 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral entropy prior-guided deep feature fusion architecture for magnetic core loss
Dec 12, 2025Accurate core loss modeling is critical for the design of high-efficiency power electronic systems. Traditional core loss modeling methods have limitations in prediction accuracy. To advance this field, the IEEE Power Electronics Society launched the MagNet Challenge in 2023, the first international competition focused on data-driven power electronics design methods, aiming to uncover complex loss patterns in magnetic components through a data-driven paradigm. Although purely data-driven models demonstrate strong fitting performance, their interpretability and cross-distribution generalization capabilities remain limited. To address these issues, this paper proposes a hybrid model, SEPI-TFPNet, which integrates empirical models with deep learning. The physical-prior submodule employs a spectral entropy discrimination mechanism to select the most suitable empirical model under different excitation waveforms. The data-driven submodule incorporates convolutional neural networks, multi-head attention mechanisms, and bidirectional long short-term memory networks to extract flux-density time-series features. An adaptive feature fusion module is introduced to improve multimodal feature interaction and integration. Using the MagNet dataset containing various magnetic materials, this paper evaluates the proposed method and compares it with 21 representative models from the 2023 challenge and three advanced methods from 2024-2025. The results show that the proposed method achieves improved modeling accuracy and robustness.
Generative Compositor for Few-Shot Visual Information Extraction
Mar 21, 2025Visual Information Extraction (VIE), aiming at extracting structured information from visually rich document images, plays a pivotal role in document processing. Considering various layouts, semantic scopes, and languages, VIE encompasses an extensive range of types, potentially numbering in the thousands. However, many of these types suffer from a lack of training data, which poses significant challenges. In this paper, we propose a novel generative model, named Generative Compositor, to address the challenge of few-shot VIE. The Generative Compositor is a hybrid pointer-generator network that emulates the operations of a compositor by retrieving words from the source text and assembling them based on the provided prompts. Furthermore, three pre-training strategies are employed to enhance the model's perception of spatial context information. Besides, a prompt-aware resampler is specially designed to enable efficient matching by leveraging the entity-semantic prior contained in prompts. The introduction of the prompt-based retrieval mechanism and the pre-training strategies enable the model to acquire more effective spatial and semantic clues with limited training samples. Experiments demonstrate that the proposed method achieves highly competitive results in the full-sample training, while notably outperforms the baseline in the 1-shot, 5-shot, and 10-shot settings.
HIP: Hierarchical Point Modeling and Pre-training for Visual Information Extraction
Nov 02, 2024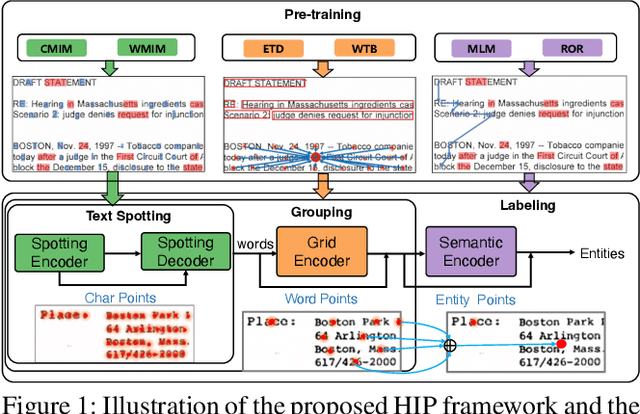



