 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Latent Tokens Think? A Causal and Adversarial Analysis of Chain-of-Continuous-Thought
Dec 25, 2025Latent tokens are gaining attention for enhancing reasoning in large language models (LLMs), yet their internal mechanisms remain unclear. This paper examines the problem from a reliability perspective, uncovering fundamental weaknesses: latent tokens function as uninterpretable placeholders rather than encoding faithful reasoning. While resistant to perturbation, they promote shortcut usage over genuine reasoning. We focus on Chain-of-Continuous-Thought (COCONUT), which claims better efficiency and stability than explicit Chain-of-Thought (CoT) while maintaining performance. We investigate this through two complementary approaches. First, steering experiments perturb specific token subsets, namely COCONUT and explicit CoT. Unlike CoT tokens, COCONUT tokens show minimal sensitivity to steering and lack reasoning-critical information. Second, shortcut experiments evaluate models under biased and out-of-distribution settings. Results on MMLU and HotpotQA demonstrate that COCONUT consistently exploits dataset artifacts, inflating benchmark performance without true reasoning. These findings reposition COCONUT as a pseudo-reasoning mechanism: it generates plausible traces that conceal shortcut dependence rather than faithfully representing reasoning processes.
Keep the General, Inject the Specific: Structured Dialogue Fine-Tuning for Knowledge Injection without Catastrophic Forgetting
Apr 27, 2025
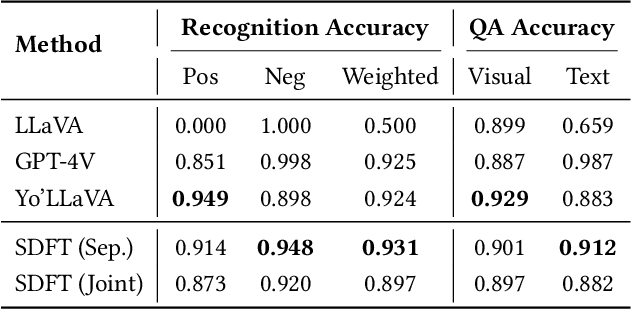
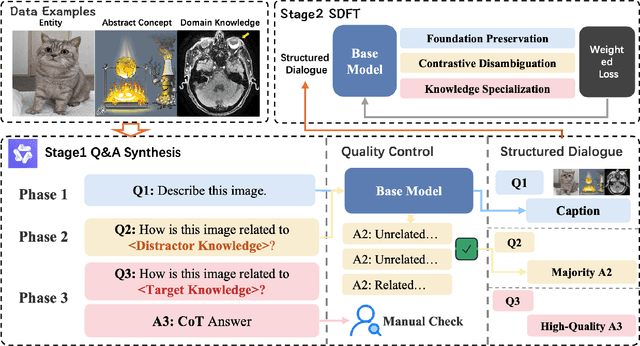

Large Vision Language Models have demonstrated impressive versatile capabilities through extensive multimodal pre-training, but face significant limitations when incorporating specialized knowledge domains beyond their training distribution. These models struggle with a fundamental dilemma: direct adaptation approaches that inject domain-specific knowledge often trigger catastrophic forgetting of foundational visual-linguistic abilities. We introduce Structured Dialogue Fine-Tuning (SDFT), an effective approach that effectively injects domain-specific knowledge while minimizing catastrophic forgetting. Drawing inspiration from supervised fine-tuning in LLMs and subject-driven personalization in text-to-image diffusion models, our method employs a three-phase dialogue structure: Foundation Preservation reinforces pre-trained visual-linguistic alignment through caption tasks; Contrastive Disambiguation introduces carefully designed counterfactual examples to maintain semantic boundaries; and Knowledge Specialization embeds specialized information through chain-of-thought reasoning. Experimental results across multiple domains confirm SDFT's effectiveness in balancing specialized knowledge acquisition with general capability retention. Our key contributions include a data-centric dialogue template that balances foundational alignment with targeted knowledge integration, a weighted multi-turn supervision framework, and comprehensive evaluation across diverse knowledge types.
Probing then Editing Response Personality of Large Language Models
Apr 14, 2025Large Language Models (LLMs) have demonstrated promising capabilities to generate responses that exhibit consistent personality traits. Despite the major attempts to analyze personality expression through output-based evaluations, little is known about how such traits are internally encoded within LLM parameters. In this paper, we introduce a layer-wise probing framework to systematically investigate the layer-wise capability of LLMs in encoding personality for responding. We conduct probing experiments on 11 open-source LLMs over the PersonalityEdit benchmark and find that LLMs predominantly encode personality for responding in their middle and upper layers, with instruction-tuned models demonstrating a slightly clearer separation of personality traits. Furthermore, by interpreting the trained probing hyperplane as a layer-wise boundary for each personality category, we propose a layer-wise perturbation method to edit the personality expressed by LLMs during inference. Our results show that even when the prompt explicitly specifies a particular personality, our method can still successfully alter the response personality of LLMs. Interestingly, the difficulty of converting between certain personality traits varies substantially, which aligns with the representational distances in our probing experiments. Finally, we conduct a comprehensive MMLU benchmark evaluation and time overhead analysis, demonstrating that our proposed personality editing method incurs only minimal degradation in general capabilities while maintaining low training costs and acceptable inference latency. Our code is publicly available at https://github.com/universe-sky/probing-then-editing-personality.
Improving Non-autoregressive Machine Translation with Error Exposure and Consistency Regularization
Feb 15, 2024Being one of the IR-NAT (Iterative-refinemennt-based NAT) frameworks, the Conditional Masked Language Model (CMLM) adopts the mask-predict paradigm to re-predict the masked low-confidence tokens. However, CMLM suffers from the data distribution discrepancy between training and inference, where the observed tokens are generated differently in the two cases. In this paper, we address this problem with the training approaches of error exposure and consistency regularization (EECR). We construct the mixed sequences based on model prediction during training, and propose to optimize over the masked tokens under imperfect observation conditions. We also design a consistency learning method to constrain the data distribution for the masked tokens under different observing situations to narrow down the gap between training and inference. The experiments on five translation benchmarks obtains an average improvement of 0.68 and 0.40 BLEU scores compared to the base models, respectively, and our CMLMC-EECR achieves the best performance with a comparable translation quality with the Transformer. The experiments results demonstrate the effectiveness of our method.
Multi-grained Evidence Inference for Multi-choice Reading Comprehension
Oct 27, 2023

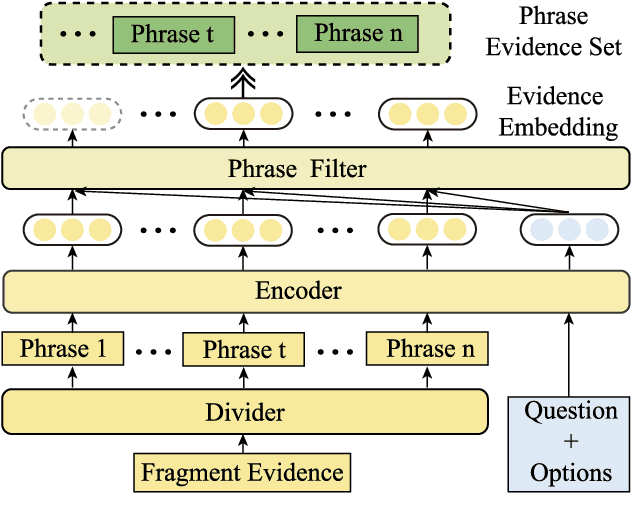

Multi-choice Machine Reading Comprehension (MRC) is a major and challenging task for machines to answer questions according to provided options. Answers in multi-choice MRC cannot be directly extracted in the given passages, and essentially require machines capable of reasoning from accurate extracted evidence. However, the critical evidence may be as simple as just one word or phrase, while it is hidden in the given redundant, noisy passage with multiple linguistic hierarchies from phrase, fragment, sentence until the entire passage. We thus propose a novel general-purpose model enhancement which integrates multi-grained evidence comprehensively, named Multi-grained evidence inferencer (Mugen), to make up for the inability. Mugen extracts three different granularities of evidence: coarse-, middle- and fine-grained evidence, and integrates evidence with the original passages, achieving significant and consistent performance improvement on four multi-choice MRC benchmarks.
* Accepted by TASLP 2023, vol. 31, pp. 3896-3907
To Understand Representation of Layer-aware Sequence Encoders as Multi-order-graph
Jan 16, 2021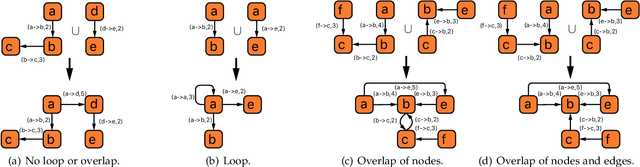
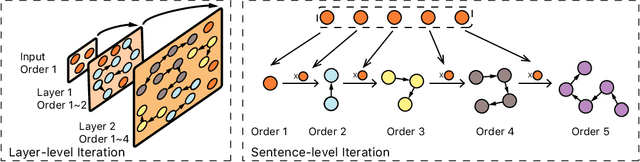
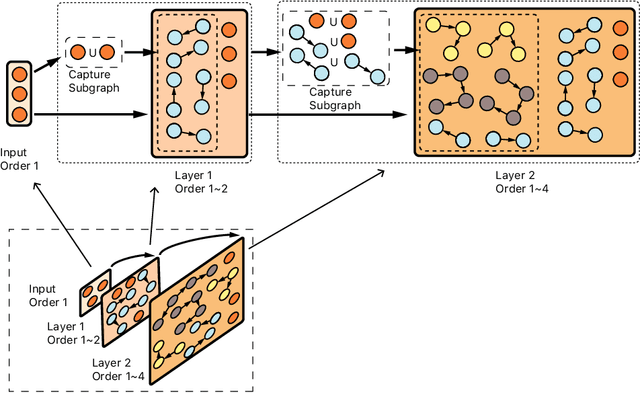
In this paper, we propose a unified explanation of representation for layer-aware neural sequence encoders, which regards the representation as a revisited multigraph called multi-order-graph (MoG), so that model encoding can be viewed as a processing to capture all subgraphs in MoG. The relationship reflected by Multi-order-graph, called $n$-order dependency, can present what existing simple directed graph explanation cannot present. Our proposed MoG explanation allows to precisely observe every step of the generation of representation, put diverse relationship such as syntax into a unifiedly depicted framework. Based on the proposed MoG explanation, we further propose a graph-based self-attention network empowered Graph-Transformer by enhancing the ability of capturing subgraph information over the current models. Graph-Transformer accommodates different subgraphs into different groups, which allows model to focus on salient subgraphs. Result of experiments on neural machine translation tasks show that the MoG-inspired model can yield effective performance improvement.
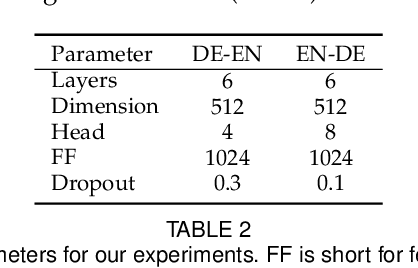
SG-Net: Syntax Guided Transformer for Language Representation
Jan 07, 2021


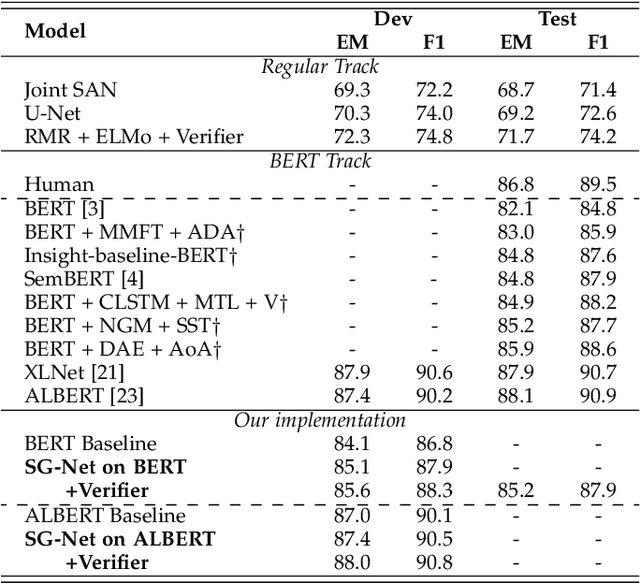
Understanding human language is one of the key themes of artificial intelligence. For language representation, the capacity of effectively modeling the linguistic knowledge from the detail-riddled and lengthy texts and getting rid of the noises is essential to improve its performance. Traditional attentive models attend to all words without explicit constraint, which results in inaccurate concentration on some dispensable words. In this work, we propose using syntax to guide the text modeling by incorporating explicit syntactic constraints into attention mechanisms for better linguistically motivated word representations. In detail, for self-attention network (SAN) sponsored Transformer-based encoder, we introduce syntactic dependency of interest (SDOI) design into the SAN to form an SDOI-SAN with syntax-guided self-attention. Syntax-guided network (SG-Net) is then composed of this extra SDOI-SAN and the SAN from the original Transformer encoder through a dual contextual architecture for better linguistics inspired representation. The proposed SG-Net is applied to typical Transformer encoders. Extensive experiments on popular benchmark tasks, including machine reading comprehension, natural language inference, and neural machine translation show the effectiveness of the proposed SG-Net design.
