 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-AgentWorld: Language World Models for General Agents
Jun 23, 2026A world model predicts environment dynamics based on current observations and actions, serving as a core cognitive mechanism for reasoning and planning. In this work, we investigate how world modeling based on language models can further push the boundaries of general agents. (i) We first focus on building foundation models for agentic environment simulation. We introduce Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B, the first language world models capable of simulating agentic environments covering 7 domains via long chain-of-thought reasoning. Leveraging more than 10M environment interaction trajectories of 7 domains in real-world environments, we develop Qwen-AgentWorld through a three-stage training pipeline: CPT injects general-purpose world modeling capabilities from the state transition dynamics and augmented professional corpora, SFT activates next-state-prediction reasoning, and RL sharpens simulation fidelity through a tailored framework with hybrid rubric-and-rule rewards. To evaluate language world models, we present AgentWorldBench, a comprehensive benchmark constructed from real-world interactions of 5 frontier models on 9 established benchmarks. Empirical results demonstrate that Qwen-AgentWorld significantly outperforms existing frontier models. (ii) Beyond foundation models, we further investigate two complementary paradigms through which world modeling enhances general agents. First, as a decoupled environment simulator, Qwen-AgentWorld supports scalable and controllable simulation of thousands of real-world environments for agentic RL, yielding gains that surpass real-environment training alone. Second, as a unified agent foundation model, world-model training acts as a highly effective warm-up that improves downstream performance across 7 agentic benchmarks. Code: https://github.com/QwenLM/Qwen-AgentWorld
Qwen-Image-2.0 Technical Report
May 11, 2026We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
GeRe: Towards Efficient Anti-Forgetting in Continual Learning of LLM via General Samples Replay
Aug 06, 2025The continual learning capability of large language models (LLMs) is crucial for advancing artificial general intelligence. However, continual fine-tuning LLMs across various domains often suffers from catastrophic forgetting, characterized by: 1) significant forgetting of their general capabilities, and 2) sharp performance declines in previously learned tasks. To simultaneously address both issues in a simple yet stable manner, we propose General Sample Replay (GeRe), a framework that use usual pretraining texts for efficient anti-forgetting. Beyond revisiting the most prevalent replay-based practices under GeRe, we further leverage neural states to introduce a enhanced activation states constrained optimization method using threshold-based margin (TM) loss, which maintains activation state consistency during replay learning. We are the first to validate that a small, fixed set of pre-collected general replay samples is sufficient to resolve both concerns--retaining general capabilities while promoting overall performance across sequential tasks. Indeed, the former can inherently facilitate the latter. Through controlled experiments, we systematically compare TM with different replay strategies under the GeRe framework, including vanilla label fitting, logit imitation via KL divergence and feature imitation via L1/L2 losses. Results demonstrate that TM consistently improves performance and exhibits better robustness. Our work paves the way for efficient replay of LLMs for the future. Our code and data are available at https://github.com/Qznan/GeRe.
