 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
Jan 08, 2026In this report, we introduce the Qwen3-VL-Embedding and Qwen3-VL-Reranker model series, the latest extensions of the Qwen family built on the Qwen3-VL foundation model. Together, they provide an end-to-end pipeline for high-precision multimodal search by mapping diverse modalities, including text, images, document images, and video, into a unified representation space. The Qwen3-VL-Embedding model employs a multi-stage training paradigm, progressing from large-scale contrastive pre-training to reranking model distillation, to generate semantically rich high-dimensional vectors. It supports Matryoshka Representation Learning, enabling flexible embedding dimensions, and handles inputs up to 32k tokens. Complementing this, Qwen3-VL-Reranker performs fine-grained relevance estimation for query-document pairs using a cross-encoder architecture with cross-attention mechanisms. Both model series inherit the multilingual capabilities of Qwen3-VL, supporting more than 30 languages, and are released in $\textbf{2B}$ and $\textbf{8B}$ parameter sizes to accommodate diverse deployment requirements. Empirical evaluations demonstrate that the Qwen3-VL-Embedding series achieves state-of-the-art results across diverse multimodal embedding evaluation benchmarks. Specifically, Qwen3-VL-Embedding-8B attains an overall score of $\textbf{77.8}$ on MMEB-V2, ranking first among all models (as of January 8, 2025). This report presents the architecture, training methodology, and practical capabilities of the series, demonstrating their effectiveness on various multimodal retrieval tasks, including image-text retrieval, visual question answering, and video-text matching.
VLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jan 06, 2026Vision-Language-Action (VLA) models, which integrate pretrained large Vision-Language Models (VLM) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM's general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM's performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning.
VLCache: Computing 2% Vision Tokens and Reusing 98% for Vision-Language Inference
Dec 18, 2025This paper presents VLCache, a cache reuse framework that exploits both Key-Value (KV) cache and encoder cache from prior multimodal inputs to eliminate costly recomputation when the same multimodal inputs recur. Unlike previous heuristic approaches, we formally identify the cumulative reuse error effect and demonstrate how to minimize the non-prefix cache reuse error effectively. We further analyze the varying importance of model layers and propose a dynamic, layer-aware recomputation strategy to balance accuracy and efficiency. Experimental results show that VLCache achieves an accuracy on par with full recomputation, while requiring only 2-5% of the tokens to compute, yielding 1.2x-16x TTFT speedups. We develop an experimental implementation of the proposed VLCache pipeline based on SGLang, enabling significantly faster inference in practical deployments.
Revisiting Multimodal Positional Encoding in Vision-Language Models
Oct 27, 2025Multimodal position encoding is essential for vision-language models, yet there has been little systematic investigation into multimodal position encoding. We conduct a comprehensive analysis of multimodal Rotary Positional Embedding (RoPE) by examining its two core components: position design and frequency allocation. Through extensive experiments, we identify three key guidelines: positional coherence, full frequency utilization, and preservation of textual priors-ensuring unambiguous layout, rich representation, and faithful transfer from the pre-trained LLM. Based on these insights, we propose Multi-Head RoPE (MHRoPE) and MRoPE-Interleave (MRoPE-I), two simple and plug-and-play variants that require no architectural changes. Our methods consistently outperform existing approaches across diverse benchmarks, with significant improvements in both general and fine-grained multimodal understanding. Code will be avaliable at https://github.com/JJJYmmm/Multimodal-RoPEs.
FLUX-Reason-6M & PRISM-Bench: A Million-Scale Text-to-Image Reasoning Dataset and Comprehensive Benchmark
Sep 11, 2025The advancement of open-source text-to-image (T2I) models has been hindered by the absence of large-scale, reasoning-focused datasets and comprehensive evaluation benchmarks, resulting in a performance gap compared to leading closed-source systems. To address this challenge, We introduce FLUX-Reason-6M and PRISM-Bench (Precise and Robust Image Synthesis Measurement Benchmark). FLUX-Reason-6M is a massive dataset consisting of 6 million high-quality FLUX-generated images and 20 million bilingual (English and Chinese) descriptions specifically designed to teach complex reasoning. The image are organized according to six key characteristics: Imagination, Entity, Text rendering, Style, Affection, and Composition, and design explicit Generation Chain-of-Thought (GCoT) to provide detailed breakdowns of image generation steps. The whole data curation takes 15,000 A100 GPU days, providing the community with a resource previously unattainable outside of large industrial labs. PRISM-Bench offers a novel evaluation standard with seven distinct tracks, including a formidable Long Text challenge using GCoT. Through carefully designed prompts, it utilizes advanced vision-language models for nuanced human-aligned assessment of prompt-image alignment and image aesthetics. Our extensive evaluation of 19 leading models on PRISM-Bench reveals critical performance gaps and highlights specific areas requiring improvement. Our dataset, benchmark, and evaluation code are released to catalyze the next wave of reasoning-oriented T2I generation. Project page: https://flux-reason-6m.github.io/ .
