 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
May 28, 2026Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fragmented capabilities and limited generalization across tasks, environments, and robot embodiments. In this work, we study whether heterogeneous embodied decision-making problems can be unified within a single vision-language-action model. We present Qwen-VLA, a unified embodied foundation model that extends Qwen's vision-language modeling stack from perception, understanding, and reasoning to continuous action and trajectory generation through a DiT-based action decoder. Qwen-VLA is trained with a large-scale joint pretraining recipe over diverse data sources, including robotics manipulation trajectories, human egocentric demonstrations, synthetic simulation data, vision-and-language navigation data, trajectory-centric supervision, and auxiliary vision-language data. To support multiple robot platforms, we introduce embodiment-aware prompt conditioning, where robot-specific textual descriptions specify the current embodiment and control convention. We further cast manipulation, navigation, and trajectory prediction into a unified action-and-trajectory prediction framework, enabling transferable visual grounding, spatial reasoning, and continuous action generation across robot morphologies, task families, and environments. Experiments on manipulation, navigation, and trajectory-centric benchmarks show consistent multi-task performance and out-of-distribution generalization under variations in scene layout, background, lighting, object configuration, and robot embodiment. Qwen-VLA-Instruct achieves 97.9% on LIBERO, 73.7% on Simpler-WidowX, 86.1%/87.2% on RoboTwin-Easy/Hard, 69.0% OSR on R2R, 59.6% SR on RxR, 76.9% average OOD success in real-world ALOHA experiments, and 26.6% zero-shot success on DOMINO dynamic manipulation.
Qwen2.5-VL Technical Report
Feb 19, 2025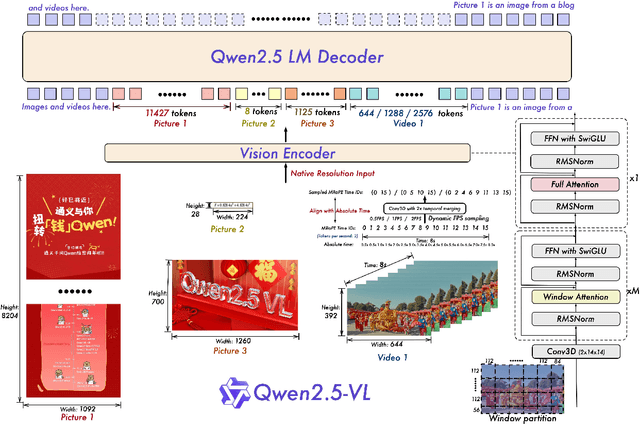
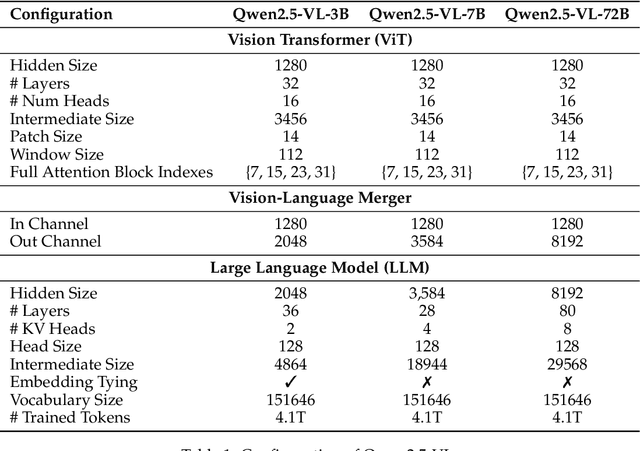
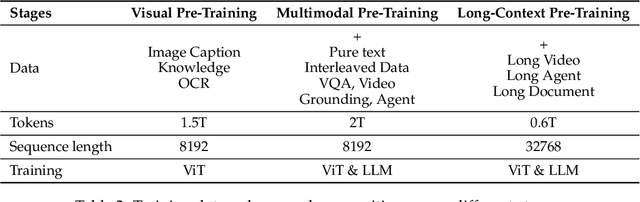
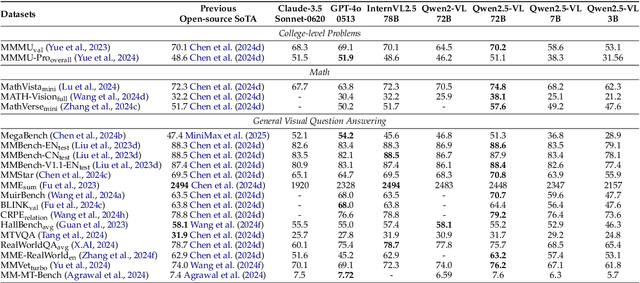
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy
Dec 03, 2024Large Multimodal Models (LMMs) have demonstrated impressive performance on recognizing document images with natural language instructions. However, it remains unclear to what extent capabilities in literacy with rich structure and fine-grained visual challenges. The current landscape lacks a comprehensive benchmark to effectively measure the literate capabilities of LMMs. Existing benchmarks are often limited by narrow scenarios and specified tasks. To this end, we introduce CC-OCR, a comprehensive benchmark that possess a diverse range of scenarios, tasks, and