 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrong Instance Segmentation Pipeline for MMSports Challenge
Sep 28, 2022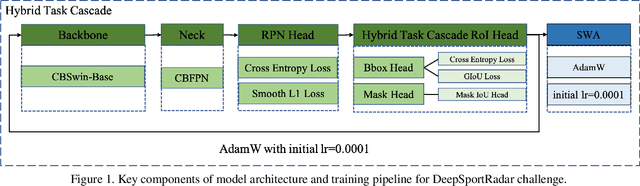

The goal of ACM MMSports2022 DeepSportRadar Instance Segmentation Challenge is to tackle the segmentation of individual humans including players, coaches and referees on a basketball court. And the main characteristics of this challenge are there is a high level of occlusions between players and the amount of data is quite limited. In order to address these problems, we designed a strong instance segmentation pipeline. Firstly, we employed a proper data augmentation strategy for this task mainly including photometric distortion transform and copy-paste strategy, which can generate more image instances with a wider distribution. Secondly, we employed a strong segmentation model, Hybrid Task Cascade based detector on the Swin-Base based CBNetV2 backbone, and we add MaskIoU head to HTCMaskHead that can simply and effectively improve the performance of instance segmentation. Finally, the SWA training strategy was applied to improve the performance further. Experimental results demonstrate the proposed pipeline can achieve a competitive result on the DeepSportRadar challenge, with 0.768AP@0.50:0.95 on the challenge set. Source code is available at https://github.com/YJingyu/Instanc_Segmentation_Pro.
Bilateral Network with Channel Splitting Network and Transformer for Thermal Image Super-Resolution
Jun 24, 2022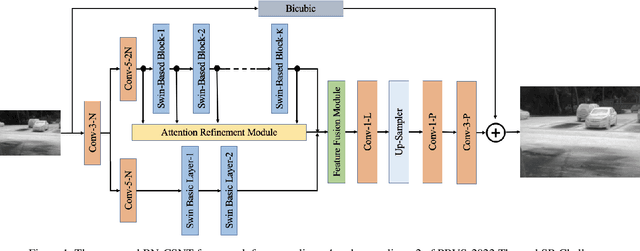
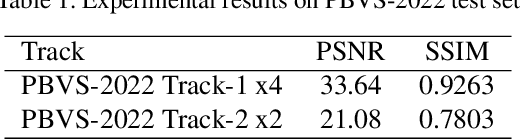
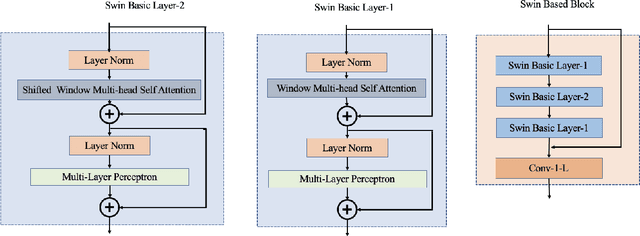
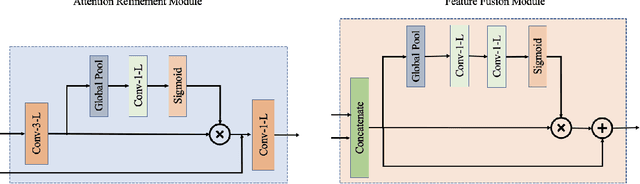
In recent years, the Thermal Image Super-Resolution (TISR) problem has become an attractive research topic. TISR would been used in a wide range of fields, including military, medical, agricultural and animal ecology. Due to the success of PBVS-2020 and PBVS-2021 workshop challenge, the result of TISR keeps improving and attracts more researchers to sign up for PBVS-2022 challenge. In this paper, we will introduce the technical details of our submission to PBVS-2022 challenge designing a Bilateral Network with Channel Splitting Network and Transformer(BN-CSNT) to tackle the TISR problem. Firstly, we designed a context branch based on channel splitting network with transformer to obtain sufficient context information. Secondly, we designed a spatial branch with shallow transformer to extract low level features which can preserve the spatial information. Finally, for the context branch in order to fuse the features from channel splitting network and transformer, we proposed an attention refinement module, and then features from context branch and spatial branch are fused by proposed feature fusion module. The proposed method can achieve PSNR=33.64, SSIM=0.9263 for x4 and PSNR=21.08, SSIM=0.7803 for x2 in the PBVS-2022 challenge test dataset.
The Second Place Solution for The 4th Large-scale Video Object Segmentation Challenge--Track 3: Referring Video Object Segmentation
Jun 24, 2022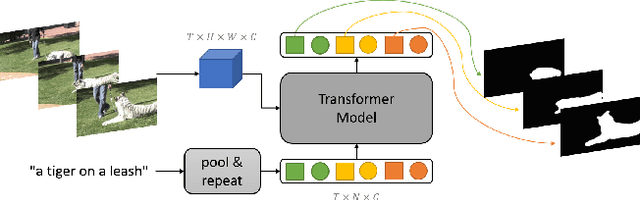
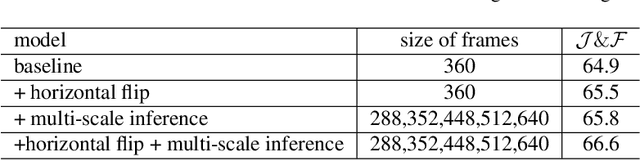
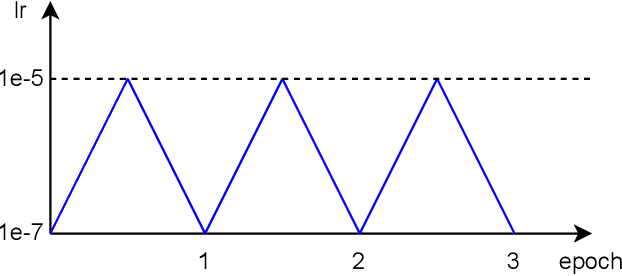
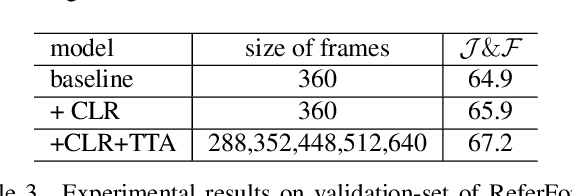
The referring video object segmentation task (RVOS) aims to segment object instances in a given video referred by a language expression in all video frames. Due to the requirement of understanding cross-modal semantics within individual instances, this task is more challenging than the traditional semi-supervised video object segmentation where the ground truth object masks in the first frame are given. With the great achievement of Transformer in object detection and object segmentation, RVOS has been made remarkable progress where ReferFormer achieved the state-of-the-art performance. In this work, based on the strong baseline framework--ReferFormer, we propose several tricks to boost further, including cyclical learning rates, semi-supervised approach, and test-time augmentation inference. The improved ReferFormer ranks 2nd place on CVPR2022 Referring Youtube-VOS Challenge.
The Second Place Solution for ICCV2021 VIPriors Instance Segmentation Challenge
Dec 02, 2021

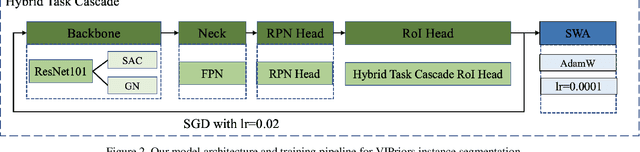
The Visual Inductive Priors(VIPriors) for Data-Efficient Computer Vision challenges ask competitors to train models from scratch in a data-deficient setting. In this paper, we introduce the technical details of our submission to the ICCV2021 VIPriors instance segmentation challenge. Firstly, we designed an effective data augmentation method to improve the problem of data-deficient. Secondly, we conducted some experiments to select a proper model and made some improvements for this task. Thirdly, we proposed an effective training strategy which can improve the performance. Experimental results demonstrate that our approach can achieve a competitive result on the test set. According to the competition rules, we do not use any external image or video data and pre-trained weights. The implementation details above are described in section 2 and section 3. Finally, our approach can achieve 40.2\%AP@0.50:0.95 on the test set of ICCV2021 VIPriors instance segmentation challenge.
Stronger Baseline for Person Re-Identification
Dec 02, 2021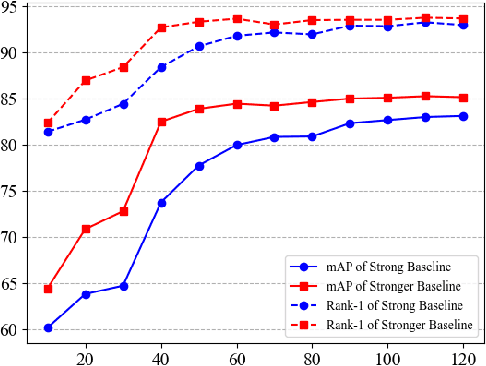

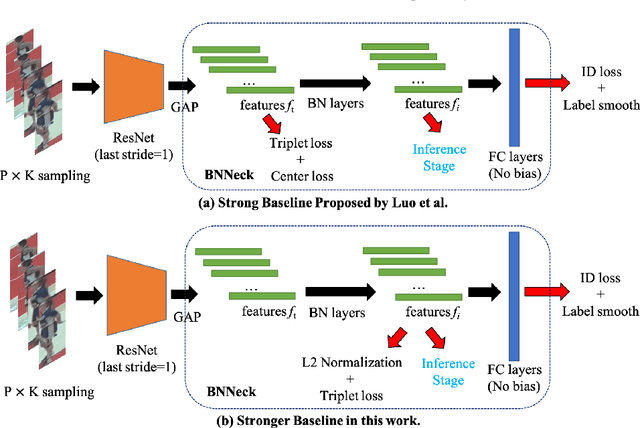
Person re-identification (re-ID) aims to identify the same person of interest across non-overlapping capturing cameras, which plays an important role in visual surveillance applications and computer vision research areas. Fitting a robust appearance-based representation extractor with limited collected training data is crucial for person re-ID due to the high expanse of annotating the identity of unlabeled data. In this work, we propose a Stronger Baseline for person re-ID, an enhancement version of the current prevailing method, namely, Strong Baseline, with tiny modifications but a faster convergence rate and higher recognition performance. With the aid of Stronger Baseline, we obtained the third place (i.e., 0.94 in mAP) in 2021 VIPriors Re-identification Challenge without the auxiliary of ImageNet-based pre-trained parameter initialization and any extra supplemental dataset.