 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranching Strategies Based on Subgraph GNNs: A Study on Theoretical Promise versus Practical Reality
Dec 10, 2025Graph Neural Networks (GNNs) have emerged as a promising approach for ``learning to branch'' in Mixed-Integer Linear Programming (MILP). While standard Message-Passing GNNs (MPNNs) are efficient, they theoretically lack the expressive power to fully represent MILP structures. Conversely, higher-order GNNs (like 2-FGNNs) are expressive but computationally prohibitive. In this work, we investigate Subgraph GNNs as a theoretical middle ground. Crucially, while previous work [Chen et al., 2025] demonstrated that GNNs with 3-WL expressive power can approximate Strong Branching, we prove a sharper result: node-anchored Subgraph GNNs whose expressive power is strictly lower than 3-WL [Zhang et al., 2023] are sufficient to approximate Strong Branching scores. However, our extensive empirical evaluation on four benchmark datasets reveals a stark contrast between theory and practice. While node-anchored Subgraph GNNs theoretically offer superior branching decisions, their $O(n)$ complexity overhead results in significant memory bottlenecks and slower solving times than MPNNs and heuristics. Our results indicate that for MILP branching, the computational cost of expressive GNNs currently outweighs their gains in decision quality, suggesting that future research must focus on efficiency-preserving expressivity.
CrossFormer: Cross-Segment Semantic Fusion for Document Segmentation
Apr 02, 2025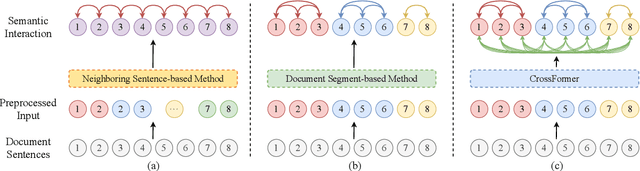
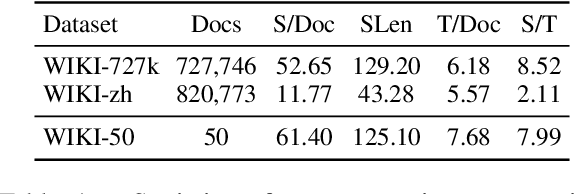
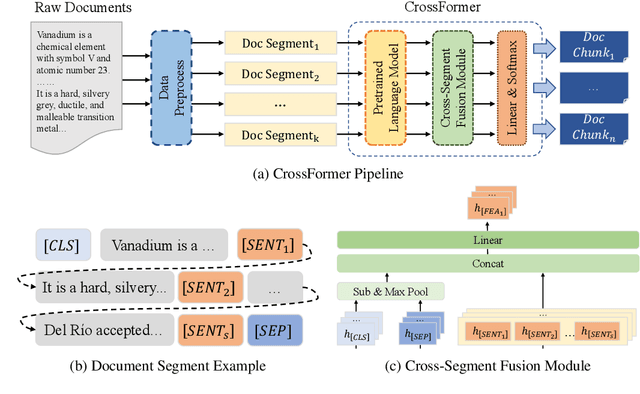
Text semantic segmentation involves partitioning a document into multiple paragraphs with continuous semantics based on the subject matter, contextual information, and document structure. Traditional approaches have typically relied on preprocessing documents into segments to address input length constraints, resulting in the loss of critical semantic information across segments. To address this, we present CrossFormer, a transformer-based model featuring a novel cross-segment fusion module that dynamically models latent semantic dependencies across document segments, substantially elevating segmentation accuracy. Additionally, CrossFormer can replace rule-based chunk methods within the Retrieval-Augmented Generation (RAG) system, producing more semantically coherent chunks that enhance its efficacy. Comprehensive evaluations confirm CrossFormer's state-of-the-art performance on public text semantic segmentation datasets, alongside considerable gains on RAG benchmarks.
