 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgescpFormer: A Foundation Model for Unified Representation and Integration of the Single-Cell Proteomics
Apr 21, 2026The integration of single-cell proteomic data is often hindered by the fragmented nature of targeted antibody panels. To address this limitation, we introduce scpFormer, a transformer-based foundation model designed for single-cell proteomics. Pre-trained on over 390 million cells, scpFormer replaces standard index-based tokenization with a continuous, sequence-anchored approach. By combining Evolutionary Scale Modeling (ESM) with value-aware expression embeddings, it dynamically maps variable panels into a shared semantic space without artificial discretization. We demonstrate that scpFormer generates global cell representations that perform competitively in large-scale batch integration and unsupervised clustering. Moreover, its open-vocabulary architecture facilitates in silico panel expansion, assisting in the reconstruction of biological manifolds in sparse clinical datasets. Finally, this learned protein co-expression logic is transferable to bulk-omics tasks, supporting applications like cancer drug response prediction. scpFormer provides a versatile, panel-agnostic framework to facilitate scalable biomarker discovery and precision oncology.
RE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
Feb 02, 2026LLM-based deep research agents are largely built on the ReAct framework. This linear design makes it difficult to revisit earlier states, branch into alternative search directions, or maintain global awareness under long contexts, often leading to local optima, redundant exploration, and inefficient search. We propose Re-TRAC, an agentic framework that performs cross-trajectory exploration by generating a structured state representation after each trajectory to summarize evidence, uncertainties, failures, and future plans, and conditioning subsequent trajectories on this state representation. This enables iterative reflection and globally informed planning, reframing research as a progressive process. Empirical results show that Re-TRAC consistently outperforms ReAct by 15-20% on BrowseComp with frontier LLMs. For smaller models, we introduce Re-TRAC-aware supervised fine-tuning, achieving state-of-the-art performance at comparable scales. Notably, Re-TRAC shows a monotonic reduction in tool calls and token usage across rounds, indicating progressively targeted exploration driven by cross-trajectory reflection rather than redundant search.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
GenePheno: Interpretable Gene Knockout-Induced Phenotype Abnormality Prediction from Gene Sequences
Nov 14, 2025
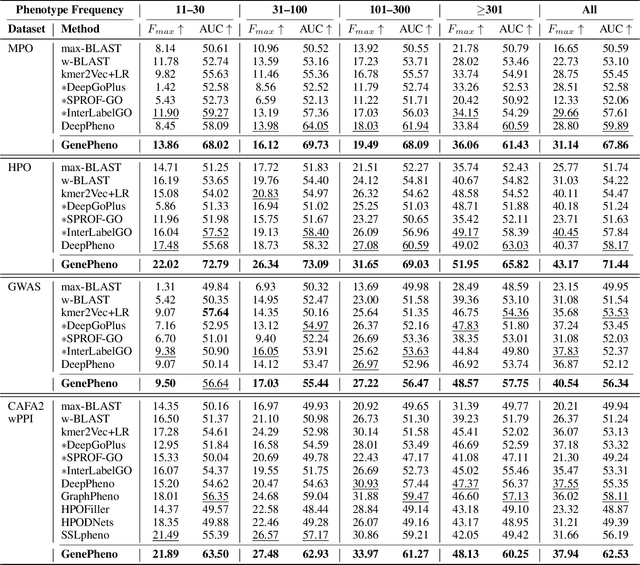
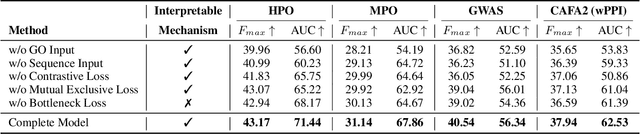
Exploring how genetic sequences shape phenotypes is a fundamental challenge in biology and a key step toward scalable, hypothesis-driven experimentation. The task is complicated by the large modality gap between sequences and phenotypes, as well as the pleiotropic nature of gene-phenotype relationships. Existing sequence-based efforts focus on the degree to which variants of specific genes alter a limited set of phenotypes, while general gene knockout induced phenotype abnormality prediction methods heavily rely on curated genetic information as inputs, which limits scalability and generalizability. As a result, the task of broadly predicting the presence of multiple phenotype abnormalities under gene knockout directly from gene sequences remains underexplored. We introduce GenePheno, the first interpretable multi-label prediction framework that predicts knockout induced phenotypic abnormalities from gene sequences. GenePheno employs a contrastive multi-label learning objective that captures inter-phenotype correlations, complemented by an exclusive regularization that enforces biological consistency. It further incorporates a gene function bottleneck layer, offering human interpretable concepts that reflect functional mechanisms behind phenotype formation. To support progress in this area, we curate four datasets with canonical gene sequences as input and multi-label phenotypic abnormalities induced by gene knockouts as targets. Across these datasets, GenePheno achieves state-of-the-art gene-centric $F_{\text{max}}$ and phenotype-centric AUC, and case studies demonstrate its ability to reveal gene functional mechanisms.
