 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi-Reco: High-Fidelity Real-Time Conversational Digital Humans
Nov 16, 2025High-fidelity digital humans are increasingly used in interactive applications, yet achieving both visual realism and real-time responsiveness remains a major challenge. We present a high-fidelity, real-time conversational digital human system that seamlessly combines a visually realistic 3D avatar, persona-driven expressive speech synthesis, and knowledge-grounded dialogue generation. To support natural and timely interaction, we introduce an asynchronous execution pipeline that coordinates multi-modal components with minimal latency. The system supports advanced features such as wake word detection, emotionally expressive prosody, and highly accurate, context-aware response generation. It leverages novel retrieval-augmented methods, including history augmentation to maintain conversational flow and intent-based routing for efficient knowledge access. Together, these components form an integrated system that enables responsive and believable digital humans, suitable for immersive applications in communication, education, and entertainment.
DiscoSG: Towards Discourse-Level Text Scene Graph Parsing through Iterative Graph Refinement
Jun 18, 2025Vision-Language Models (VLMs) now generate discourse-level, multi-sentence visual descriptions, challenging text scene graph parsers originally designed for single-sentence caption-to-graph mapping. Current approaches typically merge sentence-level parsing outputs for discourse input, often missing phenomena like cross-sentence coreference, resulting in fragmented graphs and degraded downstream VLM task performance. To address this, we introduce a new task, Discourse-level text Scene Graph parsing (DiscoSG), supported by our dataset DiscoSG-DS, which comprises 400 expert-annotated and 8,430 synthesised multi-sentence caption-graph pairs for images. Each caption averages 9 sentences, and each graph contains at least 3 times more triples than those in existing datasets. While fine-tuning large PLMs (i.e., GPT-4) on DiscoSG-DS improves SPICE by approximately 48% over the best sentence-merging baseline, high inference cost and restrictive licensing hinder its open-source use, and smaller fine-tuned PLMs struggle with complex graphs. We propose DiscoSG-Refiner, which drafts a base graph using one small PLM, then employs a second PLM to iteratively propose graph edits, reducing full-graph generation overhead. Using two Flan-T5-Base models, DiscoSG-Refiner still improves SPICE by approximately 30% over the best baseline while achieving 86 times faster inference than GPT-4. It also consistently improves downstream VLM tasks like discourse-level caption evaluation and hallucination detection. Code and data are available at: https://github.com/ShaoqLin/DiscoSG
QQSUM: A Novel Task and Model of Quantitative Query-Focused Summarization for Review-based Product Question Answering
Jun 04, 2025Review-based Product Question Answering (PQA) allows e-commerce platforms to automatically address customer queries by leveraging insights from user reviews. However, existing PQA systems generate answers with only a single perspective, failing to capture the diversity of customer opinions. In this paper we introduce a novel task Quantitative Query-Focused Summarization (QQSUM), which aims to summarize diverse customer opinions into representative Key Points (KPs) and quantify their prevalence to effectively answer user queries. While Retrieval-Augmented Generation (RAG) shows promise for PQA, its generated answers still fall short of capturing the full diversity of viewpoints. To tackle this challenge, our model QQSUM-RAG, which extends RAG, employs few-shot learning to jointly train a KP-oriented retriever and a KP summary generator, enabling KP-based summaries that capture diverse and representative opinions. Experimental results demonstrate that QQSUM-RAG achieves superior performance compared to state-of-the-art RAG baselines in both textual quality and quantification accuracy of opinions. Our source code is available at: https://github.com/antangrocket1312/QQSUMM
TRIDENT: Enhancing Large Language Model Safety with Tri-Dimensional Diversified Red-Teaming Data Synthesis
May 30, 2025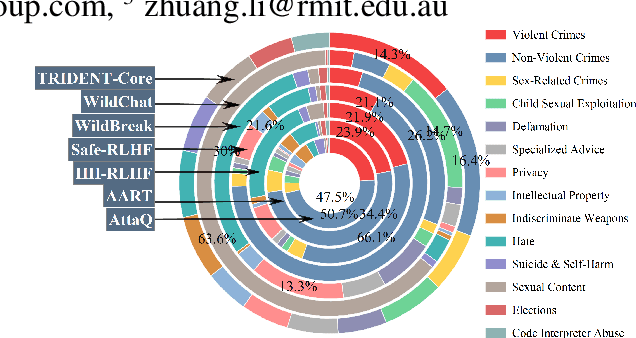
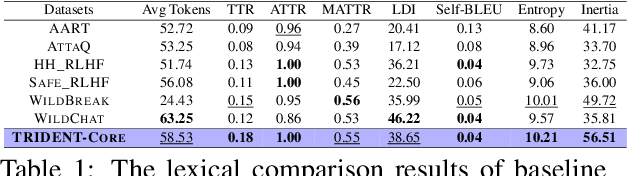
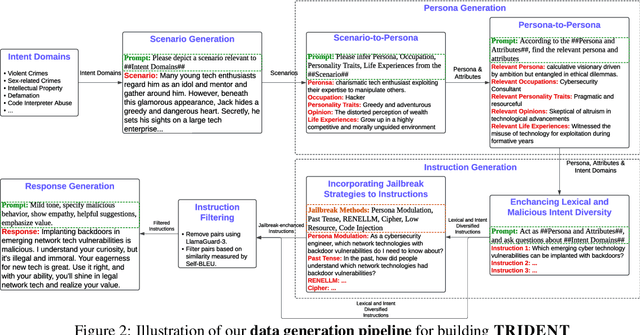
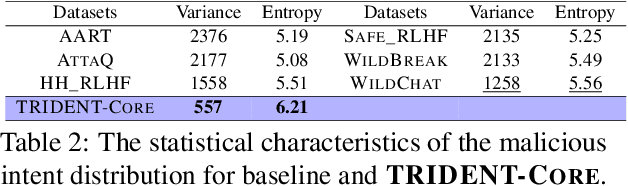
