 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciRisk-Bench: A Risk-Dimension-Aware Benchmark for AI4Science Safety
Jun 17, 2026Large language models (LLMs) are increasingly embedded in AI for Science (AI4Science) workflows, from scientific question answering and literature analysis to laboratory planning and autonomous discovery. This progress creates an urgent need for safety benchmarks that evaluate not only scientific competence, but also whether models recognize and avoid risks in high-stakes scientific contexts. Existing AI4Science safety datasets cover several disciplines and task formats, leaving the underlying risk dimensions underspecified. We introduce \textbf{SciRisk-Bench}, a benchmark designed to evaluate AI4Science safety from two complementary perspectives: explicit risk dimensions and scientific disciplines. SciRisk-Bench covers 7 disciplines, 31 subdisciplines and 10 risk dimensions. In the experimental section, we evaluate both mainstream LLMs and science-oriented LLMs across risk dimensions, disciplines, and sub-disciplines, enabling fine-grained diagnosis of where scientific models remain unsafe.
Cosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
LiveK12Bench: Have Large Multimodal Models Truly Conquered High School-level Examinations?
May 26, 2026Advanced Large Multimodal Models (LMMs) have demonstrated impressive performance in K-12 reasoning tasks, exhibiting great promise as intelligent tutors. Realizing this potential requires models to navigate real-world examinations effectively, yet most existing benchmarks fail to capture the complexity of authentic testing environments. Specifically, most datasets are static, prone to data contamination, and are often confined to restricted modalities, disciplines, and evaluation criteria. To address these issues, we introduce LiveK12Bench, a dynamic, holistic, multi-disciplinary benchmark designed to evaluate the reasoning abilities of LMMs in realistic examination scenarios. LiveK12Bench comprises 2K+ verified questions spanning Mathematics, Physics, Chemistry, and Biology, sourced from the latest real-world exam papers and designed to grow over time. Our framework features several core innovations: 1) featuring an automated pipeline that continuously ingests and parses the latest examination papers to mitigate data leakage; and 2) proposing a novel `Mock Exam' evaluation scheme, which assesses the ability to complete end-to-end exams autonomously with accurate and efficient reasoning paths. Extensive experiments on 12 LMMs reveal that advanced models suffer substantial performance degradation under exam-realistic constraints: GPT-5's score drops from 79 to 53 (out of 100) when process rigor and efficiency are jointly evaluated. Our findings expose critical vulnerabilities, such as sensitivity to complex visual layouts, highlighting the gap between idealized reasoning capabilities and true educational readiness. Both code and dataset are publicly available.
Action Images: End-to-End Policy Learning via Multiview Video Generation
Apr 07, 2026World action models (WAMs) have emerged as a promising direction for robot policy learning, as they can leverage powerful video backbones to model the future states. However, existing approaches often rely on separate action modules, or use action representations that are not pixel-grounded, making it difficult to fully exploit the pretrained knowledge of video models and limiting transfer across viewpoints and environments. In this work, we present Action Images, a unified world action model that formulates policy learning as multiview video generation. Instead of encoding control as low-dimensional tokens, we translate 7-DoF robot actions into interpretable action images: multi-view action videos that are grounded in 2D pixels and explicitly track robot-arm motion. This pixel-grounded action representation allows the video backbone itself to act as a zero-shot policy, without a separate policy head or action module. Beyond control, the same unified model supports video-action joint generation, action-conditioned video generation, and action labeling under a shared representation. On RLBench and real-world evaluations, our model achieves the strongest zero-shot success rates and improves video-action joint generation quality over prior video-space world models, suggesting that interpretable action images are a promising route to policy learning.
3D-Layout-R1: Structured Reasoning for Language-Instructed Spatial Editing
Mar 23, 2026Large Language Models (LLMs) and Vision Language Models (VLMs) have shown impressive reasoning abilities, yet they struggle with spatial understanding and layout consistency when performing fine-grained visual editing. We introduce a Structured Reasoning framework that performs text-conditioned spatial layout editing via scene-graph reasoning. Given an input scene graph and a natural-language instruction, the model reasons over the graph to generate an updated scene graph that satisfies the text condition while maintaining spatial coherence. By explicitly guiding the reasoning process through structured relational representations, our approach improves both interpretability and control over spatial relationships. We evaluate our method on a new text-guided layout editing benchmark encompassing sorting, spatial alignment, and room-editing tasks. Our training paradigm yields an average 15% improvement in IoU and 25% reduction in center-distance error compared to Chain of Thought Fine-tuning (CoT-SFT) and vanilla GRPO baselines. Compared to SOTA zero-shot LLMs, our best models achieve up to 20% higher mIoU, demonstrating markedly improved spatial precision.