Aeolus: A Multi-structural Flight Delay Dataset
Oct 30, 2025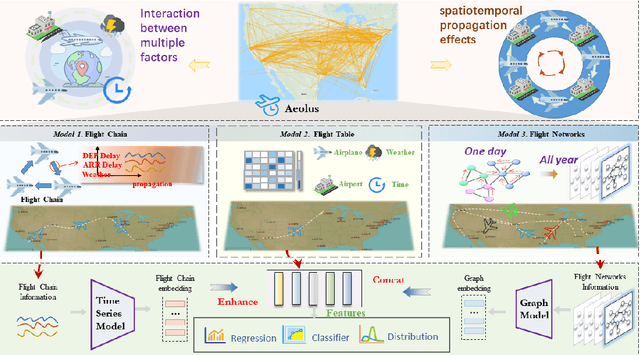
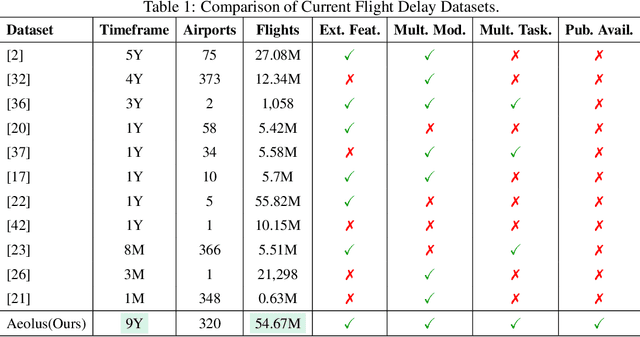
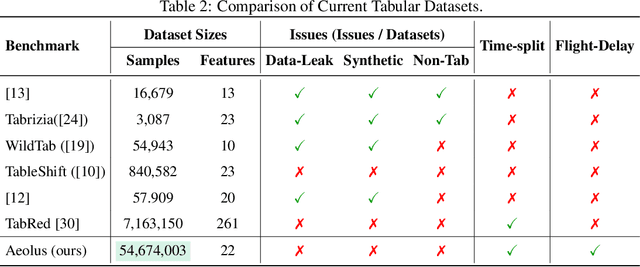
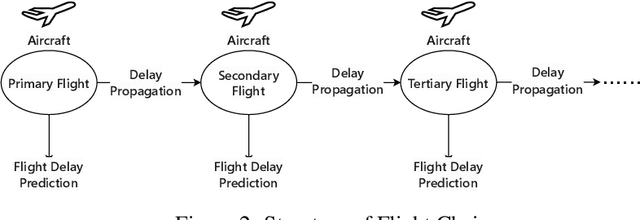
We introduce Aeolus, a large-scale Multi-modal Flight Delay Dataset designed to advance research on flight delay prediction and support the development of foundation models for tabular data. Existing datasets in this domain are typically limited to flat tabular structures and fail to capture the spatiotemporal dynamics inherent in delay propagation. Aeolus addresses this limitation by providing three aligned modalities: (i) a tabular dataset with rich operational, meteorological, and airportlevel features for over 50 million flights; (ii) a flight chain module that models delay propagation along sequential flight legs, capturing upstream and downstream dependencies; and (iii) a flight network graph that encodes shared aircraft, crew, and airport resource connections, enabling cross-flight relational reasoning. The dataset is carefully constructed with temporal splits, comprehensive features, and strict leakage prevention to support realistic and reproducible machine learning evaluation. Aeolus supports a broad range of tasks, including regression, classification, temporal structure modeling, and graph learning, serving as a unified benchmark across tabular, sequential, and graph modalities. We release baseline experiments and preprocessing tools to facilitate adoption. Aeolus fills a key gap for both domain-specific modeling and general-purpose structured data research.Our source code and data can be accessed at https://github.com/Flnny/Delay-data
CLAP: Coreference-Linked Augmentation for Passage Retrieval
Aug 09, 2025Large Language Model (LLM)-based passage expansion has shown promise for enhancing first-stage retrieval, but often underperforms with dense retrievers due to semantic drift and misalignment with their pretrained semantic space. Beyond this, only a portion of a passage is typically relevant to a query, while the rest introduces noise--an issue compounded by chunking techniques that break coreference continuity. We propose Coreference-Linked Augmentation for Passage Retrieval (CLAP), a lightweight LLM-based expansion framework that segments passages into coherent chunks, resolves coreference chains, and generates localized pseudo-queries aligned with dense retriever representations. A simple fusion of global topical signals and fine-grained subtopic signals achieves robust performance across domains. CLAP yields consistent gains even as retriever strength increases, enabling dense retrievers to match or surpass second-stage rankers such as BM25 + MonoT5-3B, with up to 20.68% absolute nDCG@10 improvement. These improvements are especially notable in out-of-domain settings, where conventional LLM-based expansion methods relying on domain knowledge often falter. CLAP instead adopts a logic-centric pipeline that enables robust, domain-agnostic generalization.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
ALPHAGMUT: A Rationale-Guided Alpha Shape Graph Neural Network to Evaluate Mutation Effects
Jun 13, 2024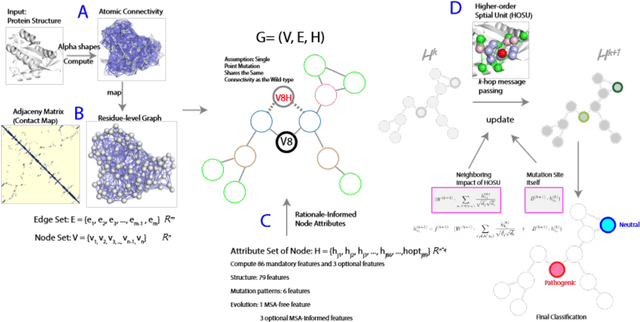



In silico methods evaluating the mutation effects of missense mutations are providing an important approach for understanding mutations in personal genomes and identifying disease-relevant biomarkers. However, existing methods, including deep learning methods, heavily rely on sequence-aware information, and do not fully leverage the potential of available 3D structural information. In addition, these methods may exhibit an inability to predict mutations in domains difficult to formulate sequence-based embeddings. In this study, we introduce a novel rationale-guided graph neural network AlphaGMut to evaluate mutation effects and to