End-to-end visual information extraction (VIE) aims at integrating the hierarchical subtasks of VIE, including text spotting, word grouping, and entity labeling, into a unified framework. Dealing with the gaps among the three subtasks plays a pivotal role in designing an effective VIE model. OCR-dependent methods heavily rely on offline OCR engines and inevitably suffer from OCR errors, while OCR-free methods, particularly those employing a black-box model, might produce outputs that lack interpretability or contain hallucinated content. Inspired by CenterNet, DeepSolo, and ESP, we propose HIP, which models entities as HIerarchical Points to better conform to the hierarchical nature of the end-to-end VIE task. Specifically, such hierarchical points can be flexibly encoded and subsequently decoded into desired text transcripts, centers of various regions, and categories of entities. Furthermore, we devise corresponding hierarchical pre-training strategies, categorized as image reconstruction, layout learning, and language enhancement, to reinforce the cross-modality representation of the hierarchical encoders. Quantitative experiments on public benchmarks demonstrate that HIP outperforms previous state-of-the-art methods, while qualitative results show its excellent interpretability.
VL-Reader: Vision and Language Reconstructor is an Effective Scene Text Recognizer
Sep 18, 2024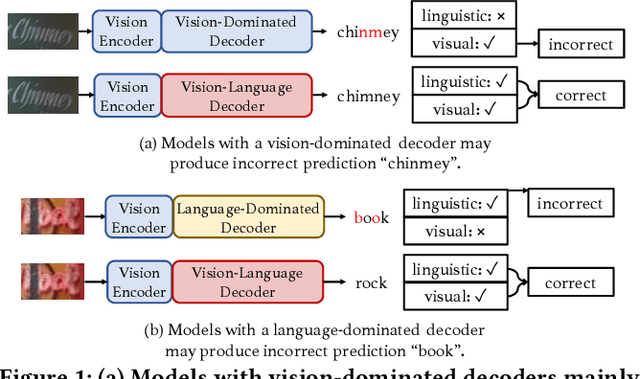
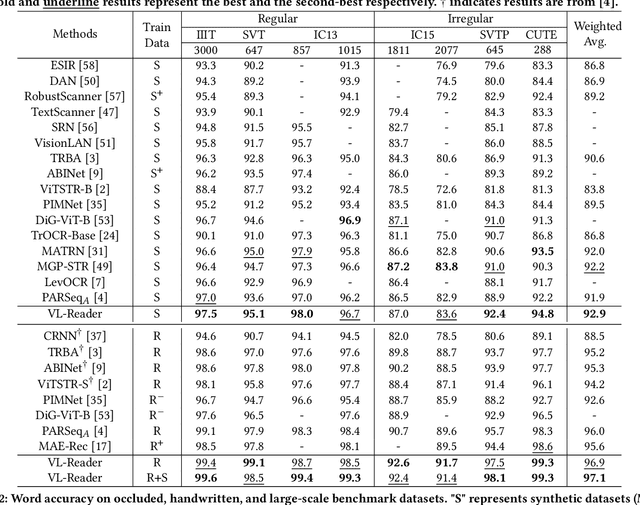

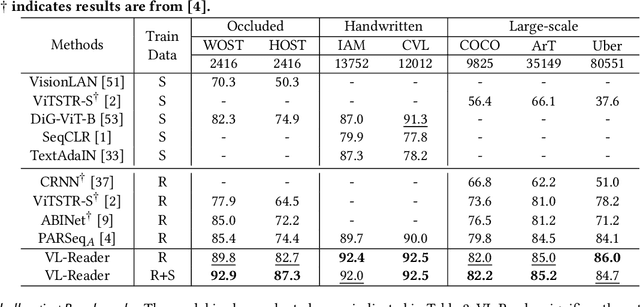
Text recognition is an inherent integration of vision and language, encompassing the visual texture in stroke patterns and the semantic context among the character sequences. Towards advanced text recognition, there are three key challenges: (1) an encoder capable of representing the visual and semantic distributions; (2) a decoder that ensures the alignment between vision and semantics; and (3) consistency in the framework during pre-training, if it exists, and fine-tuning. Inspired by masked autoencoding, a successful pre-training strategy in both vision and language, we propose an innovative scene text recognition approach, named VL-Reader. The novelty of the VL-Reader lies in the pervasive interplay between vision and language throughout the entire process. Concretely, we first introduce a Masked Visual-Linguistic Reconstruction (MVLR) objective, which aims at simultaneously modeling visual and linguistic information. Then, we design a Masked Visual-Linguistic Decoder (MVLD) to further leverage masked vision-language context and achieve bi-modal feature interaction. The architecture of VL-Reader maintains consistency from pre-training to fine-tuning. In the pre-training stage, VL-Reader reconstructs both masked visual and text tokens, while in the fine-tuning stage, the network degrades to reconstruct all characters from an image without any masked regions. VL-reader achieves an average accuracy of 97.1% on six typical datasets, surpassing the SOTA by 1.1%. The improvement was even more significant on challenging datasets. The results demonstrate that vision and language reconstructor can serve as an effective scene text recognizer.
Platypus: A Generalized Specialist Model for Reading Text in Various Forms
Aug 27, 2024