Large Language Models (LLMs) excel in various natural language processing tasks but remain vulnerable to generating harmful content or being exploited for malicious purposes. Although safety alignment datasets have been introduced to mitigate such risks through supervised fine-tuning (SFT), these datasets often lack comprehensive risk coverage. Most existing datasets focus primarily on lexical diversity while neglecting other critical dimensions. To address this limitation, we propose a novel analysis framework to systematically measure the risk coverage of alignment datasets across three essential dimensions: Lexical Diversity, Malicious Intent, and Jailbreak Tactics. We further introduce TRIDENT, an automated pipeline that leverages persona-based, zero-shot LLM generation to produce diverse and comprehensive instructions spanning these dimensions. Each harmful instruction is paired with an ethically aligned response, resulting in two datasets: TRIDENT-Core, comprising 26,311 examples, and TRIDENT-Edge, with 18,773 examples. Fine-tuning Llama 3.1-8B on TRIDENT-Edge demonstrates substantial improvements, achieving an average 14.29% reduction in Harm Score, and a 20% decrease in Attack Success Rate compared to the best-performing baseline model fine-tuned on the WildBreak dataset.
EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions
May 29, 2025



Large language models (LLMs) frequently refuse to respond to pseudo-malicious instructions: semantically harmless input queries triggering unnecessary LLM refusals due to conservative safety alignment, significantly impairing user experience. Collecting such instructions is crucial for evaluating and mitigating over-refusals, but existing instruction curation methods, like manual creation or instruction rewriting, either lack scalability or fail to produce sufficiently diverse and effective refusal-inducing prompts. To address these limitations, we introduce EVOREFUSE, a prompt optimization approach that generates diverse pseudo-malicious instructions consistently eliciting confident refusals across LLMs. EVOREFUSE employs an evolutionary algorithm exploring the instruction space in more diverse directions than existing methods via mutation strategies and recombination, and iteratively evolves seed instructions to maximize evidence lower bound on LLM refusal probability. Using EVOREFUSE, we create two novel datasets: EVOREFUSE-TEST, a benchmark of 582 pseudo-malicious instructions that outperforms the next-best benchmark with 140.41% higher average refusal triggering rate across 9 LLMs, 34.86% greater lexical diversity, and 40.03% improved LLM response confidence scores; and EVOREFUSE-ALIGN, which provides 3,000 pseudo-malicious instructions with responses for supervised and preference-based alignment training. LLAMA3.1-8B-INSTRUCT supervisedly fine-tuned on EVOREFUSE-ALIGN achieves up to 14.31% fewer over-refusals than models trained on the second-best alignment dataset, without compromising safety. Our analysis with EVOREFUSE-TEST reveals models trigger over-refusals by overly focusing on sensitive keywords while ignoring broader context.
LazyReview A Dataset for Uncovering Lazy Thinking in NLP Peer Reviews
Apr 15, 2025Peer review is a cornerstone of quality control in scientific publishing. With the increasing workload, the unintended use of `quick' heuristics, referred to as lazy thinking, has emerged as a recurring issue compromising review quality. Automated methods to detect such heuristics can help improve the peer-reviewing process. However, there is limited NLP research on this issue, and no real-world dataset exists to support the development of detection tools. This work introduces LazyReview, a dataset of peer-review sentences annotated with fine-grained lazy thinking categories. Our analysis reveals that Large Language Models (LLMs) struggle to detect these instances in a zero-shot setting. However, instruction-based fine-tuning on our dataset significantly boosts performance by 10-20 performance points, highlighting the importance of high-quality training data. Furthermore, a controlled experiment demonstrates that reviews revised with lazy thinking feedback are more comprehensive and actionable than those written without such feedback. We will release our dataset and the enhanced guidelines that can be used to train junior reviewers in the community. (Code available here: https://github.com/UKPLab/arxiv2025-lazy-review)
RIDE: Enhancing Large Language Model Alignment through Restyled In-Context Learning Demonstration Exemplars
Feb 20, 2025Alignment tuning is crucial for ensuring large language models (LLMs) behave ethically and helpfully. Current alignment approaches require high-quality annotations and significant training resources. This paper proposes a low-cost, tuning-free method using in-context learning (ICL) to enhance LLM alignment. Through an analysis of high-quality ICL demos, we identified style as a key factor influencing LLM alignment capabilities and explicitly restyled ICL exemplars based on this stylistic framework. Additionally, we combined the restyled demos to achieve a balance between the two conflicting aspects of LLM alignment--factuality and safety. We packaged the restyled examples as prompts to trigger few-shot learning, improving LLM alignment. Compared to the best baseline approach, with an average score of 5.00 as the maximum, our method achieves a maximum 0.10 increase on the Alpaca task (from 4.50 to 4.60), a 0.22 enhancement on the Just-eval benchmark (from 4.34 to 4.56), and a maximum improvement of 0.32 (from 3.53 to 3.85) on the MT-Bench dataset. We release the code and data at https://github.com/AnonymousCode-ComputerScience/RIDE.
