 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Multimodal Positional Encoding in Vision-Language Models
Oct 27, 2025Multimodal position encoding is essential for vision-language models, yet there has been little systematic investigation into multimodal position encoding. We conduct a comprehensive analysis of multimodal Rotary Positional Embedding (RoPE) by examining its two core components: position design and frequency allocation. Through extensive experiments, we identify three key guidelines: positional coherence, full frequency utilization, and preservation of textual priors-ensuring unambiguous layout, rich representation, and faithful transfer from the pre-trained LLM. Based on these insights, we propose Multi-Head RoPE (MHRoPE) and MRoPE-Interleave (MRoPE-I), two simple and plug-and-play variants that require no architectural changes. Our methods consistently outperform existing approaches across diverse benchmarks, with significant improvements in both general and fine-grained multimodal understanding. Code will be avaliable at https://github.com/JJJYmmm/Multimodal-RoPEs.
Qwen2.5-VL Technical Report
Feb 19, 2025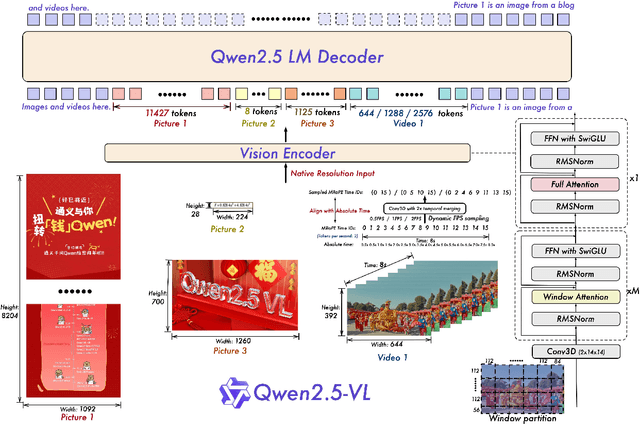
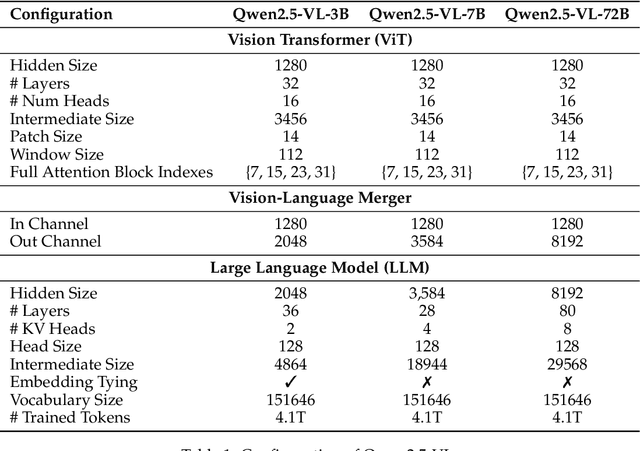
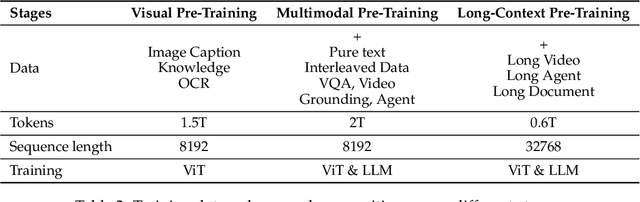
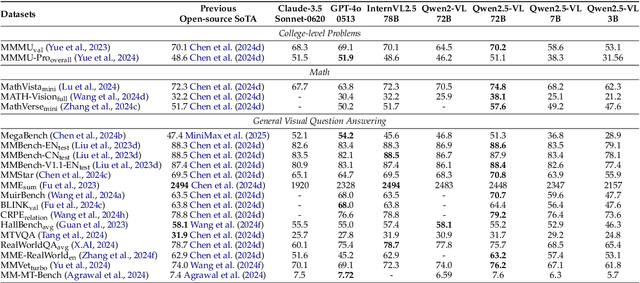
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy
Dec 03, 2024Large Multimodal Models (LMMs) have demonstrated impressive performance on recognizing document images with natural language instructions. However, it remains unclear to what extent capabilities in literacy with rich structure and fine-grained visual challenges. The current landscape lacks a comprehensive benchmark to effectively measure the literate capabilities of LMMs. Existing benchmarks are often limited by narrow scenarios and specified tasks. To this end, we introduce CC-OCR, a comprehensive benchmark that possess a diverse range of scenarios, tasks, and challenges. CC-OCR comprises four OCR-centric tracks: multi-scene text reading, multilingual text reading, document parsing, and key information extraction. It includes 39 subsets with 7,058 full annotated images, of which 41% are sourced from real applications, being released for the first time. Furthermore, we evaluate nine prominent LMMs and reveal both the strengths and weaknesses of these models, particularly in text grounding, multi-orientation, and hallucination of repetition. CC-OCR aims to comprehensively evaluate the capabilities of LMMs on OCR-centered tasks, driving advancement in LMMs.
