 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC-OCR V2: Benchmarking Large Multimodal Models for Literacy in Real-world Document Processing
May 05, 2026Large Multimodal Models (LMMs) have recently shown strong performance on Optical Character Recognition (OCR) tasks, demonstrating their promising capability in document literacy. However, their effectiveness in real-world applications remains underexplored, as existing benchmarks adopt task scopes misaligned with practical applications and assume homogeneous acquisition conditions. To address this gap, we introduce CC-OCR V2, a comprehensive and challenging OCR benchmark tailored to real-world document processing. CC-OCR V2 focuses on practical enterprise document processing tasks and incorporates hard and corner cases that are critical yet underrepresented in prior benchmarks, covering 5 major OCR-centric tracks: text recognition, document parsing, document grounding, key information extraction, and document question answering, comprising 7,093 high-difficulty samples. Extensive experiments on 14 advanced LMMs reveal that current models fall short of real-world application requirements. Even state-of-the-art LMMs exhibit substantial performance degradation across diverse tasks and scenarios. These findings reveal a significant gap between performance on current benchmarks and effectiveness in real-world applications. We release the full dataset and evaluation toolkit at https://github.com/eioss/CC-OCR-V2.
CodePercept: Code-Grounded Visual STEM Perception for MLLMs
Mar 11, 2026When MLLMs fail at Science, Technology, Engineering, and Mathematics (STEM) visual reasoning, a fundamental question arises: is it due to perceptual deficiencies or reasoning limitations? Through systematic scaling analysis that independently scales perception and reasoning components, we uncover a critical insight: scaling perception consistently outperforms scaling reasoning. This reveals perception as the true lever limiting current STEM visual reasoning. Motivated by this insight, our work focuses on systematically enhancing the perception capabilities of MLLMs by establishing code as a powerful perceptual medium--executable code provides precise semantics that naturally align with the structured nature of STEM visuals. Specifically, we construct ICC-1M, a large-scale dataset comprising 1M Image-Caption-Code triplets that materializes this code-as-perception paradigm through two complementary approaches: (1) Code-Grounded Caption Generation treats executable code as ground truth for image captions, eliminating the hallucinations inherent in existing knowledge distillation methods; (2) STEM Image-to-Code Translation prompts models to generate reconstruction code, mitigating the ambiguity of natural language for perception enhancement. To validate this paradigm, we further introduce STEM2Code-Eval, a novel benchmark that directly evaluates visual perception in STEM domains. Unlike existing work relying on problem-solving accuracy as a proxy that only measures problem-relevant understanding, our benchmark requires comprehensive visual comprehension through executable code generation for image reconstruction, providing deterministic and verifiable assessment. Code is available at https://github.com/TongkunGuan/Qwen-CodePercept.
OmniParser V2: Structured-Points-of-Thought for Unified Visual Text Parsing and Its Generality to Multimodal Large Language Models
Feb 22, 2025Visually-situated text parsing (VsTP) has recently seen notable advancements, driven by the growing demand for automated document understanding and the emergence of large language models capable of processing document-based questions. While various methods have been proposed to tackle the complexities of VsTP, existing solutions often rely on task-specific architectures and objectives for individual tasks. This leads to modal isolation and complex workflows due to the diversified targets and heterogeneous schemas. In this paper, we introduce OmniParser V2, a universal model that unifies VsTP typical tasks, including text spotting, key information extraction, table recognition, and layout analysis, into a unified framework. Central to our approach is the proposed Structured-Points-of-Thought (SPOT) prompting schemas, which improves model performance across diverse scenarios by leveraging a unified encoder-decoder architecture, objective, and input\&output representation. SPOT eliminates the need for task-specific architectures and loss functions, significantly simplifying the processing pipeline. Our extensive evaluations across four tasks on eight different datasets show that OmniParser V2 achieves state-of-the-art or competitive results in VsTP. Additionally, we explore the integration of SPOT within a multimodal large language model structure, further enhancing text localization and recognition capabilities, thereby confirming the generality of SPOT prompting technique. The code is available at \href{https://github.com/AlibabaResearch/AdvancedLiterateMachinery}{AdvancedLiterateMachinery}.
