably suffer from OCR errors, while OCR-free methods, particularly those employing a black-box model, might produce outputs that lack interpretability or contain hallucinated content. Inspired by CenterNet, DeepSolo, and ESP, we propose HIP, which models entities as HIerarchical Points to better conform to the hierarchical nature of the end-to-end VIE task. Specifically, such hierarchical points can be flexibly encoded and subsequently decoded into desired text transcripts, centers of various regions, and categories of entities. Furthermore, we devise corresponding hierarchical pre-training strategies, categorized as image reconstruction, layout learning, and language enhancement, to reinforce the cross-modality representation of the hierarchical encoders. Quantitative experiments on public benchmarks demonstrate that HIP outperforms previous state-of-the-art methods, while qualitative results show its excellent interpretability.