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Sep 18, 2024



We present the Qwen2-VL Series, an advanced upgrade of the previous Qwen-VL models that redefines the conventional predetermined-resolution approach in visual processing. Qwen2-VL introduces the Naive Dynamic Resolution mechanism, which enables the model to dynamically process images of varying resolutions into different numbers of visual tokens. This approach allows the model to generate more efficient and accurate visual representations, closely aligning with human perceptual processes. The model also integrates Multimodal Rotary Position Embedding (M-RoPE), facilitating the effective fusion of positional information across text, images, and videos. We employ a unified paradigm for processing both images and videos, enhancing the model's visual perception capabilities. To explore the potential of large multimodal models, Qwen2-VL investigates the scaling laws for large vision-language models (LVLMs). By scaling both the model size-with versions at 2B, 8B, and 72B parameters-and the amount of training data, the Qwen2-VL Series achieves highly competitive performance. Notably, the Qwen2-VL-72B model achieves results comparable to leading models such as GPT-4o and Claude3.5-Sonnet across various multimodal benchmarks, outperforming other generalist models. Code is available at \url{https://github.com/QwenLM/Qwen2-VL}.
SynthDoc: Bilingual Documents Synthesis for Visual Document Understanding
Aug 27, 2024



This paper introduces SynthDoc, a novel synthetic document generation pipeline designed to enhance Visual Document Understanding (VDU) by generating high-quality, diverse datasets that include text, images, tables, and charts. Addressing the challenges of data acquisition and the limitations of existing datasets, SynthDoc leverages publicly available corpora and advanced rendering tools to create a comprehensive and versatile dataset. Our experiments, conducted using the Donut model, demonstrate that models trained with SynthDoc's data achieve superior performance in pre-training read tasks and maintain robustness in downstream tasks, despite language inconsistencies. The release of a benchmark dataset comprising 5,000 image-text pairs not only showcases the pipeline's capabilities but also provides a valuable resource for the VDU community to advance research and development in document image recognition. This work significantly contributes to the field by offering a scalable solution to data scarcity and by validating the efficacy of end-to-end models in parsing complex, real-world documents.
What Makes Good Few-shot Examples for Vision-Language Models?
May 22, 2024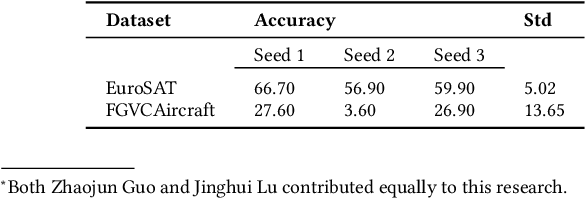
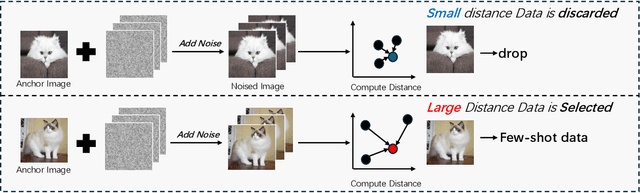
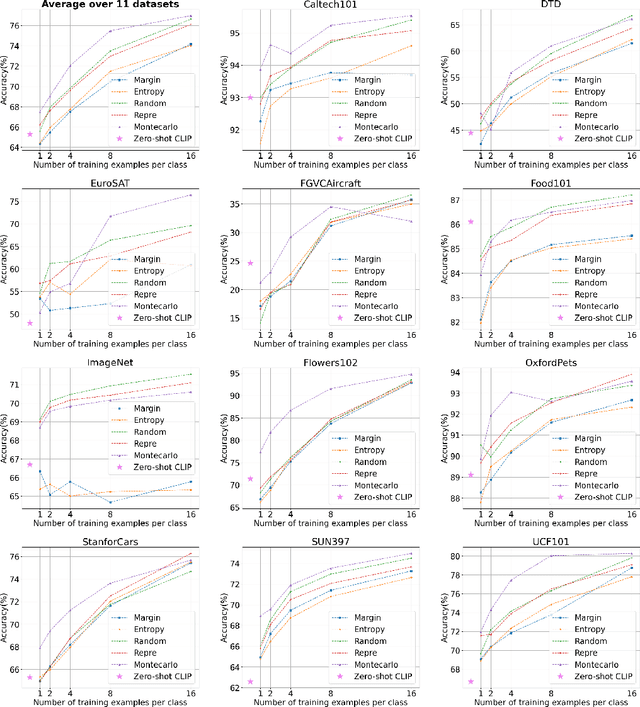
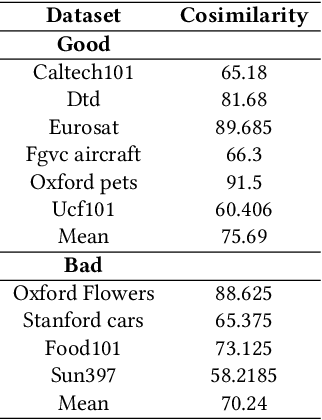
Despite the notable advancements achieved by leveraging pre-trained vision-language (VL) models through few-shot tuning for downstream tasks, our detailed empirical study highlights a significant dependence of few-shot learning outcomes on the careful selection of training examples - a facet that has been previously overlooked in research. In this study, we delve into devising more effective strategies for the meticulous selection of few-shot training examples, as opposed to relying on random sampling, to enhance the potential of existing few-shot prompt learning methodologies. To achieve this, we assess the effectiveness of various Active Learning (AL) techniques for instance selection, such as Entropy and Margin of Confidence, within the context of few-shot training. Furthermore, we introduce two innovative selection methods - Representativeness (REPRE) and Gaussian Monte Carlo (Montecarlo) - designed to proactively pinpoint informative examples for labeling in relation to pre-trained VL models. Our findings demonstrate that both REPRE and Montecarlo significantly surpass both random selection and AL-based strategies in few-shot training scenarios. The research also underscores that these instance selection methods are model-agnostic, offering a versatile enhancement to a wide array of few-shot training methodologies.
PaDeLLM-NER: Parallel Decoding in Large Language Models for Named Entity Recognition
Feb 15, 2024
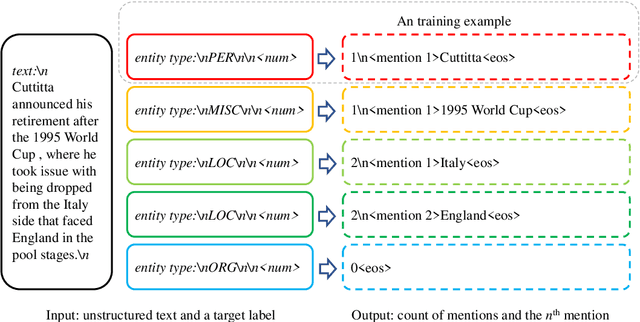
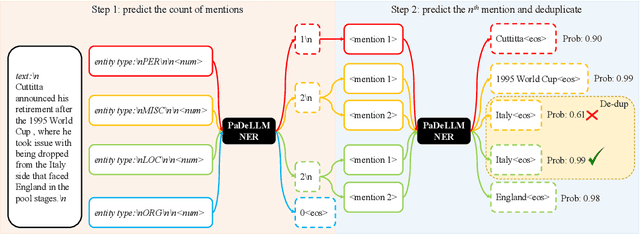
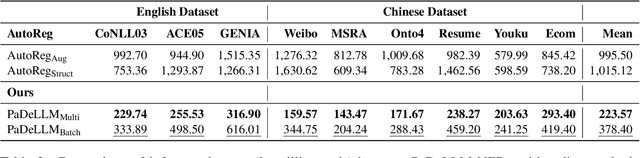
In this study, we aim to reduce generation latency for Named Entity Recognition (NER) with Large Language Models (LLMs). The main cause of high latency in LLMs is the sequential decoding process, which autoregressively generates all labels and mentions for NER, significantly increase the sequence length. To this end, we introduce Parallel Decoding in LLM for NE} (PaDeLLM-NER), a approach that integrates seamlessly into existing generative model frameworks without necessitating additional modules or architectural modifications. PaDeLLM-NER allows for the simultaneous decoding of all mentions, thereby reducing generation latency. Experiments reveal that PaDeLLM-NER significantly increases inference speed that is 1.76 to 10.22 times faster than the autoregressive approach for both English and Chinese. Simultaneously it maintains the quality of predictions as evidenced by the performance that is on par with the state-of-the-art across various datasets.