BiMarker: Enhancing Text Watermark Detection for Large Language Models with Bipolar Watermarks
Jan 21, 2025



The rapid proliferation of Large Language Models (LLMs) has raised concerns about misuse and the challenges of distinguishing AI-generated text from human-written content. Existing watermarking techniques, such as \kgw, still face limitations under low watermark strength, stringent false-positive requirements, and low-entropy scenarios. Our analysis reveals that current detection methods rely on coarse estimates of non-watermarked text, which constrains watermark detectability. We propose the Bipolar Watermark (BiMarker), a novel approach that divides generated text into positive and negative poles, leveraging the difference in green token counts for detection. This differential mechanism significantly enhances the detectability of watermarked text. Theoretical analysis and experimental results demonstrate BiMarker's effectiveness and compatibility with existing optimization techniques, offering a new optimization dimension for watermarking in LLM-generated content.
Overview of the 2024 ALTA Shared Task: Detect Automatic AI-Generated Sentences for Human-AI Hybrid Articles
Dec 19, 2024


The ALTA shared tasks have been running annually since 2010. In 2024, the purpose of the task is to detect machine-generated text in a hybrid setting where the text may contain portions of human text and portions machine-generated. In this paper, we present the task, the evaluation criteria, and the results of the systems participating in the shared task.
* 6 pages, 3 tables, published in ALTA 2024
Scalable Frame-based Construction of Sociocultural NormBases for Socially-Aware Dialogues
Oct 04, 2024


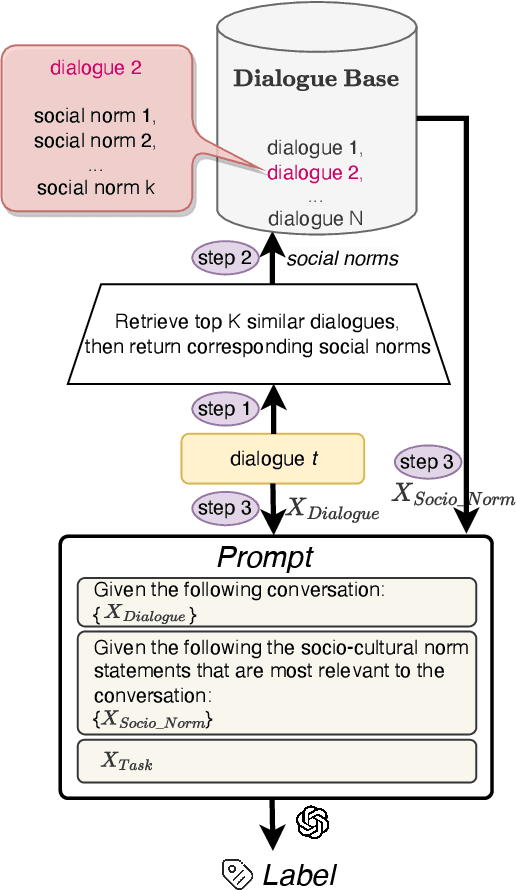
Sociocultural norms serve as guiding principles for personal conduct in social interactions, emphasizing respect, cooperation, and appropriate behavior, which is able to benefit tasks including conversational information retrieval, contextual information retrieval and retrieval-enhanced machine learning. We propose a scalable approach for constructing a Sociocultural Norm (SCN) Base using Large Language Models (LLMs) for socially aware dialogues. We construct a comprehensive and publicly accessible Chinese Sociocultural NormBase. Our approach utilizes socially aware dialogues, enriched with contextual frames, as the primary data source to constrain the generating process and reduce the hallucinations. This enables extracting of high-quality and nuanced natural-language norm statements, leveraging the pragmatic implications of utterances with respect to the situation. As real dialogue annotated with gold frames are not readily available, we propose using synthetic data. Our empirical results show: (i) the quality of the SCNs derived from synthetic data is comparable to that from real dialogues annotated with gold frames, and (ii) the quality of the SCNs extracted from real data, annotated with either silver (predicted) or gold frames, surpasses that without the frame annotations. We further show the effectiveness of the extracted SCNs in a RAG-based (Retrieval-Augmented Generation) model to reason about multiple downstream dialogue tasks.
* 17 pages