Reading text from images (either natural scenes or documents) has been a long-standing research topic for decades, due to the high technical challenge and wide application range. Previously, individual specialist models are developed to tackle the sub-tasks of text reading (e.g., scene text recognition, handwritten text recognition and mathematical expression recognition). However, such specialist models usually cannot effectively generalize across different sub-tasks. Recently, generalist models (such as GPT-4V), trained on tremendous data in a unified way, have shown enormous potential in reading text in various scenarios, but with the drawbacks of limited accuracy and low efficiency. In this work, we propose Platypus, a generalized specialist model for text reading. Specifically, Platypus combines the best of both worlds: being able to recognize text of various forms with a single unified architecture, while achieving excellent accuracy and high efficiency. To better exploit the advantage of Platypus, we also construct a text reading dataset (called Worms), the images of which are curated from previous datasets and partially re-labeled. Experiments on standard benchmarks demonstrate the effectiveness and superiority of the proposed Platypus model. Model and data will be made publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/Platypus.
WebRPG: Automatic Web Rendering Parameters Generation for Visual Presentation
Jul 22, 2024
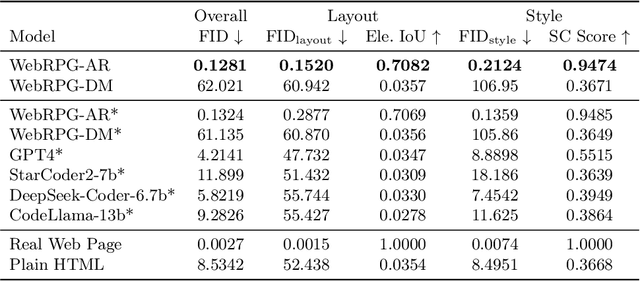


In the era of content creation revolution propelled by advancements in generative models, the field of web design remains unexplored despite its critical role in modern digital communication. The web design process is complex and often time-consuming, especially for those with limited expertise. In this paper, we introduce Web Rendering Parameters Generation (WebRPG), a new task that aims at automating the generation for visual presentation of web pages based on their HTML code. WebRPG would contribute to a faster web development workflow. Since there is no existing benchmark available, we develop a new dataset for WebRPG through an automated pipeline. Moreover, we present baseline models, utilizing VAE to manage numerous elements and rendering parameters, along with custom HTML embedding for capturing essential semantic and hierarchical information from HTML. Extensive experiments, including customized quantitative evaluations for this specific task, are conducted to evaluate the quality of the generated results.
Visual Text Generation in the Wild
Jul 19, 2024



Recently, with the rapid advancements of generative models, the field of visual text generation has witnessed significant progress. However, it is still challenging to render high-quality text images in real-world scenarios, as three critical criteria should be satisfied: (1) Fidelity: the generated text images should be photo-realistic and the contents are expected to be the same as specified in the given conditions; (2) Reasonability: the regions and contents of the generated text should cohere with the scene; (3) Utility: the generated text images can facilitate related tasks (e.g., text detection and recognition). Upon investigation, we find that existing methods, either rendering-based or diffusion-based, can hardly meet all these aspects simultaneously, limiting their application range. Therefore, we propose in this paper a visual text generator (termed SceneVTG), which can produce high-quality text images in the wild. Following a two-stage paradigm, SceneVTG leverages a Multimodal Large Language Model to recommend reasonable text regions and contents across multiple scales and levels, which are used by a conditional diffusion model as conditions to generate text images. Extensive experiments demonstrate that the proposed SceneVTG significantly outperforms traditional rendering-based methods and recent diffusion-based methods in terms of fidelity and reasonability. Besides, the generated images provide superior utility for tasks involving text detection and text recognition. Code and datasets are available at AdvancedLiterateMachinery.
ProcTag: Process Tagging for Assessing the Efficacy of Document Instruction Data
Jul 17, 2024