DGA-Net: Enhancing SAM with Depth Prompting and Graph-Anchor Guidance for Camouflaged Object Detection
Jan 06, 2026To fully exploit depth cues in Camouflaged Object Detection (COD), we present DGA-Net, a specialized framework that adapts the Segment Anything Model (SAM) via a novel ``depth prompting" paradigm. Distinguished from existing approaches that primarily rely on sparse prompts (e.g., points or boxes), our method introduces a holistic mechanism for constructing and propagating dense depth prompts. Specifically, we propose a Cross-modal Graph Enhancement (CGE) module that synthesizes RGB semantics and depth geometric within a heterogeneous graph to form a unified guidance signal. Furthermore, we design an Anchor-Guided Refinement (AGR) module. To counteract the inherent information decay in feature hierarchies, AGR forges a global anchor and establishes direct non-local pathways to broadcast this guidance from deep to shallow layers, ensuring precise and consistent segmentation. Quantitative and qualitative experimental results demonstrate that our proposed DGA-Net outperforms the state-of-the-art COD methods.
Learning to Pose Problems: Reasoning-Driven and Solver-Adaptive Data Synthesis for Large Reasoning Models
Nov 13, 2025
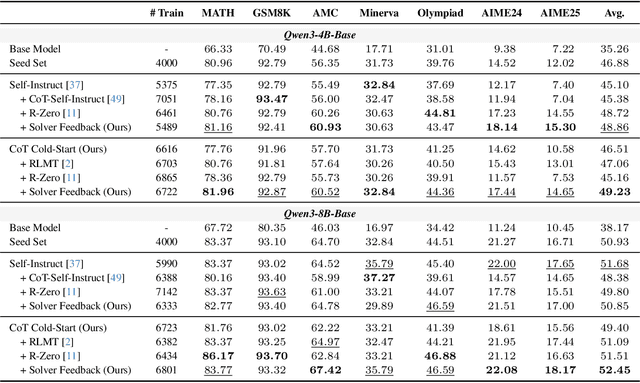

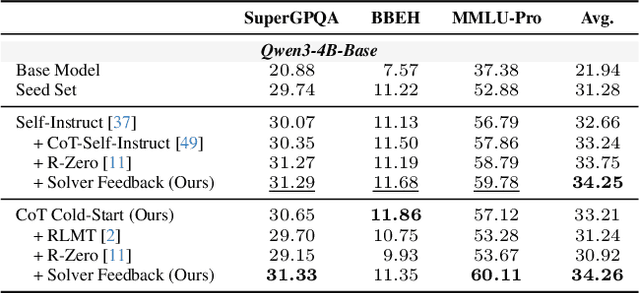
Data synthesis for training large reasoning models offers a scalable alternative to limited, human-curated datasets, enabling the creation of high-quality data. However, existing approaches face several challenges: (i) indiscriminate generation that ignores the solver's ability and yields low-value problems, or reliance on complex data pipelines to balance problem difficulty; and (ii) a lack of reasoning in problem generation, leading to shallow problem variants. In this paper, we develop a problem generator that reasons explicitly to plan problem directions before synthesis and adapts difficulty to the solver's ability. Specifically, we construct related problem pairs and augment them with intermediate problem-design CoT produced by a reasoning model. These data bootstrap problem-design strategies from the generator. Then, we treat the solver's feedback on synthetic problems as a reward signal, enabling the generator to calibrate difficulty and produce complementary problems near the edge of the solver's competence. Extensive experiments on 10 mathematical and general reasoning benchmarks show that our method achieves an average improvement of 2.5% and generalizes to both language and vision-language models. Moreover, a solver trained on the synthesized data provides improved rewards for continued generator training, enabling co-evolution and yielding a further 0.7% performance gain. Our code will be made publicly available here.
VoxelFormer: Parameter-Efficient Multi-Subject Visual Decoding from fMRI
Sep 10, 2025Recent advances in fMRI-based visual decoding have enabled compelling reconstructions of perceived images. However, most approaches rely on subject-specific training, limiting scalability and practical deployment. We introduce \textbf{VoxelFormer}, a lightweight transformer architecture that enables multi-subject training for visual decoding from fMRI. VoxelFormer integrates a Token Merging Transformer (ToMer) for efficient voxel compression and a query-driven Q-Former that produces fixed-size neural representations aligned with the CLIP image embedding space. Evaluated on the 7T Natural Scenes Dataset, VoxelFormer achieves competitive retrieval performance on subjects included during training with significantly fewer parameters than existing methods. These results highlight token merging and query-based transformers as promising strategies for parameter-efficient neural decoding.