Research on Graph-Retrieval Augmented Generation Based on Historical Text Knowledge Graphs
Jun 18, 2025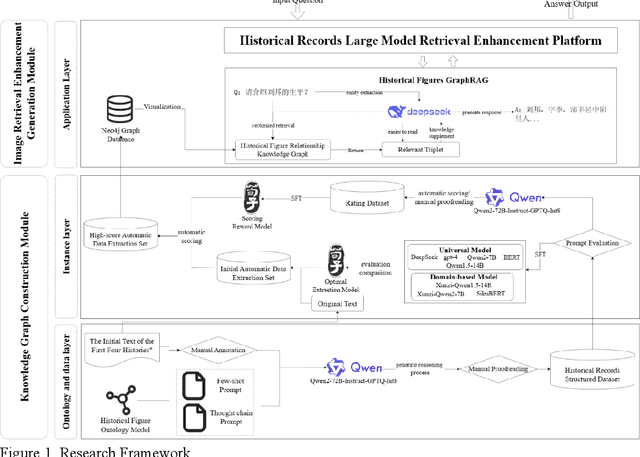
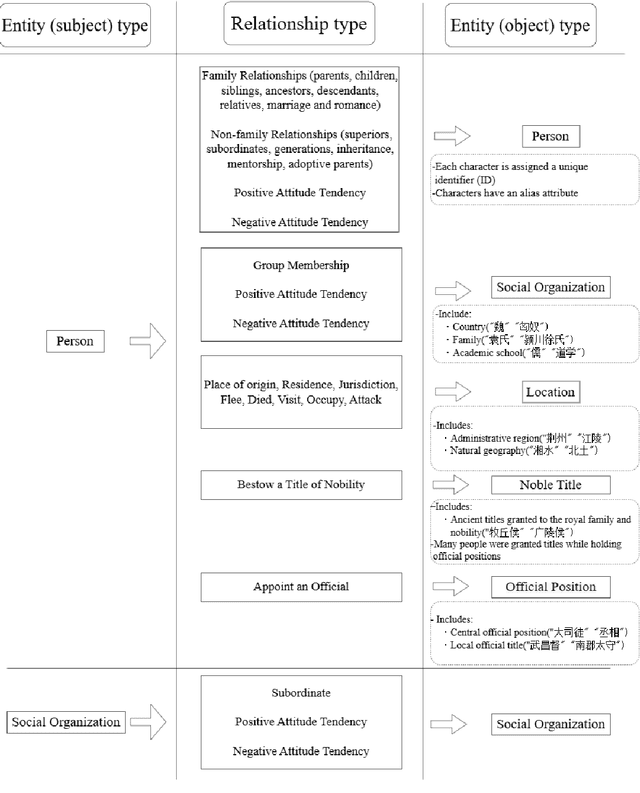
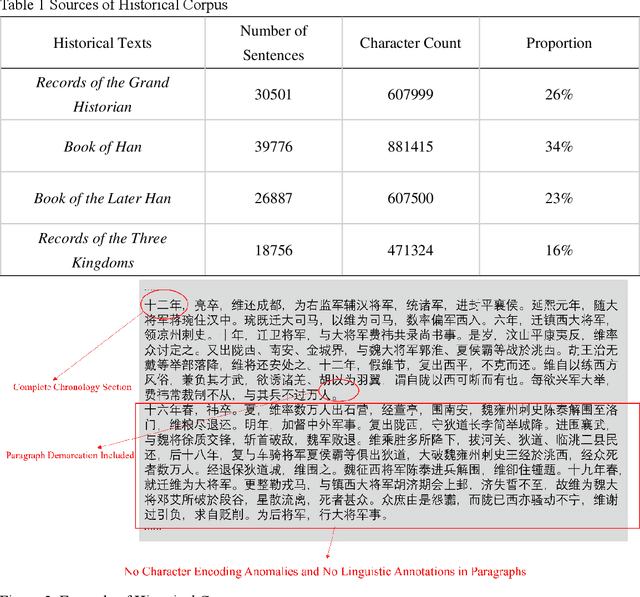

This article addresses domain knowledge gaps in general large language models for historical text analysis in the context of computational humanities and AIGC technology. We propose the Graph RAG framework, combining chain-of-thought prompting, self-instruction generation, and process supervision to create a The First Four Histories character relationship dataset with minimal manual annotation. This dataset supports automated historical knowledge extraction, reducing labor costs. In the graph-augmented generation phase, we introduce a collaborative mechanism between knowledge graphs and retrieval-augmented generation, improving the alignment of general models with historical knowledge. Experiments show that the domain-specific model Xunzi-Qwen1.5-14B, with Simplified Chinese input and chain-of-thought prompting, achieves optimal performance in relation extraction (F1 = 0.68). The DeepSeek model integrated with GraphRAG improves F1 by 11% (0.08-0.19) on the open-domain C-CLUE relation extraction dataset, surpassing the F1 value of Xunzi-Qwen1.5-14B (0.12), effectively alleviating hallucinations phenomenon, and improving interpretability. This framework offers a low-resource solution for classical text knowledge extraction, advancing historical knowledge services and humanities research.