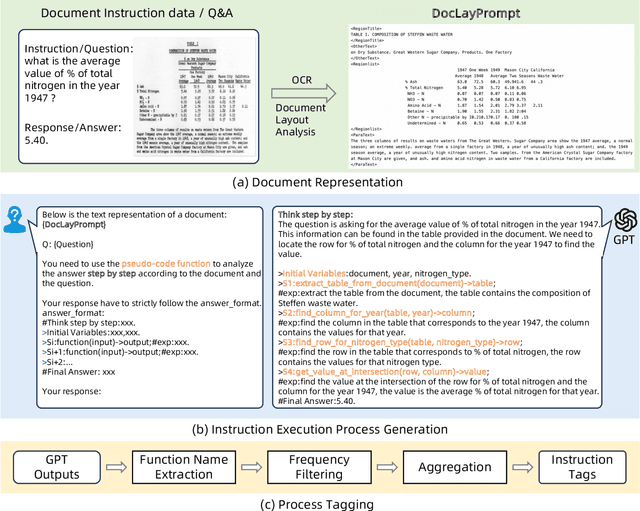

Recently, large language models (LLMs) and multimodal large language models (MLLMs) have demonstrated promising results on document visual question answering (VQA) task, particularly after training on document instruction datasets. An effective evaluation method for document instruction data is crucial in constructing instruction data with high efficacy, which, in turn, facilitates the training of LLMs and MLLMs for document VQA. However, most existing evaluation methods for instruction data are limited to the textual content of the instructions themselves, thereby hindering the effective assessment of document instruction datasets and constraining their construction. In this paper, we propose ProcTag, a data-oriented method that assesses the efficacy of document instruction data. ProcTag innovatively performs tagging on the execution process of instructions rather than the instruction text itself. By leveraging the diversity and complexity of these tags to assess the efficacy of the given dataset, ProcTag enables selective sampling or filtering of document instructions. Furthermore, DocLayPrompt, a novel semi-structured layout-aware document prompting strategy, is proposed for effectively representing documents. Experiments demonstrate that sampling existing open-sourced and generated document VQA/instruction datasets with ProcTag significantly outperforms current methods for evaluating instruction data. Impressively, with ProcTag-based sampling in the generated document datasets, only 30.5\% of the document instructions are required to achieve 100\% efficacy compared to the complete dataset. The code is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/ProcTag.
LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding
Apr 08, 2024Recently, leveraging large language models (LLMs) or multimodal large language models (MLLMs) for document understanding has been proven very promising. However, previous works that employ LLMs/MLLMs for document understanding have not fully explored and utilized the document layout information, which is vital for precise document understanding. In this paper, we propose LayoutLLM, an LLM/MLLM based method for document understanding. The core of LayoutLLM is a layout instruction tuning strategy, which is specially designed to enhance the comprehension and utilization of document layouts. The proposed layout instruction tuning strategy consists of two components: Layout-aware Pre-training and Layout-aware Supervised Fine-tuning. To capture the characteristics of document layout in Layout-aware Pre-training, three groups of pre-training tasks, corresponding to document-level, region-level and segment-level information, are introduced. Furthermore, a novel module called layout chain-of-thought (LayoutCoT) is devised to enable LayoutLLM to focus on regions relevant to the question and generate accurate answers. LayoutCoT is effective for boosting the performance of document understanding. Meanwhile, it brings a certain degree of interpretability, which could facilitate manual inspection and correction. Experiments on standard benchmarks show that the proposed LayoutLLM significantly outperforms existing methods that adopt open-source 7B LLMs/MLLMs for document understanding. The training data of the LayoutLLM is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LayoutLLM
OmniParser: A Unified Framework for Text Spotting, Key Information Extraction and Table Recognition
Mar 28, 2024Recently, visually-situated text parsing (VsTP) has experienced notable advancements, driven by the increasing demand for automated document understanding and the emergence of Generative Large Language Models (LLMs) capable of processing document-based questions. Various methods have been proposed to address the challenging problem of VsTP. However, due to the diversified targets and heterogeneous schemas, previous works usually design task-specific architectures and objectives for individual tasks, which inadvertently leads to modal isolation and complex workflow. In this paper, we propose a unified paradigm for parsing visually-situated text across diverse scenarios. Specifically, we devise a universal model, called OmniParser, which can simultaneously handle three typical visually-situated text parsing tasks: text spotting, key information extraction, and table recognition. In OmniParser, all tasks share the unified encoder-decoder architecture, the unified objective: point-conditioned text generation, and the unified input & output representation: prompt & structured sequences. Extensive experiments demonstrate that the proposed OmniParser achieves state-of-the-art (SOTA) or highly competitive performances on 7 datasets for the three visually-situated text parsing tasks, despite its unified, concise design. The code is available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery.