 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSOR: One-Step Diffusion Inpainting for Effect-Aware Object Removal
Jun 26, 2026Real-world object removal is challenging due to two key difficulties: the target object's non-local effects, such as shadows and reflections, which are difficult to model, and the fact that user-provided masks are often inaccurate or incomplete. With billions of parameters and tens of denoising steps, diffusion-based models achieve strong removal performance at the expense of substantial computational cost, limiting their use in interactive applications and on edge devices. To address these challenges, we present OSOR (One-Step Object Removal), which simultaneously achieves efficient, effect-aware, and mask-robust object removal. Concretely, OSOR introduces: (1) an occupancy-guided discriminator for precise boundary supervision, enabling stable single-step diffusion training; (2) an alpha head that leverages knowledge from pretrained diffusion models to predict appropriate removal regions with minimal overhead, thereby handling imperfect masks; and (3) a semantic-anchored verification pipeline (SAVP) that filters noisy instruction-based triplets to produce effect-aware supervision at scale. Using SAVP, we curate CORNE, which contains 280K verified removal pairs, and further annotate AnimeEraseBench and TextEraseBench to evaluate performance on more complex removal tasks. Experiments show that OSOR surpasses strong multi-step diffusion baselines in perceptual quality while achieving $4\times$ to $30\times$ faster inference.
A Trajectory-Driven Spatio-Temporal Refinement Solution for CVPR 2026 8th UG2+ Challenge Track 3: DOST
Jun 04, 2026In this work, we present our solution for the 8th UG2+ Challenge (CVPR 2026) Track 3: Dynamic Object Segmentation in Turbulence (DOST). Our method is built upon the strong baseline framework Segment Any Motion (SegAnyMo), which provides powerful mask generation and motion tracking capabilities. To further boost the segmentation performance under severe atmospheric distortions, we propose two key improvements. First, we employ a data-centric domain adaptation strategy. We significantly expand our training data by incorporating selected sequences from the DAVIS dataset alongside a subset of the DOST dataset, and apply simulated atmospheric fluctuation degradations to enhance the model's robustness against complex geometric distortions. Second, we introduce a spatio-temporal post-processing module. This refinement step effectively removes persistent boundary-connected false foregrounds and short-lived fragmented noise, while strictly preserving genuine small targets and maintaining original individual labels across frames. With these combined strategies, our proposed method ranks the 2st place in the challenge.
An Effective Solution for the CVPR 2026 8th UG2+ Challenge Track 3: Dynamic Object Segmentation in Turbulence
May 30, 2026In this work, we present our solution for the 8th UG2+ Challenge (CVPR 2026) Track 3: Dynamic Object Segmentation in Turbulence (DOST). Our method is built upon the strong baseline framework Segment Any Motion (SegAnyMo), which provides powerful mask generation and motion tracking capabilities. To further boost the segmentation performance under severe atmospheric distortions, we propose two key improvements. First, we employ a data-centric domain adaptation strategy. We significantly expand our training data by incorporating selected sequences from the DAVIS dataset alongside a subset of the DOST dataset, and apply simulated atmospheric fluctuation degradations to enhance the model's robustness against complex geometric distortions. Second, we introduce a spatio-temporal post-processing module. This refinement step effectively removes persistent boundary-connected false foregrounds and short-lived fragmented noise, while strictly preserving genuine small targets and maintaining original individual labels across frames. With these combined strategies, our proposed method ranks the 2st place in the challenge.
X-Restormer++: 1st Place Solution for the UG2+ CVPR 2026 All-Weather Restoration Challenge
May 13, 2026In this work, we present our winning solution for the 8th UG2+ Challenge (CVPR 2026) Track 1: Image Restoration under All-weather Conditions. Our method is built upon the strong baseline framework X-Restormer, which effectively captures both channel-wise global dependencies and spatially-local structural information through its dual-attention design (Multi-DConv Head Transposed Attention and Overlapping Cross-Attention). To further boost the restoration performance, we propose several key improvements. First, we integrate the spatially-adaptive input scaling mechanism from Restormer-Plus to dynamically adjust the spatial weights of the input image, enhancing spatial adaptability. Second, to better preserve structural details and edge information, we introduce a novel Gradient-Guided Edge-Aware (GGEA) loss, which is combined with L1 and Multi-Scale SSIM losses in a unified training objective. Third, we significantly expand the training data by incorporating an extra 24,500 degraded-clean image pairs from FoundIR and WeatherBench alongside the original WeatherStream dataset. With these strategies, our proposed method successfully ranks the 1st place in the challenge.
Low Light Image Enhancement Challenge at NTIRE 2026
Apr 19, 2026This paper presents a comprehensive review of the NTIRE 2026 Low Light Image Enhancement Challenge, highlighting the proposed solutions and final results. The objective of this challenge is to identify effective networks capable of producing clearer and visually compelling images in diverse and challenging conditions by learning representative visual cues with the purpose of restoring information loss due to low-contrast and noisy images. A total of 195 participants registered for the first track and 153 for the second track of the competition, and 22 teams ultimately submitted valid entries. This paper thoroughly evaluates the state-of-the-art advances in (joint denoising and) low-light image enhancement, showcasing the significant progress in the field, while leveraging samples of our novel dataset.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
Enhancing Sa2VA for Referent Video Object Segmentation: 2nd Solution for 7th LSVOS RVOS Track
Sep 19, 2025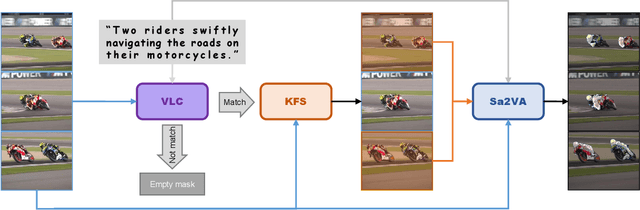
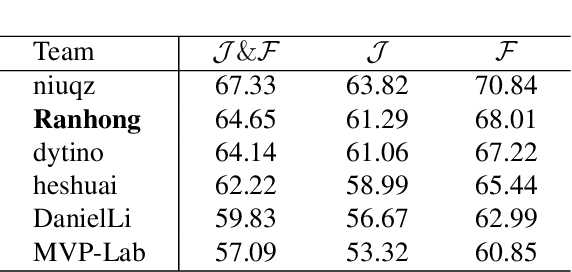

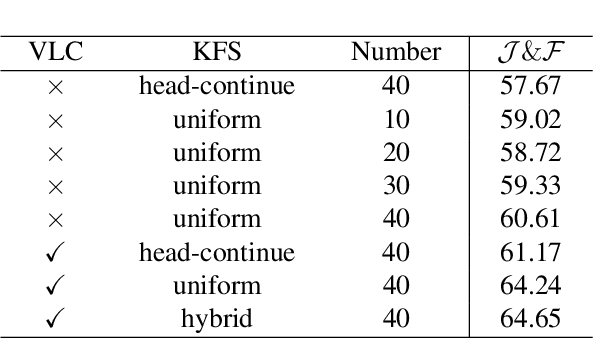
Referential Video Object Segmentation (RVOS) aims to segment all objects in a video that match a given natural language description, bridging the gap between vision and language understanding. Recent work, such as Sa2VA, combines Large Language Models (LLMs) with SAM~2, leveraging the strong video reasoning capability of LLMs to guide video segmentation. In this work, we present a training-free framework that substantially improves Sa2VA's performance on the RVOS task. Our method introduces two key components: (1) a Video-Language Checker that explicitly verifies whether the subject and action described in the query actually appear in the video, thereby reducing false positives; and (2) a Key-Frame Sampler that adaptively selects informative frames to better capture both early object appearances and long-range temporal context. Without any additional training, our approach achieves a J&F score of 64.14% on the MeViS test set, ranking 2nd place in the RVOS track of the 7th LSVOS Challenge at ICCV 2025.
Pseudo-Label Enhanced Cascaded Framework: 2nd Technical Report for LSVOS 2025 VOS Track
Sep 18, 2025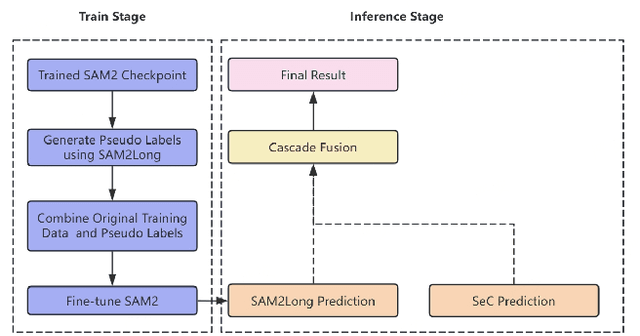



Complex Video Object Segmentation (VOS) presents significant challenges in accurately segmenting objects across frames, especially in the presence of small and similar targets, frequent occlusions, rapid motion, and complex interactions. In this report, we present our solution for the LSVOS 2025 VOS Track based on the SAM2 framework. We adopt a pseudo-labeling strategy during training: a trained SAM2 checkpoint is deployed within the SAM2Long framework to generate pseudo labels for the MOSE test set, which are then combined with existing data for further training. For inference, the SAM2Long framework is employed to obtain our primary segmentation results, while an open-source SeC model runs in parallel to produce complementary predictions. A cascaded decision mechanism dynamically integrates outputs from both models, exploiting the temporal stability of SAM2Long and the concept-level robustness of SeC. Benefiting from pseudo-label training and cascaded multi-model inference, our approach achieves a J\&F score of 0.8616 on the MOSE test set -- +1.4 points over our SAM2Long baseline -- securing the 2nd place in the LSVOS 2025 VOS Track, and demonstrating strong robustness and accuracy in long, complex video segmentation scenarios.
Inter- and intra-uncertainty based feature aggregation model for semi-supervised histopathology image segmentation
Mar 19, 2024Acquiring pixel-level annotations is often limited in applications such as histology studies that require domain expertise. Various semi-supervised learning approaches have been developed to work with limited ground truth annotations, such as the popular teacher-student models. However, hierarchical prediction uncertainty within the student model (intra-uncertainty) and image prediction uncertainty (inter-uncertainty) have not been fully utilized by existing methods. To address these issues, we first propose a novel inter- and intra-uncertainty regularization method to measure and constrain both inter- and intra-inconsistencies in the teacher-student architecture. We also propose a new two-stage network with pseudo-mask guided feature aggregation (PG-FANet) as the segmentation model. The two-stage structure complements with the uncertainty regularization strategy to avoid introducing extra modules in solving uncertainties and the aggregation mechanisms enable multi-scale and multi-stage feature integration. Comprehensive experimental results over the MoNuSeg and CRAG datasets show that our PG-FANet outperforms other state-of-the-art methods and our semi-supervised learning framework yields competitive performance with a limited amount of labeled data.
Prototype as Query for Few Shot Semantic Segmentation
Nov 27, 2022



Few-shot Semantic Segmentation (FSS) was proposed to segment unseen classes in a query image, referring to only a few annotated examples named support images. One of the characteristics of FSS is spatial inconsistency between query and support targets, e.g., texture or appearance. This greatly challenges the generalization ability of methods for FSS, which requires to effectively exploit the dependency of the query image and the support examples. Most existing methods abstracted support features into prototype vectors and implemented the interaction with query features using cosine similarity or feature concatenation. However, this simple interaction may not capture spatial details in query features. To alleviate this limitation, a few methods utilized all pixel-wise support information via computing the pixel-wise correlations between paired query and support features implemented with the attention mechanism of Transformer. These approaches suffer from heavy computation on the dot-product attention between all pixels of support and query features. In this paper, we propose a simple yet effective framework built upon Transformer termed as ProtoFormer to fully capture spatial details in query features. It views the abstracted prototype of the target class in support features as Query and the query features as Key and Value embeddings, which are input to the Transformer decoder. In this way, the spatial details can be better captured and the semantic features of target class in the query image can be focused. The output of the Transformer-based module can be viewed as semantic-aware dynamic kernels to filter out the segmentation mask from the enriched query features. Extensive experiments on PASCAL-$5^{i}$ and COCO-$20^{i}$ show that our ProtoFormer significantly advances the state-of-the-art methods.