challenges. CC-OCR comprises four OCR-centric tracks: multi-scene text reading, multilingual text reading, document parsing, and key information extraction. It includes 39 subsets with 7,058 full annotated images, of which 41% are sourced from real applications, being released for the first time. Furthermore, we evaluate nine prominent LMMs and reveal both the strengths and weaknesses of these models, particularly in text grounding, multi-orientation, and hallucination of repetition. CC-OCR aims to comprehensively evaluate the capabilities of LMMs on OCR-centered tasks, driving advancement in LMMs.
VL-Reader: Vision and Language Reconstructor is an Effective Scene Text Recognizer
Sep 18, 2024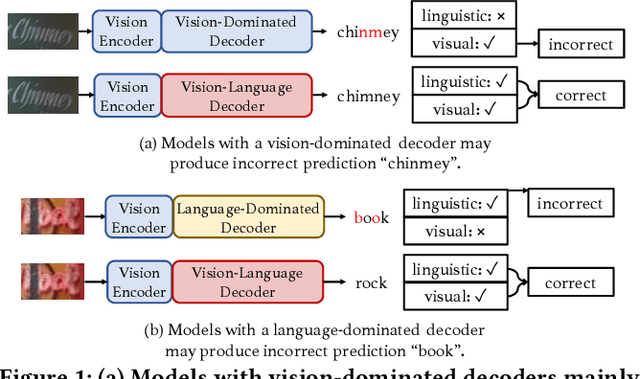
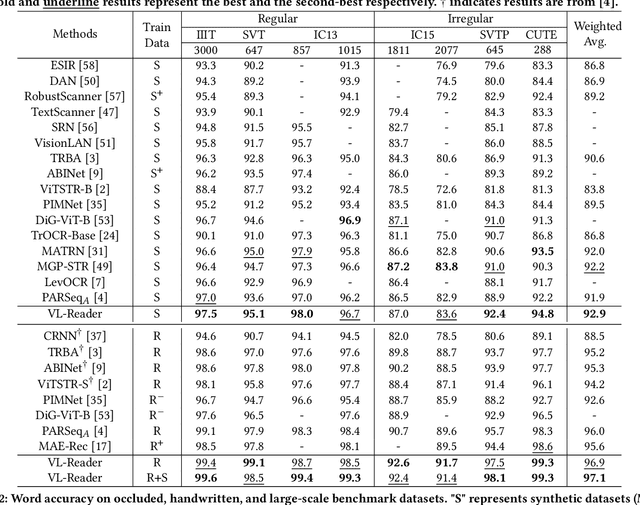

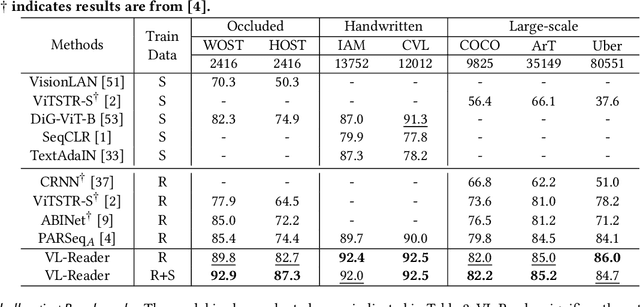
Text recognition is an inherent integration of vision and language, encompassing the visual texture in stroke patterns and the semantic context among the character sequences. Towards advanced text recognition, there are three key challenges: (1) an encoder capable of representing the visual and semantic distributions; (2) a decoder that ensures the alignment between vision and semantics; and (3) consistency in the framework during pre-training, if it exists, and fine-tuning. Inspired by masked autoencoding, a successful pre-training strategy in both vision and language, we propose an innovative scene text recognition approach, named VL-Reader. The novelty of the VL-Reader lies in the pervasive interplay between vision and language throughout the entire process. Concretely, we first introduce a Masked Visual-Linguistic Reconstruction (MVLR) objective, which aims at simultaneously modeling visual and linguistic information. Then, we design a Masked Visual-Linguistic Decoder (MVLD) to further leverage masked vision-language context and achieve bi-modal feature interaction. The architecture of VL-Reader maintains consistency from pre-training to fine-tuning. In the pre-training stage, VL-Reader reconstructs both masked visual and text tokens, while in the fine-tuning stage, the network degrades to reconstruct all characters from an image without any masked regions. VL-reader achieves an average accuracy of 97.1% on six typical datasets, surpassing the SOTA by 1.1%. The improvement was even more significant on challenging datasets. The results demonstrate that vision and language reconstructor can serve as an effective scene text recognizer.
Platypus: A Generalized Specialist Model for Reading Text in Various Forms
Aug 27, 2024



