 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeep the General, Inject the Specific: Structured Dialogue Fine-Tuning for Knowledge Injection without Catastrophic Forgetting
Apr 27, 2025
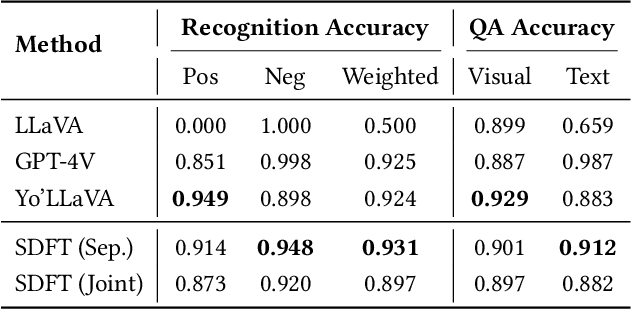
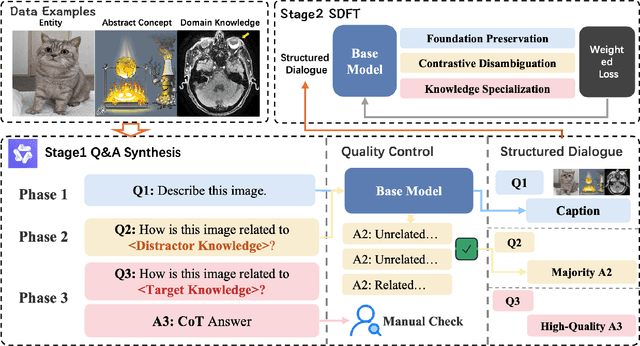

Large Vision Language Models have demonstrated impressive versatile capabilities through extensive multimodal pre-training, but face significant limitations when incorporating specialized knowledge domains beyond their training distribution. These models struggle with a fundamental dilemma: direct adaptation approaches that inject domain-specific knowledge often trigger catastrophic forgetting of foundational visual-linguistic abilities. We introduce Structured Dialogue Fine-Tuning (SDFT), an effective approach that effectively injects domain-specific knowledge while minimizing catastrophic forgetting. Drawing inspiration from supervised fine-tuning in LLMs and subject-driven personalization in text-to-image diffusion models, our method employs a three-phase dialogue structure: Foundation Preservation reinforces pre-trained visual-linguistic alignment through caption tasks; Contrastive Disambiguation introduces carefully designed counterfactual examples to maintain semantic boundaries; and Knowledge Specialization embeds specialized information through chain-of-thought reasoning. Experimental results across multiple domains confirm SDFT's effectiveness in balancing specialized knowledge acquisition with general capability retention. Our key contributions include a data-centric dialogue template that balances foundational alignment with targeted knowledge integration, a weighted multi-turn supervision framework, and comprehensive evaluation across diverse knowledge types.
InsightVision: A Comprehensive, Multi-Level Chinese-based Benchmark for Evaluating Implicit Visual Semantics in Large Vision Language Models
Feb 19, 2025



In the evolving landscape of multimodal language models, understanding the nuanced meanings conveyed through visual cues - such as satire, insult, or critique - remains a significant challenge. Existing evaluation benchmarks primarily focus on direct tasks like image captioning or are limited to a narrow set of categories, such as humor or satire, for deep semantic understanding. To address this gap, we introduce, for the first time, a comprehensive, multi-level Chinese-based benchmark designed specifically for evaluating the understanding of implicit meanings in images. This benchmark is systematically categorized into four subtasks: surface-level content understanding, symbolic meaning interpretation, background knowledge comprehension, and implicit meaning comprehension. We propose an innovative semi-automatic method for constructing datasets, adhering to established construction protocols. Using this benchmark, we evaluate 15 open-source large vision language models (LVLMs) and GPT-4o, revealing that even the best-performing model lags behind human performance by nearly 14% in understanding implicit meaning. Our findings underscore the intrinsic challenges current LVLMs face in grasping nuanced visual semantics, highlighting significant opportunities for future research and development in this domain. We will publicly release our InsightVision dataset, code upon acceptance of the paper.