Towards Stable, Globally Expressive Graph Representations with Laplacian Eigenvectors
Oct 13, 2024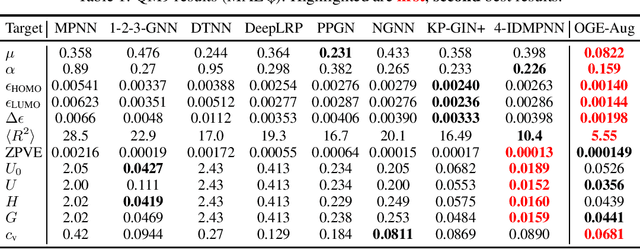
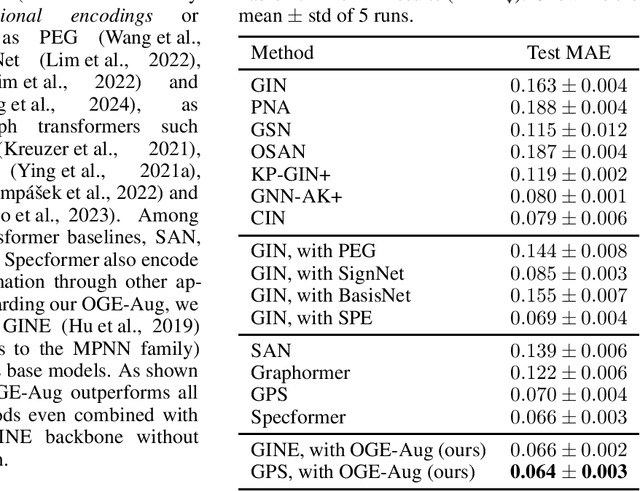

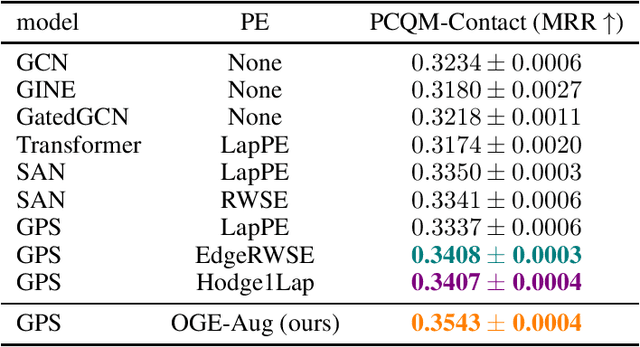
Graph neural networks (GNNs) have achieved remarkable success in a variety of machine learning tasks over graph data. Existing GNNs usually rely on message passing, i.e., computing node representations by gathering information from the neighborhood, to build their underlying computational graphs. They are known fairly limited in expressive power, and often fail to capture global characteristics of graphs. To overcome the issue, a popular solution is to use Laplacian eigenvectors as additional node features, as they contain global positional information of nodes, and can serve as extra node identifiers aiding GNNs to separate structurally similar nodes. For such an approach, properly handling the orthogonal group symmetry among eigenvectors with equal eigenvalue is crucial for its stability and generalizability. However, using a naive orthogonal group invariant encoder for each separate eigenspace may not keep the full expressivity in the Laplacian eigenvectors. Moreover, computing such invariants inevitably entails a hard split of Laplacian eigenvalues according to their numerical identity, which suffers from great instability when the graph structure is perturbed. In this paper, we propose a novel method exploiting Laplacian eigenvectors to generate stable and globally expressive graph representations. The main difference from previous works is that (i) our method utilizes learnable orthogonal group invariant representations for each Laplacian eigenspace, based upon powerful orthogonal group equivariant neural network layers already well studied in the literature, and that (ii) our method deals with numerically close eigenvalues in a smooth fashion, ensuring its better robustness against perturbations. Experiments on various graph learning benchmarks witness the competitive performance of our method, especially its great potential to learn global properties of graphs.
Fine-Grained Expressive Power of Weisfeiler-Leman: A Homomorphism Counting Perspective
Oct 04, 2024The ability of graph neural networks (GNNs) to count homomorphisms has recently been proposed as a practical and fine-grained measure of their expressive power. Although several existing works have investigated the homomorphism counting power of certain GNN families, a simple and unified framework for analyzing the problem is absent. In this paper, we first propose \emph{generalized folklore Weisfeiler-Leman (GFWL)} algorithms as a flexible design basis for expressive GNNs, and then provide a theoretical framework to algorithmically determine the homomorphism counting power of an arbitrary class of GNN within the GFWL design space. As the considered design space is large enough to accommodate almost all known powerful GNNs, our result greatly extends all existing works, and may find its application in the automation of GNN model design.
Distance-Restricted Folklore Weisfeiler-Leman GNNs with Provable Cycle Counting Power
Sep 10, 2023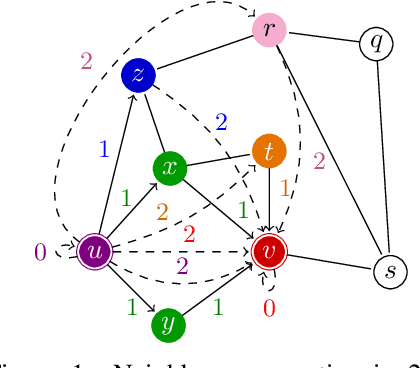
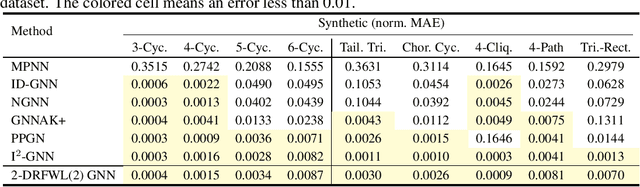
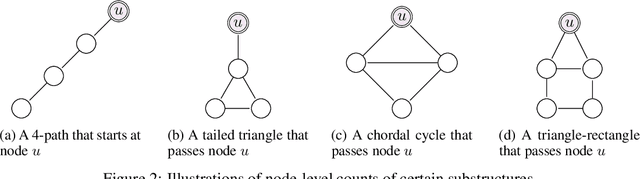
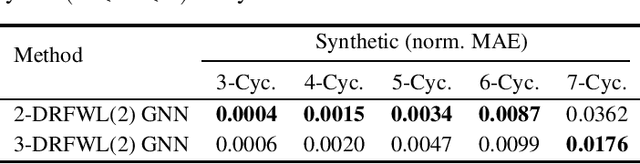
The ability of graph neural networks (GNNs) to count certain graph substructures, especially cycles, is important for the success of GNNs on a wide range of tasks. It has been recently used as a popular metric for evaluating the expressive power of GNNs. Many of the proposed GNN models with provable cycle counting power are based on subgraph GNNs, i.e., extracting a bag of subgraphs from the input graph, generating representations for each subgraph, and using them to augment the representation of the input graph. However, those methods require heavy preprocessing, and suffer from high time and memory costs. In this paper, we overcome the aforementioned limitations of subgraph GNNs by proposing a novel class of GNNs -- $d$-Distance-Restricted FWL(2) GNNs, or $d$-DRFWL(2) GNNs. $d$-DRFWL(2) GNNs use node pairs whose mutual distances are at most $d$ as the units for message passing to balance the expressive power and complexity. By performing message passing among distance-restricted node pairs in the original graph, $d$-DRFWL(2) GNNs avoid the expensive subgraph extraction operations in subgraph GNNs, making both the time and space complexity lower. We theoretically show that the discriminative power of $d$-DRFWL(2) GNNs strictly increases as $d$ increases. More importantly, $d$-DRFWL(2) GNNs have provably strong cycle counting power even with $d=2$: they can count all 3, 4, 5, 6-cycles. Since 6-cycles (e.g., benzene rings) are ubiquitous in organic molecules, being able to detect and count them is crucial for achieving robust and generalizable performance on molecular tasks. Experiments on both synthetic datasets and molecular datasets verify our theory. To the best of our knowledge, our model is the most efficient GNN model to date (both theoretically and empirically) that can count up to 6-cycles.
Efficiently Counting Substructures by Subgraph GNNs without Running GNN on Subgraphs
Mar 19, 2023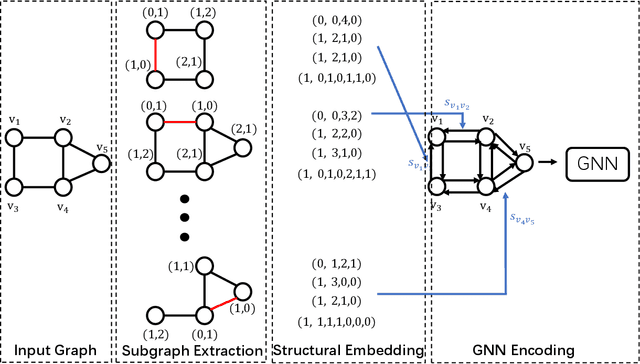
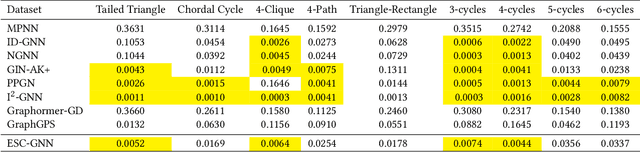
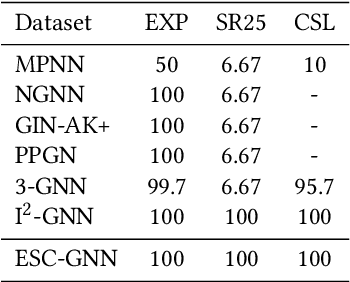
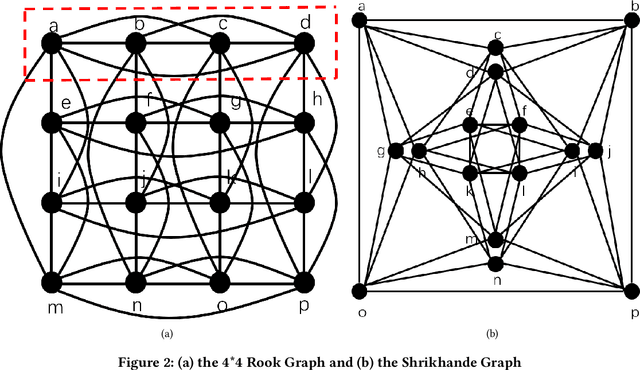
Using graph neural networks (GNNs) to approximate specific functions such as counting graph substructures is a recent trend in graph learning. Among these works, a popular way is to use subgraph GNNs, which decompose the input graph into a collection of subgraphs and enhance the representation of the graph by applying GNN to individual subgraphs. Although subgraph GNNs are able to count complicated substructures, they suffer from high computational and memory costs. In this paper, we address a non-trivial question: can we count substructures efficiently with GNNs? To answer the question, we first theoretically show that the distance to the rooted nodes within subgraphs is key to boosting the counting power of subgraph GNNs. We then encode such information into structural embeddings, and precompute the embeddings to avoid extracting information over all subgraphs via GNNs repeatedly. Experiments on various benchmarks show that the proposed model can preserve the counting power of subgraph GNNs while running orders of magnitude faster.
Head-driven Phrase Structure Parsing in O Time Complexity
May 20, 2021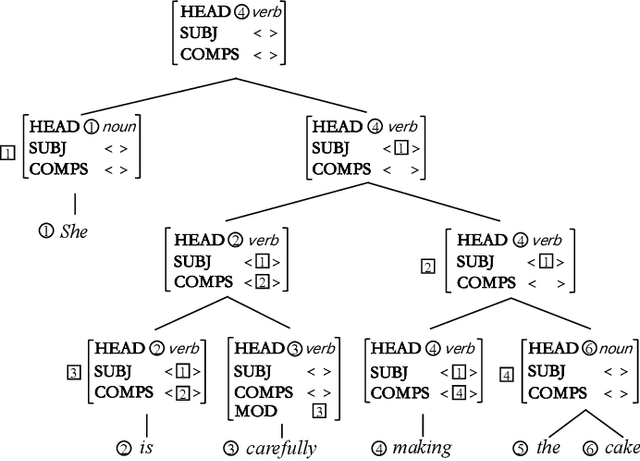
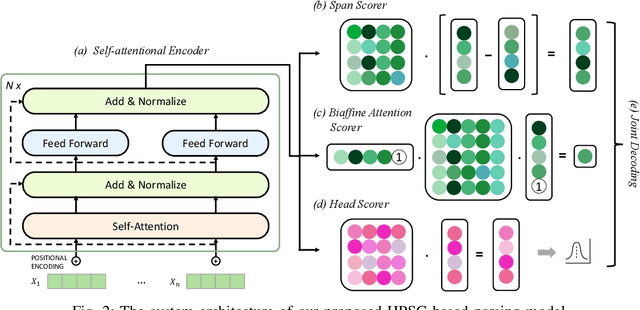
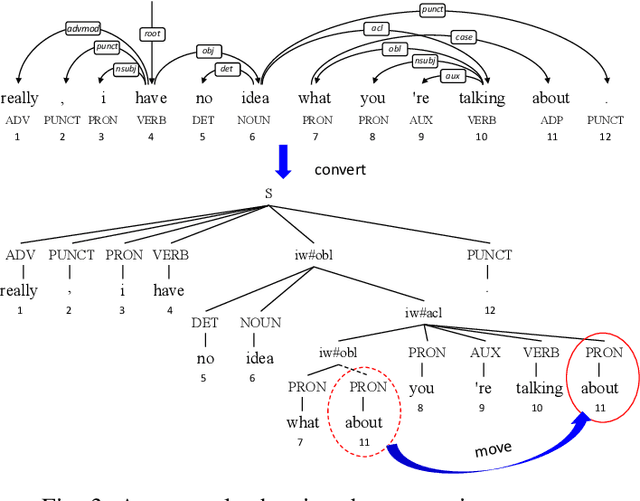
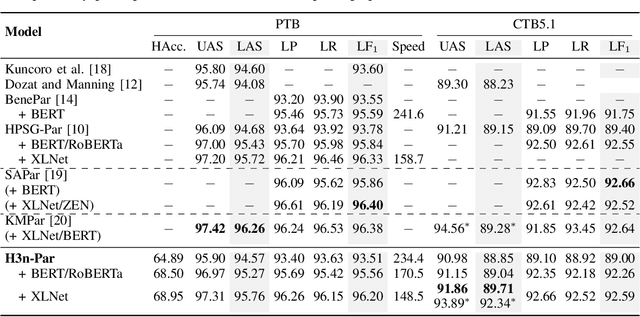
Constituent and dependency parsing, the two classic forms of syntactic parsing, have been found to benefit from joint training and decoding under a uniform formalism, Head-driven Phrase Structure Grammar (HPSG). However, decoding this unified grammar has a higher time complexity ($O(n^5)$) than decoding either form individually ($O(n^3)$) since more factors have to be considered