Graph-to-Sequence Neural Machine Translation
Sep 16, 2020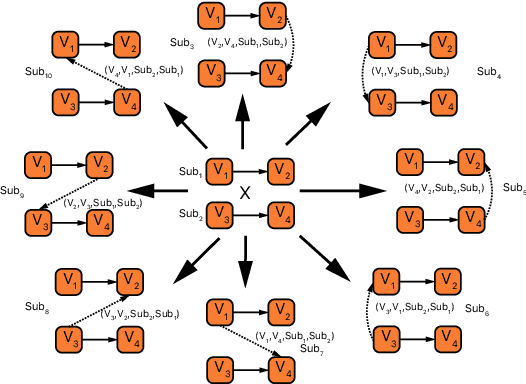
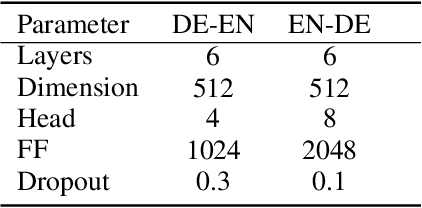
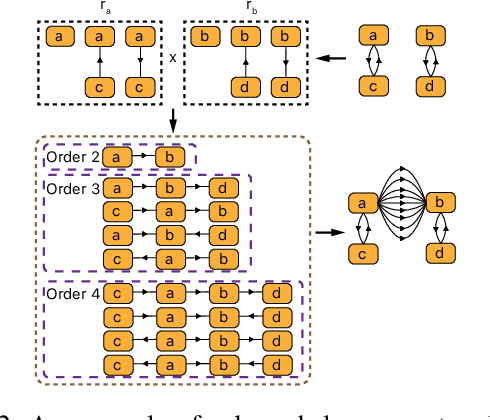
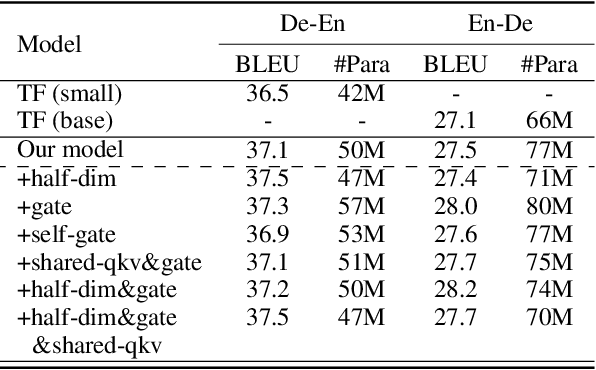
Neural machine translation (NMT) usually works in a seq2seq learning way by viewing either source or target sentence as a linear sequence of words, which can be regarded as a special case of graph, taking words in the sequence as nodes and relationships between words as edges. In the light of the current NMT models more or less capture graph information among the sequence in a latent way, we present a graph-to-sequence model facilitating explicit graph information capturing. In detail, we propose a graph-based SAN-based NMT model called Graph-Transformer by capturing information of subgraphs of different orders in every layers. Subgraphs are put into different groups according to their orders, and every group of subgraphs respectively reflect different levels of dependency between words. For fusing subgraph representations, we empirically explore three methods which weight different groups of subgraphs of different orders. Results of experiments on WMT14 English-German and IWSLT14 German-English show that our method can effectively boost the Transformer with an improvement of 1.1 BLEU points on WMT14 English-German dataset and 1.0 BLEU points on IWSLT14 German-English dataset.