Reading text from images (either natural scenes or documents) has been a long-standing research topic for decades, due to the high technical challenge and wide application range. Previously, individual specialist models are developed to tackle the sub-tasks of text reading (e.g., scene text recognition, handwritten text recognition and mathematical expression recognition). However, such specialist models usually cannot effectively generalize across different sub-tasks. Recently, generalist models (such as GPT-4V), trained on tremendous data in a unified way, have shown enormous potential in reading text in various scenarios, but with the drawbacks of limited accuracy and low efficiency. In this work, we propose Platypus, a generalized specialist model for text reading. Specifically, Platypus combines the best of both worlds: being able to recognize text of various forms with a single unified architecture, while achieving excellent accuracy and high efficiency. To better exploit the advantage of Platypus, we also construct a text reading dataset (called Worms), the images of which are curated from previous datasets and partially re-labeled. Experiments on standard benchmarks demonstrate the effectiveness and superiority of the proposed Platypus model. Model and data will be made publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/Platypus.
Conditional Text Image Generation with Diffusion Models
Jun 19, 2023Current text recognition systems, including those for handwritten scripts and scene text, have relied heavily on image synthesis and augmentation, since it is difficult to realize real-world complexity and diversity through collecting and annotating enough real text images. In this paper, we explore the problem of text image generation, by taking advantage of the powerful abilities of Diffusion Models in generating photo-realistic and diverse image samples with given conditions, and propose a method called Conditional Text Image Generation with Diffusion Models (CTIG-DM for short). To conform to the characteristics of text images, we devise three conditions: image condition, text condition, and style condition, which can be used to control the attributes, contents, and styles of the samples in the image generation process. Specifically, four text image generation modes, namely: (1) synthesis mode, (2) augmentation mode, (3) recovery mode, and (4) imitation mode, can be derived by combining and configuring these three conditions. Extensive experiments on both handwritten and scene text demonstrate that the proposed CTIG-DM is able to produce image samples that simulate real-world complexity and diversity, and thus can boost the performance of existing text recognizers. Besides, CTIG-DM shows its appealing potential in domain adaptation and generating images containing Out-Of-Vocabulary (OOV) words.