WorldPM: Scaling Human Preference Modeling
May 15, 2025Motivated by scaling laws in language modeling that demonstrate how test loss scales as a power law with model and dataset sizes, we find that similar laws exist in preference modeling. We propose World Preference Modeling$ (WorldPM) to emphasize this scaling potential, where World Preference embodies a unified representation of human preferences. In this paper, we collect preference data from public forums covering diverse user communities, and conduct extensive training using 15M-scale data across models ranging from 1.5B to 72B parameters. We observe distinct patterns across different evaluation metrics: (1) Adversarial metrics (ability to identify deceptive features) consistently scale up with increased training data and base model size; (2) Objective metrics (objective knowledge with well-defined answers) show emergent behavior in larger language models, highlighting WorldPM's scalability potential; (3) Subjective metrics (subjective preferences from a limited number of humans or AI) do not demonstrate scaling trends. Further experiments validate the effectiveness of WorldPM as a foundation for preference fine-tuning. Through evaluations on 7 benchmarks with 20 subtasks, we find that WorldPM broadly improves the generalization performance across human preference datasets of varying sizes (7K, 100K and 800K samples), with performance gains exceeding 5% on many key subtasks. Integrating WorldPM into our internal RLHF pipeline, we observe significant improvements on both in-house and public evaluation sets, with notable gains of 4% to 8% in our in-house evaluations.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
CrossFormer: Cross-Segment Semantic Fusion for Document Segmentation
Apr 02, 2025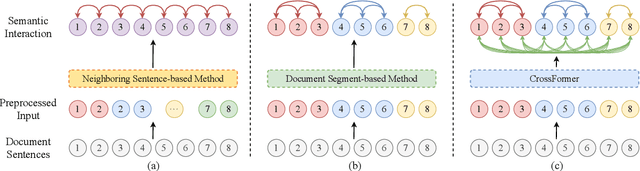
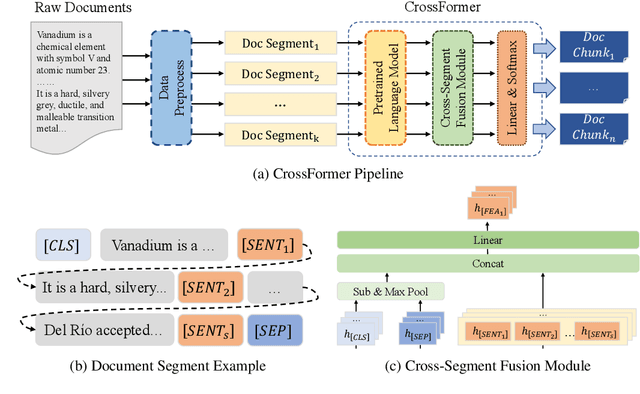
Text semantic segmentation involves partitioning a document into multiple paragraphs with continuous semantics based on the subject matter, contextual information, and document structure. Traditional approaches have typically relied on preprocessing documents into segments to address input length constraints, resulting in the loss of critical semantic information across segments. To address this, we present CrossFormer, a transformer-based model featuring a novel cross-segment fusion module that dynamically models latent semantic dependencies across document segments, substantially elevating segmentation accuracy. Additionally, CrossFormer can replace rule-based chunk methods within the Retrieval-Augmented Generation (RAG) system, producing more semantically coherent chunks that enhance its efficacy. Comprehensive evaluations confirm CrossFormer's state-of-the-art performance on public text semantic segmentation datasets, alongside considerable gains on RAG benchmarks.