Qwen2.5-VL Technical Report
Feb 19, 2025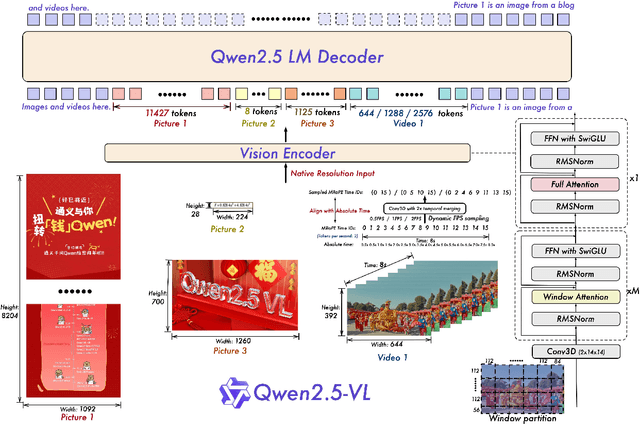
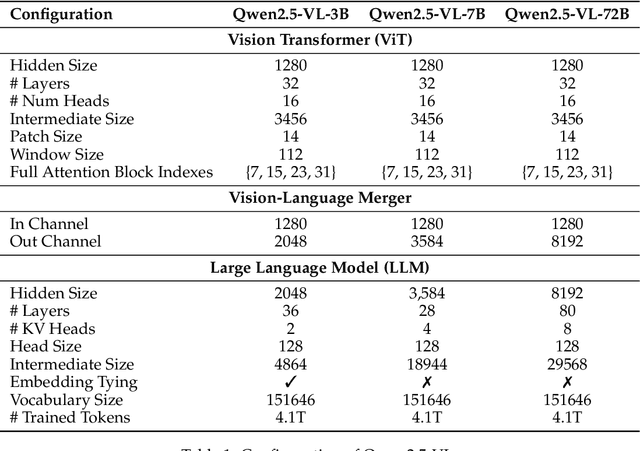
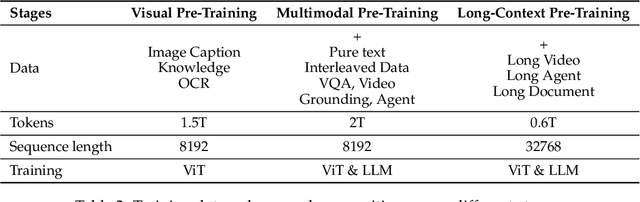
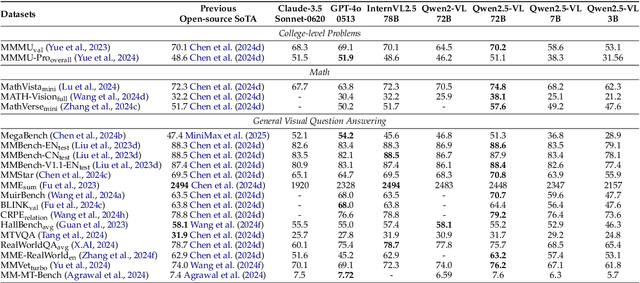
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy
Dec 03, 2024Large Multimodal Models (LMMs) have demonstrated impressive performance on recognizing document images with natural language instructions. However, it remains unclear to what extent capabilities in literacy with rich structure and fine-grained visual challenges. The current landscape lacks a comprehensive benchmark to effectively measure the literate capabilities of LMMs. Existing benchmarks are often limited by narrow scenarios and specified tasks. To this end, we introduce CC-OCR, a comprehensive benchmark that possess a diverse range of scenarios, tasks, and challenges. CC-OCR comprises four OCR-centric tracks: multi-scene text reading, multilingual text reading, document parsing, and key information extraction. It includes 39 subsets with 7,058 full annotated images, of which 41% are sourced from real applications, being released for the first time. Furthermore, we evaluate nine prominent LMMs and reveal both the strengths and weaknesses of these models, particularly in text grounding, multi-orientation, and hallucination of repetition. CC-OCR aims to comprehensively evaluate the capabilities of LMMs on OCR-centered tasks, driving advancement in LMMs.
OmniParser: A Unified Framework for Text Spotting, Key Information Extraction and Table Recognition
Mar 28, 2024Recently, visually-situated text parsing (VsTP) has experienced notable advancements, driven by the increasing demand for automated document understanding and the emergence of Generative Large Language Models (LLMs) capable of processing document-based questions. Various methods have been proposed to address the challenging problem of VsTP. However, due to the diversified targets and heterogeneous schemas, previous works usually design task-specific architectures and objectives for individual tasks, which inadvertently leads to modal isolation and complex workflow. In this paper, we propose a unified paradigm for parsing visually-situated text across diverse scenarios. Specifically, we devise a universal model, called OmniParser, which can simultaneously handle three typical visually-situated text parsing tasks: text spotting, key information extraction, and table recognition. In OmniParser, all tasks share the unified encoder-decoder architecture, the unified objective: point-conditioned text generation, and the unified input & output representation: prompt & structured sequences. Extensive experiments demonstrate that the proposed OmniParser achieves state-of-the-art (SOTA) or highly competitive performances on 7 datasets for the three visually-situated text parsing tasks, despite its unified, concise design. The code is available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery.