during decoding. We thus propose an improved head scorer that helps achieve a novel performance-preserved parser in $O$($n^3$) time complexity. Furthermore, on the basis of this proposed practical HPSG parser, we investigated the strengths of HPSG-based parsing and explored the general method of training an HPSG-based parser from only a constituent or dependency annotations in a multilingual scenario. We thus present a more effective, more in-depth, and general work on HPSG parsing.
SG-Net: Syntax Guided Transformer for Language Representation
Jan 07, 2021


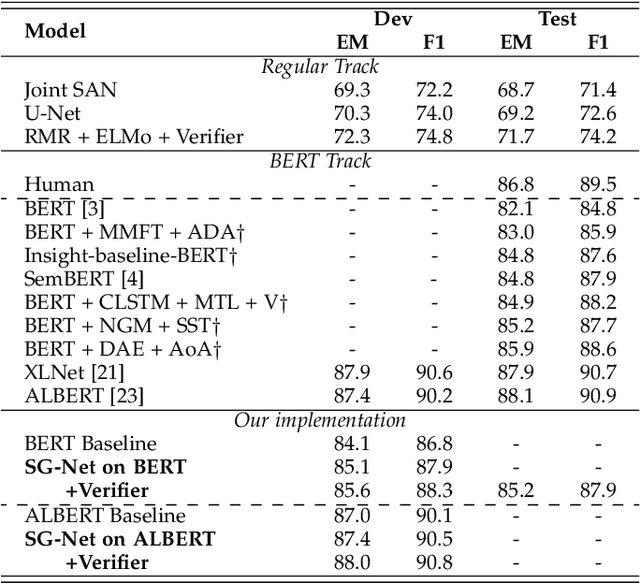
Understanding human language is one of the key themes of artificial intelligence. For language representation, the capacity of effectively modeling the linguistic knowledge from the detail-riddled and lengthy texts and getting rid of the noises is essential to improve its performance. Traditional attentive models attend to all words without explicit constraint, which results in inaccurate concentration on some dispensable words. In this work, we propose using syntax to guide the text modeling by incorporating explicit syntactic constraints into attention mechanisms for better linguistically motivated word representations. In detail, for self-attention network (SAN) sponsored Transformer-based encoder, we introduce syntactic dependency of interest (SDOI) design into the SAN to form an SDOI-SAN with syntax-guided self-attention. Syntax-guided network (SG-Net) is then composed of this extra SDOI-SAN and the SAN from the original Transformer encoder through a dual contextual architecture for better linguistics inspired representation. The proposed SG-Net is applied to typical Transformer encoders. Extensive experiments on popular benchmark tasks, including machine reading comprehension, natural language inference, and neural machine translation show the effectiveness of the proposed SG-Net design.