Qwen2.5-Omni Technical Report
Mar 26, 2025



In this report, we present Qwen2.5-Omni, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. To enable the streaming of multimodal information inputs, both audio and visual encoders utilize a block-wise processing approach. To synchronize the timestamps of video inputs with audio, we organize the audio and video sequentially in an interleaved manner and propose a novel position embedding approach, named TMRoPE(Time-aligned Multimodal RoPE). To concurrently generate text and speech while avoiding interference between the two modalities, we propose \textbf{Thinker-Talker} architecture. In this framework, Thinker functions as a large language model tasked with text generation, while Talker is a dual-track autoregressive model that directly utilizes the hidden representations from the Thinker to produce audio tokens as output. Both the Thinker and Talker models are designed to be trained and inferred in an end-to-end manner. For decoding audio tokens in a streaming manner, we introduce a sliding-window DiT that restricts the receptive field, aiming to reduce the initial package delay. Qwen2.5-Omni is comparable with the similarly sized Qwen2.5-VL and outperforms Qwen2-Audio. Furthermore, Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench. Notably, Qwen2.5-Omni's performance in end-to-end speech instruction following is comparable to its capabilities with text inputs, as evidenced by benchmarks such as MMLU and GSM8K. As for speech generation, Qwen2.5-Omni's streaming Talker outperforms most existing streaming and non-streaming alternatives in robustness and naturalness.
CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings
Jan 03, 2025With the increasing code reasoning capabilities of existing large language models (LLMs) and breakthroughs in reasoning models like OpenAI o1 and o3, there is a growing need to develop more challenging and comprehensive benchmarks that effectively test their sophisticated competition-level coding abilities. Existing benchmarks, like LiveCodeBench and USACO, fall short due to the unavailability of private test cases, lack of support for special judges, and misaligned execution environments. To bridge this gap, we introduce CodeElo, a standardized competition-level code generation benchmark that effectively addresses all these challenges for the first time. CodeElo benchmark is mainly based on the official CodeForces platform and tries to align with the platform as much as possible. We compile the recent six months of contest problems on CodeForces with detailed information such as contest divisions, problem difficulty ratings, and problem algorithm tags. We introduce a unique judging method in which problems are submitted directly to the platform and develop a reliable Elo rating calculation system that aligns with the platform and is comparable with human participants but has lower variance. By testing on our CodeElo, we provide the Elo ratings of 30 existing popular open-source and 3 proprietary LLMs for the first time. The results show that o1-mini and QwQ-32B-Preview stand out significantly, achieving Elo ratings of 1578 and 1261, respectively, while other models struggle even with the easiest problems, placing in the lowest 25 percent among all human participants. Detailed analysis experiments are also conducted to provide insights into performance across algorithms and comparisons between using C++ and Python, which can suggest directions for future studies.
Qwen2.5 Technical Report
Dec 19, 2024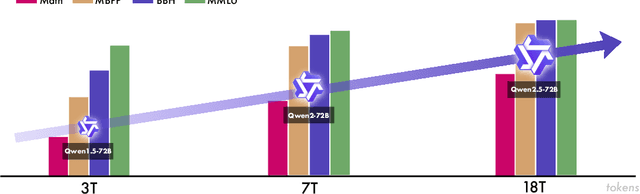

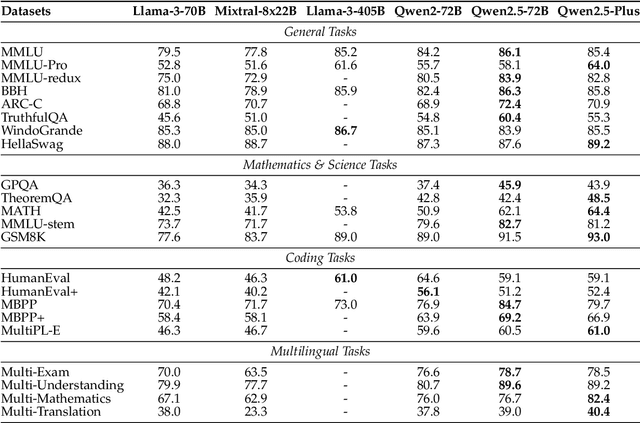
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.