Context Disentangling and Prototype Inheriting for Robust Visual Grounding
Dec 19, 2023



Visual grounding (VG) aims to locate a specific target in an image based on a given language query. The discriminative information from context is important for distinguishing the target from other objects, particularly for the targets that have the same category as others. However, most previous methods underestimate such information. Moreover, they are usually designed for the standard scene (without any novel object), which limits their generalization to the open-vocabulary scene. In this paper, we propose a novel framework with context disentangling and prototype inheriting for robust visual grounding to handle both scenes. Specifically, the context disentangling disentangles the referent and context features, which achieves better discrimination between them. The prototype inheriting inherits the prototypes discovered from the disentangled visual features by a prototype bank to fully utilize the seen data, especially for the open-vocabulary scene. The fused features, obtained by leveraging Hadamard product on disentangled linguistic and visual features of prototypes to avoid sharp adjusting the importance between the two types of features, are then attached with a special token and feed to a vision Transformer encoder for bounding box regression. Extensive experiments are conducted on both standard and open-vocabulary scenes. The performance comparisons indicate that our method outperforms the state-of-the-art methods in both scenarios. {The code is available at https://github.com/WayneTomas/TransCP.
What Large Language Models Bring to Text-rich VQA?
Nov 13, 2023Text-rich VQA, namely Visual Question Answering based on text recognition in the images, is a cross-modal task that requires both image comprehension and text recognition. In this work, we focus on investigating the advantages and bottlenecks of LLM-based approaches in addressing this problem. To address the above concern, we separate the vision and language modules, where we leverage external OCR models to recognize texts in the image and Large Language Models (LLMs) to answer the question given texts. The whole framework is training-free benefiting from the in-context ability of LLMs. This pipeline achieved superior performance compared to the majority of existing Multimodal Large Language Models (MLLM) on four text-rich VQA datasets. Besides, based on the ablation study, we find that LLM brings stronger comprehension ability and may introduce helpful knowledge for the VQA problem. The bottleneck for LLM to address text-rich VQA problems may primarily lie in visual part. We also combine the OCR module with MLLMs and pleasantly find that the combination of OCR module with MLLM also works. It's worth noting that not all MLLMs can comprehend the OCR information, which provides insights into how to train an MLLM that preserves the abilities of LLM.
Deeply Coupled Cross-Modal Prompt Learning
May 30, 2023



Recent advancements in multimodal foundation models (e.g., CLIP) have excelled in zero-shot generalization. Prompt tuning involved in the knowledge transfer from foundation models to downstream tasks has gained significant attention recently. Existing prompt-tuning methods in cross-modal learning, however, either solely focus on language branch, or learn vision-language interaction in a shallow mechanism. In this context, we propose a Deeply coupled Cross-modal Prompt learning (DCP) method based on CLIP. DCP flexibly accommodates the interplay between vision and language with a Cross-Modal Prompt Attention (CMPA) mechanism, which enables the mutual exchange of respective representation through a well-connected multi-head attention module progressively and strongly. We then conduct comprehensive few-shot learning experiments on 11 image classification datasets and analyze the robustness to domain shift as well. Thorough experimental analysis evidently demonstrates the superb few-shot generalization and compelling domain adaption capacity of a well-executed DCP. The code can be found at https://github.com/GingL/CMPA.