Innovative Thinking, Infinite Humor: Humor Research of Large Language Models through Structured Thought Leaps
Oct 14, 2024



Humor is a culturally nuanced aspect of human language that presents challenges for understanding and generation, requiring participants to possess good creativity and strong associative thinking. Similar to reasoning tasks like solving math problems, humor generation requires continuous reflection and revision to foster creative thinking, rather than relying on a sudden flash of inspiration like Creative Leap-of-Thought (CLoT) paradigm. Although CLoT can realize the ability of remote association generation, this paradigm fails to generate humor content. Therefore, in this paper, we propose a systematic way of thinking about generating humor and based on it, we built Creative Leap of Structured Thought (CLoST) frame. First, a reward model is necessary achieve the purpose of being able to correct errors, since there is currently no expert model of humor and a usable rule to determine whether a piece of content is humorous. Judgement-oriented instructions are designed to improve the capability of a model, and we also propose an open-domain instruction evolutionary method to fully unleash the potential. Then, through reinforcement learning, the model learns to hone its rationales of the thought chain and refine the strategies it uses. Thus, it learns to recognize and correct its mistakes, and finally generate the most humorous and creative answer. These findings deepen our understanding of the creative capabilities of LLMs and provide ways to enhance LLMs' creative abilities for cross-domain innovative applications.
MetaTool: Facilitating Large Language Models to Master Tools with Meta-task Augmentation
Jul 15, 2024
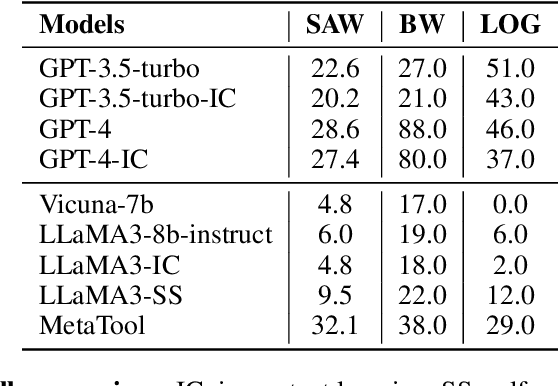
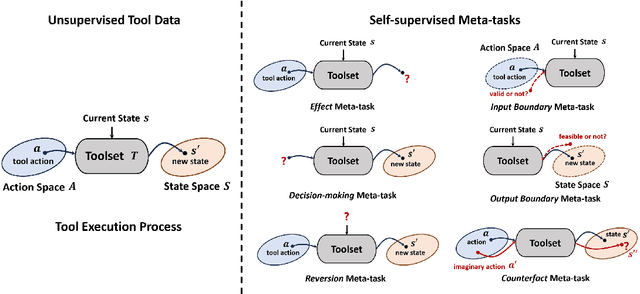
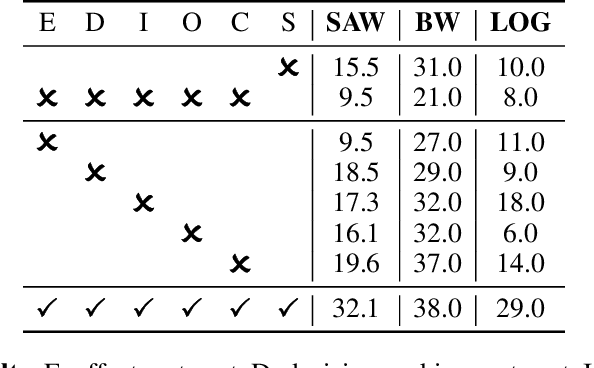
Utilizing complex tools with Large Language Models (LLMs) is a critical component for grounding AI agents in various real-world scenarios. The core challenge of manipulating tools lies in understanding their usage and functionality. The prevailing approach involves few-shot prompting with demonstrations or fine-tuning on expert trajectories. However, for complex tools and tasks, mere in-context demonstrations may fail to cover sufficient knowledge. Training-based methods are also constrained by the high cost of dataset construction and limited generalizability. In this paper, we introduce a new tool learning methodology (MetaTool) that is generalizable for mastering any reusable toolset. Our approach includes a self-supervised data augmentation technique that enables LLMs to gain a comprehensive understanding of various tools, thereby improving their ability to complete tasks effectively. We develop a series of meta-tasks that involve predicting masked factors of tool execution. These self-supervised tasks enable the automatic generation of high-quality QA data concerning tool comprehension. By incorporating meta-task data into the instruction tuning process, the proposed MetaTool model achieves significant superiority to open-source models and is comparable to GPT-4/GPT-3.5 on multiple tool-oriented tasks.