Vision-Language Pre-Training for Boosting Scene Text Detectors
Apr 29, 2022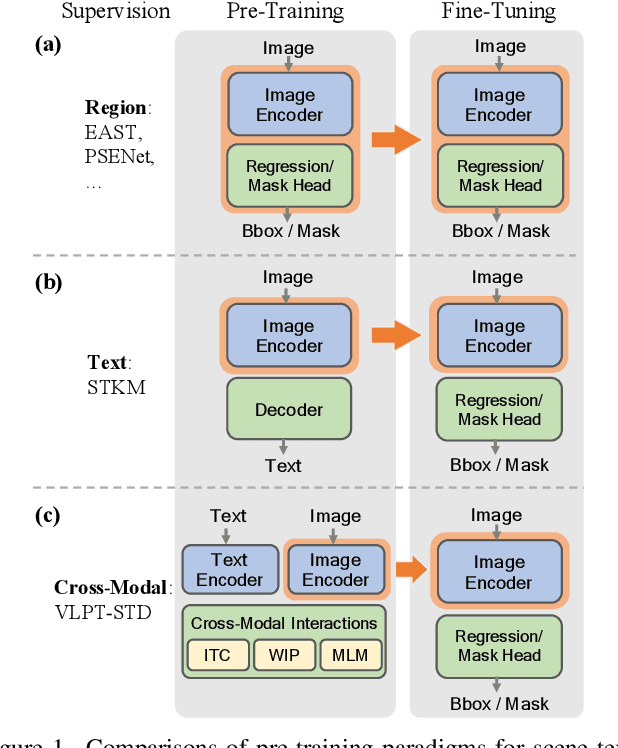
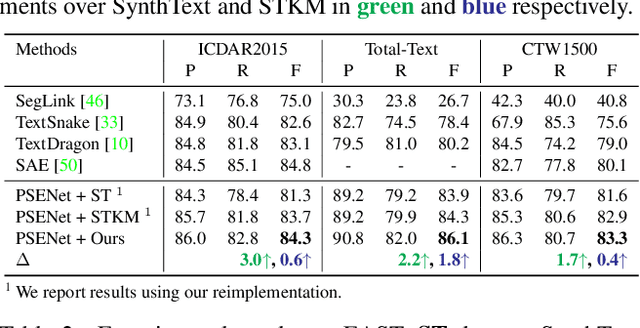
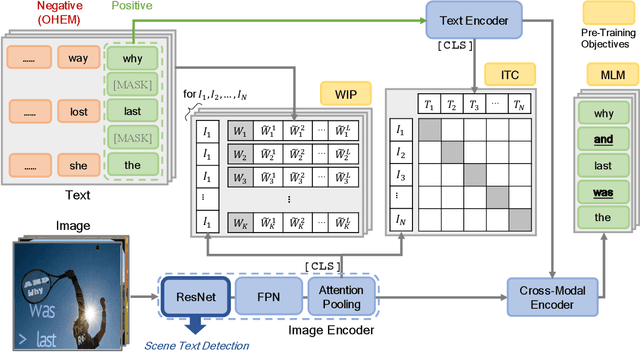
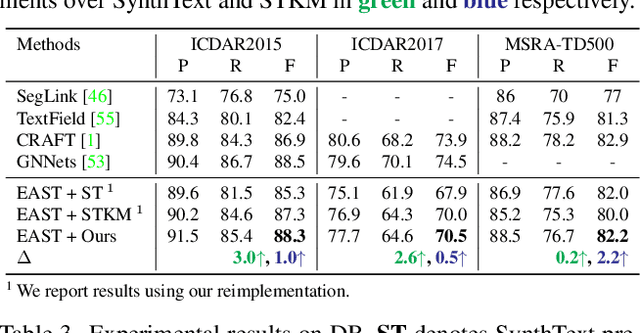
Recently, vision-language joint representation learning has proven to be highly effective in various scenarios. In this paper, we specifically adapt vision-language joint learning for scene text detection, a task that intrinsically involves cross-modal interaction between the two modalities: vision and language, since text is the written form of language. Concretely, we propose to learn contextualized, joint representations through vision-language pre-training, for the sake of enhancing the performance of scene text detectors. Towards this end, we devise a pre-training architecture with an image encoder, a text encoder and a cross-modal encoder, as well as three pretext tasks: image-text contrastive learning (ITC), masked language modeling (MLM) and word-in-image prediction (WIP). The pre-trained model is able to produce more informative representations with richer semantics, which could readily benefit existing scene text detectors (such as EAST and PSENet) in the down-stream text detection task. Extensive experiments on standard benchmarks demonstrate that the proposed paradigm can significantly improve the performance of various representative text detectors, outperforming previous pre-training approaches. The code and pre-trained models will be publicly released.