Semantics-Aware Inferential Network for Natural Language Understanding
Apr 28, 2020
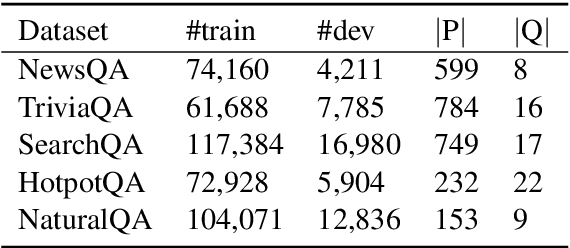
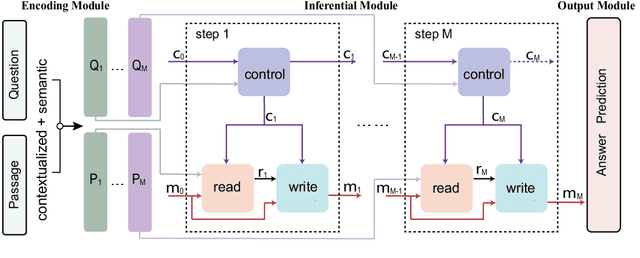
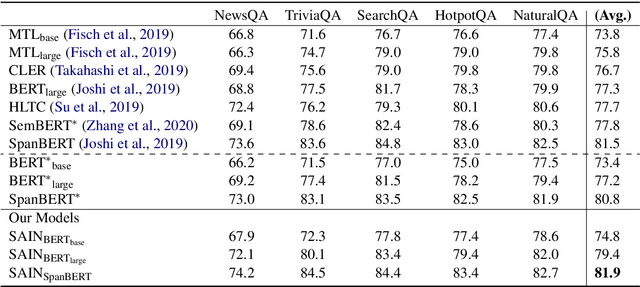
For natural language understanding tasks, either machine reading comprehension or natural language inference, both semantics-aware and inference are favorable features of the concerned modeling for better understanding performance. Thus we propose a Semantics-Aware Inferential Network (SAIN) to meet such a motivation. Taking explicit contextualized semantics as a complementary input, the inferential module of SAIN enables a series of reasoning steps over semantic clues through an attention mechanism. By stringing these steps, the inferential network effectively learns to perform iterative reasoning which incorporates both explicit semantics and contextualized representations. In terms of well pre-trained language models as front-end encoder, our model achieves significant improvement on 11 tasks including machine reading comprehension and natural language inference.
Dependency and Span, Cross-Style Semantic Role Labeling on PropBank and NomBank
Nov 07, 2019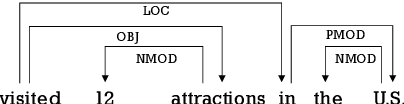

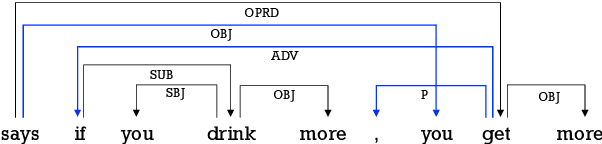

The latest developments in neural semantic role labeling (SRL), including both dependency and span representation formalisms, have shown great performance improvements. Although the two styles share many similarities in linguistic meaning and computation, most previous studies focus on a single style. In this paper, we define a new cross-style semantic role label convention and propose a new cross-style joint optimization model designed according to the linguistic meaning of semantic role, which provides an agreed way to make the results of two styles more comparable and let both types of SRL enjoy their natural connection on both linguistics and computation. Our model learns a general semantic argument structure and is capable of outputting optional style alone. Additionally, we propose a syntax aided method to enhance the learning of both dependency and span representations uniformly. Experiments show that the proposed methods are effective on both span (CoNLL-2005) and dependency (CoNLL-2009) SRL benchmarks.