 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pre-training Corpora to Large Language Models: What Factors Influence LLM Performance in Causal Discovery Tasks?
Paper and Code
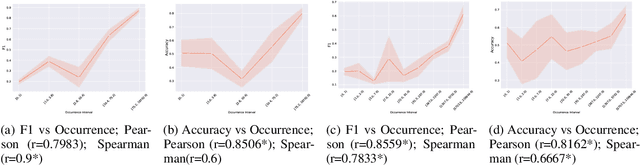
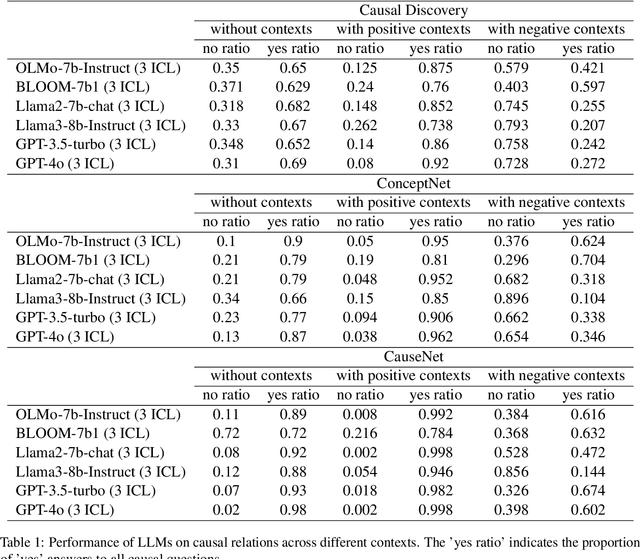
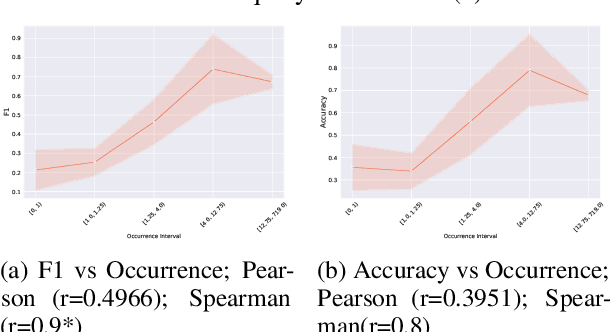
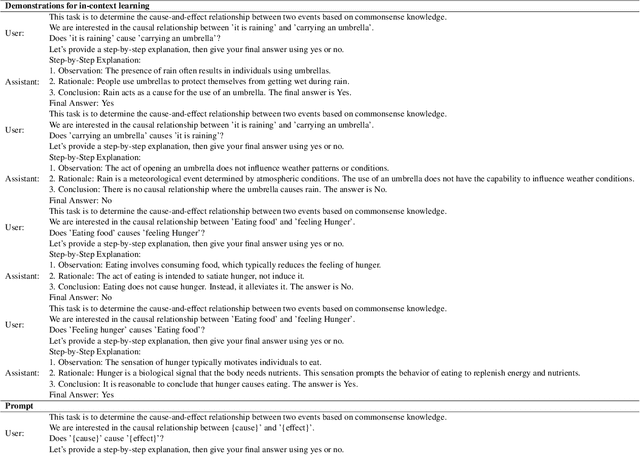
Recent advances in artificial intelligence have seen Large Language Models (LLMs) demonstrate notable proficiency in causal discovery tasks. This study explores the factors influencing the performance of LLMs in causal discovery tasks. Utilizing open-source LLMs, we examine how the frequency of causal relations within their pre-training corpora affects their ability to accurately respond to causal discovery queries. Our findings reveal that a higher frequency of causal mentions correlates with better model performance, suggesting that extensive exposure to causal information during training enhances the models' causal discovery capabilities. Additionally, we investigate the impact of context on the validity of causal relations. Our results indicate that LLMs might exhibit divergent predictions for identical causal relations when presented in different contexts. This paper provides the first comprehensive analysis of how different factors contribute to LLM performance in causal discovery tasks.