Super-BPD: Super Boundary-to-Pixel Direction for Fast Image Segmentation
May 30, 2020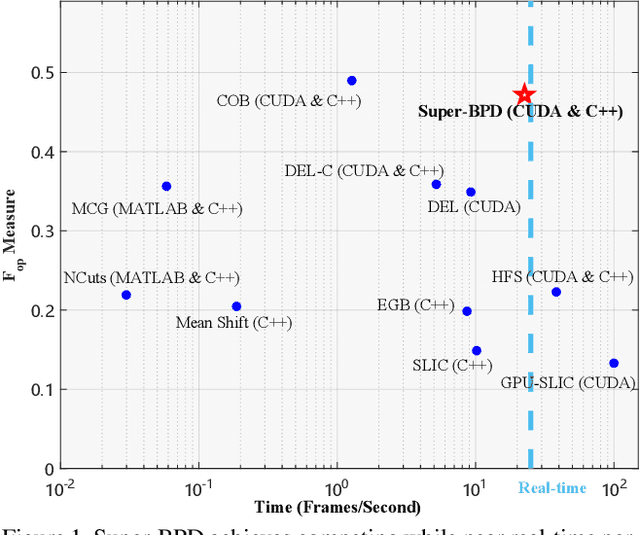
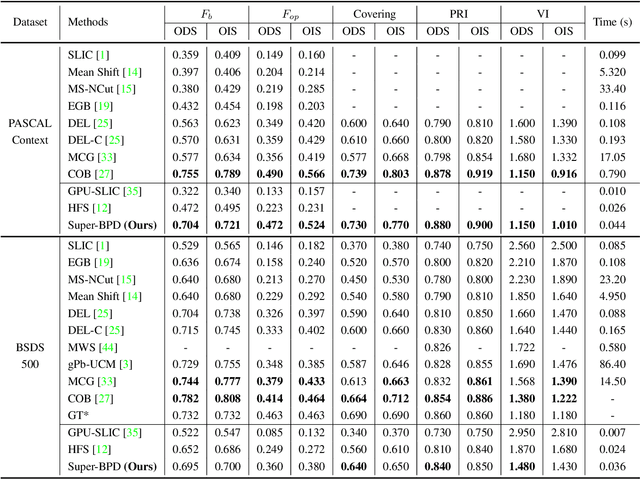

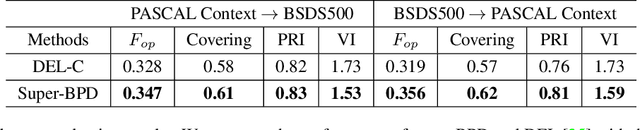
Image segmentation is a fundamental vision task and a crucial step for many applications. In this paper, we propose a fast image segmentation method based on a novel super boundary-to-pixel direction (super-BPD) and a customized segmentation algorithm with super-BPD. Precisely, we define BPD on each pixel as a two-dimensional unit vector pointing from its nearest boundary to the pixel. In the BPD, nearby pixels from different regions have opposite directions departing from each other, and adjacent pixels in the same region have directions pointing to the other or each other (i.e., around medial points). We make use of such property to partition an image into super-BPDs, which are novel informative superpixels with robust direction similarity for fast grouping into segmentation regions. Extensive experimental results on BSDS500 and Pascal Context demonstrate the accuracy and efficency of the proposed super-BPD in segmenting images. In practice, the proposed super-BPD achieves comparable or superior performance with MCG while running at ~25fps vs. 0.07fps. Super-BPD also exhibits a noteworthy transferability to unseen scenes. The code is publicly available at https://github.com/JianqiangWan/Super-BPD.