Qwen2.5-Omni Technical Report
Mar 26, 2025



In this report, we present Qwen2.5-Omni, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. To enable the streaming of multimodal information inputs, both audio and visual encoders utilize a block-wise processing approach. To synchronize the timestamps of video inputs with audio, we organize the audio and video sequentially in an interleaved manner and propose a novel position embedding approach, named TMRoPE(Time-aligned Multimodal RoPE). To concurrently generate text and speech while avoiding interference between the two modalities, we propose \textbf{Thinker-Talker} architecture. In this framework, Thinker functions as a large language model tasked with text generation, while Talker is a dual-track autoregressive model that directly utilizes the hidden representations from the Thinker to produce audio tokens as output. Both the Thinker and Talker models are designed to be trained and inferred in an end-to-end manner. For decoding audio tokens in a streaming manner, we introduce a sliding-window DiT that restricts the receptive field, aiming to reduce the initial package delay. Qwen2.5-Omni is comparable with the similarly sized Qwen2.5-VL and outperforms Qwen2-Audio. Furthermore, Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench. Notably, Qwen2.5-Omni's performance in end-to-end speech instruction following is comparable to its capabilities with text inputs, as evidenced by benchmarks such as MMLU and GSM8K. As for speech generation, Qwen2.5-Omni's streaming Talker outperforms most existing streaming and non-streaming alternatives in robustness and naturalness.
Multimodal Representation Alignment for Image Generation: Text-Image Interleaved Control Is Easier Than You Think
Feb 27, 2025The field of advanced text-to-image generation is witnessing the emergence of unified frameworks that integrate powerful text encoders, such as CLIP and T5, with Diffusion Transformer backbones. Although there have been efforts to control output images with additional conditions, like canny and depth map, a comprehensive framework for arbitrary text-image interleaved control is still lacking. This gap is especially evident when attempting to merge concepts or visual elements from multiple images in the generation process. To mitigate the gap, we conducted preliminary experiments showing that large multimodal models (LMMs) offer an effective shared representation space, where image and text can be well-aligned to serve as a condition for external diffusion models. Based on this discovery, we propose Dream Engine, an efficient and unified framework designed for arbitrary text-image interleaved control in image generation models. Building on powerful text-to-image models like SD3.5, we replace the original text-only encoders by incorporating versatile multimodal information encoders such as QwenVL. Our approach utilizes a two-stage training paradigm, consisting of joint text-image alignment and multimodal interleaved instruction tuning. Our experiments demonstrate that this training method is effective, achieving a 0.69 overall score on the GenEval benchmark, and matching the performance of state-of-the-art text-to-image models like SD3.5 and FLUX.