Capsule-Transformer for Neural Machine Translation
Apr 30, 2020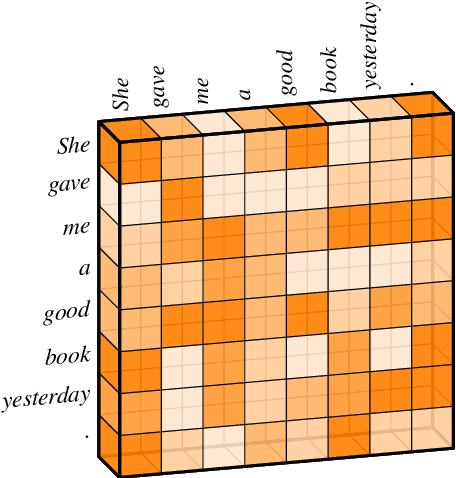

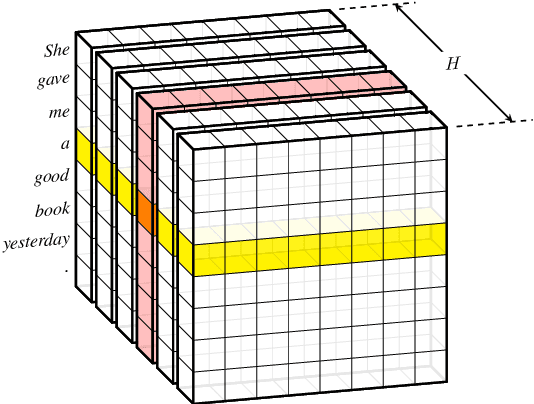
Transformer hugely benefits from its key design of the multi-head self-attention network (SAN), which extracts information from various perspectives through transforming the given input into different subspaces. However, its simple linear transformation aggregation strategy may still potentially fail to fully capture deeper contextualized information. In this paper, we thus propose the capsule-Transformer, which extends the linear transformation into a more general capsule routing algorithm by taking SAN as a special case of capsule network. So that the resulted capsule-Transformer is capable of obtaining a better attention distribution representation of the input sequence via information aggregation among different heads and words. Specifically, we see groups of attention weights in SAN as low layer capsules. By applying the iterative capsule routing algorithm they can be further aggregated into high layer capsules which contain deeper contextualized information. Experimental results on the widely-used machine translation datasets show our proposed capsule-Transformer outperforms strong Transformer baseline significantly.
Syntax-aware Data Augmentation for Neural Machine Translation
Apr 29, 2020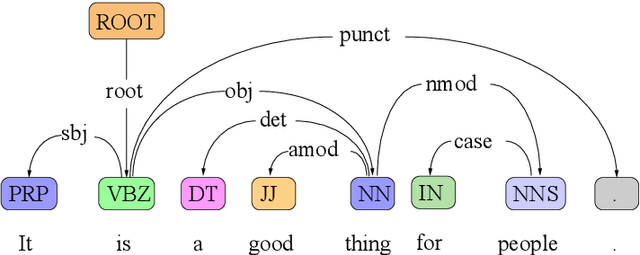
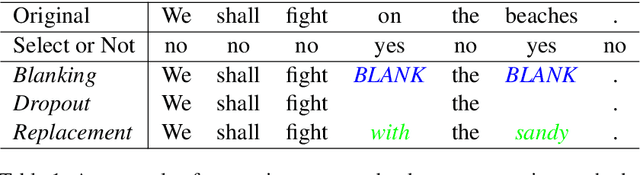
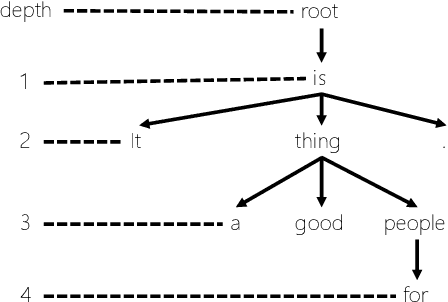
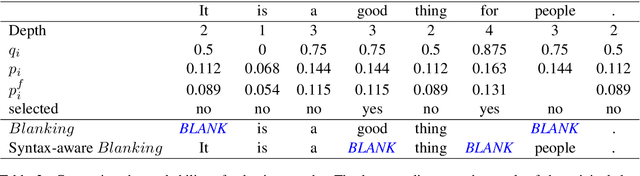
Data augmentation is an effective performance enhancement in neural machine translation (NMT) by generating additional bilingual data. In this paper, we propose a novel data augmentation enhancement strategy for neural machine translation. Different from existing data augmentation methods which simply choose words with the same probability across different sentences for modification, we set sentence-specific probability for word selection by considering their roles in sentence. We use dependency parse tree of input sentence as an effective clue to determine selecting probability for every words in each sentence. Our proposed method is evaluated on WMT14 English-to-German dataset and IWSLT14 German-to-English dataset. The result of extensive experiments show our proposed syntax-aware data augmentation method may effectively boost existing sentence-independent methods for significant translation performance improvement.