distinguish pathogenic mutations from neutral mutations. We compute the alpha shapes of protein structures to obtain atomic-resolution edge connectivities and map them to an accurate residue-level graph representation. We then compute structural-, topological-, biophysical-, and sequence properties of the mutation sites, which are assigned as node attributes in the graph. These node attributes could effectively guide the graph neural network to learn the difference between pathogenic and neutral mutations using k-hop message passing with a short training period. We demonstrate that AlphaGMut outperforms state-of-the-art methods, including DeepMind's AlphaMissense, in many performance metrics. In addition, AlphaGMut has the advantage of performing well in alignment-free settings, which provides broader prediction coverage and better generalization compared to current methods requiring deep sequence-aware information.
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
Apr 29, 2024Vision-language pre-training has significantly elevated performance across a wide range of image-language applications. Yet, the pre-training process for video-related tasks demands exceptionally large computational and data resources, which hinders the progress of video-language models. This paper investigates a straight-forward, highly efficient, and resource-light approach to adapting an existing image-language pre-trained model for dense video understanding. Our preliminary experiments reveal that directly fine-tuning pre-trained image-language models with multiple frames as inputs on video datasets leads to performance saturation or even a drop. Our further investigation reveals that it is largely attributed to the bias of learned high-norm visual features. Motivated by this finding, we propose a simple but effective pooling strategy to smooth the feature distribution along the temporal dimension and thus reduce the dominant impacts from the extreme features. The new model is termed Pooling LLaVA, or PLLaVA in short. PLLaVA achieves new state-of-the-art performance on modern benchmark datasets for both video question-answer and captioning tasks. Notably, on the recent popular VideoChatGPT benchmark, PLLaVA achieves a score of 3.48 out of 5 on average of five evaluated dimensions, exceeding the previous SOTA results from GPT4V (IG-VLM) by 9%. On the latest multi-choice benchmark MVBench, PLLaVA achieves 58.1% accuracy on average across 20 sub-tasks, 14.5% higher than GPT4V (IG-VLM). Code is available at https://pllava.github.io/
Chain of Thought Explanation for Dialogue State Tracking
Mar 09, 2024



Dialogue state tracking (DST) aims to record user queries and goals during a conversational interaction achieved by maintaining a predefined set of slots and their corresponding values. Current approaches decide slot values opaquely, while humans usually adopt a more deliberate approach by collecting information from relevant dialogue turns and then reasoning the appropriate values. In this work, we focus on the steps needed to figure out slot values by proposing a model named Chain-of-Thought-Explanation (CoTE) for the DST task. CoTE, which is built on the generative DST framework, is designed to create detailed explanations step by step after determining the slot values. This process leads to more accurate and reliable slot values. More-over, to improve the reasoning ability of the CoTE, we further construct more fluent and high-quality explanations with automatic paraphrasing, leading the method CoTE-refined. Experimental results on three widely recognized DST benchmarks-MultiWOZ 2.2, WoZ 2.0, and M2M-demonstrate the remarkable effectiveness of the CoTE. Furthermore, through a meticulous fine-grained analysis, we observe significant benefits of our CoTE on samples characterized by longer dialogue turns, user responses, and reasoning steps.