Qwen2.5-VL Technical Report
Feb 19, 2025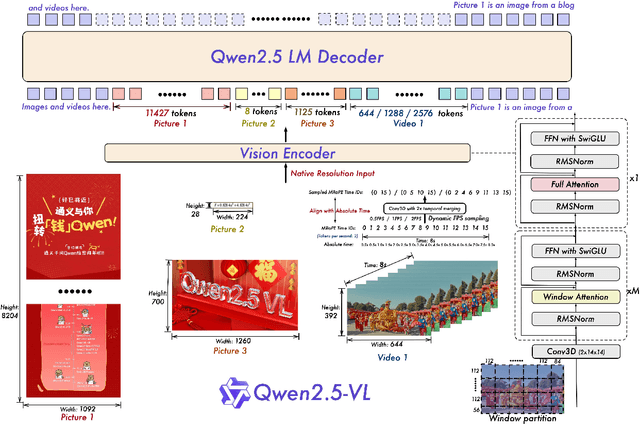
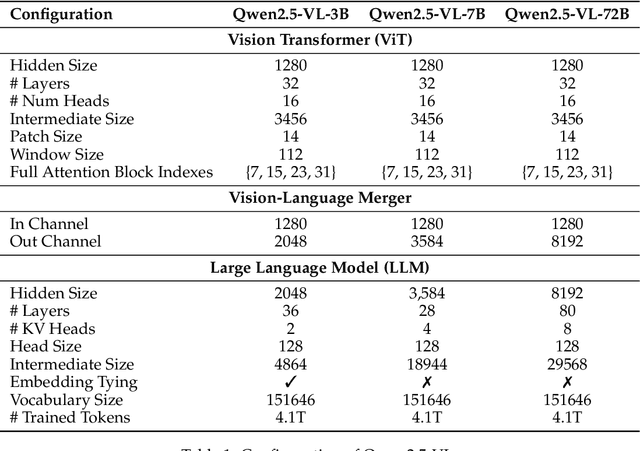
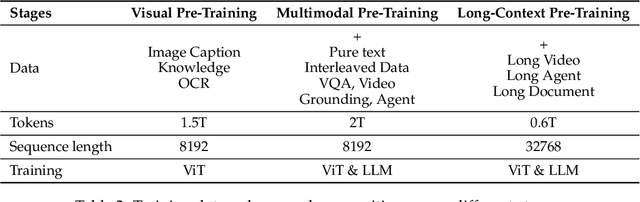
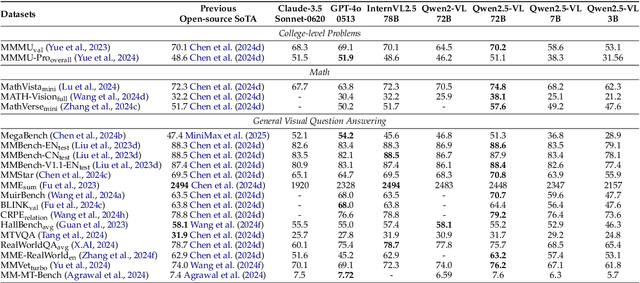
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey
Dec 30, 2024



Building on the foundations of language modeling in natural language processing, Next Token Prediction (NTP) has evolved into a versatile training objective for machine learning tasks across various modalities, achieving considerable success. As Large Language Models (LLMs) have advanced to unify understanding and generation tasks within the textual modality, recent research has shown that tasks from different modalities can also be effectively encapsulated within the NTP framework, transforming the multimodal information into tokens and predict the next one given the context. This survey introduces a comprehensive taxonomy that unifies both understanding and generation within multimodal learning through the lens of NTP. The proposed taxonomy covers five key aspects: Multimodal tokenization, MMNTP model architectures, unified task representation, datasets \& evaluation, and open challenges. This new taxonomy aims to aid researchers in their exploration of multimodal intelligence. An associated GitHub repository collecting the latest papers and repos is available at https://github.com/LMM101/Awesome-Multimodal-Next-Token-Prediction
CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy
Dec 03, 2024Large Multimodal Models (LMMs) have demonstrated impressive performance on recognizing document images with natural language instructions. However, it remains unclear to what extent capabilities in literacy with rich structure and fine-grained visual challenges. The current landscape lacks a comprehensive benchmark to effectively measure the literate capabilities of LMMs. Existing benchmarks are often limited by narrow scenarios and specified tasks. To this end, we introduce CC-OCR, a comprehensive benchmark that possess a diverse range of scenarios, tasks, and challenges. CC-OCR comprises four OCR-centric tracks: multi-scene text reading, multilingual text reading, document parsing, and key information extraction. It includes 39 subsets with 7,058 full annotated images, of which 41% are sourced from real applications, being released for the first time. Furthermore, we evaluate nine prominent LMMs and reveal both the strengths and weaknesses of these models, particularly in text grounding, multi-orientation, and hallucination of repetition. CC-OCR aims to comprehensively evaluate the capabilities of LMMs on OCR-centered tasks, driving advancement in LMMs.