 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Can Better Capture Human Judgments--With the Right Prompts
Jun 10, 2026Are large language models (LLMs) bad at capturing human judgment? Two commonly stated limitations are that LLMs fail to capture full distributions of responses, and that their judgments are unstable across wording variations. We demonstrate simple prompting strategies that mitigate these limitations. Across two datasets--a U.S.-representative set of 144 moral scenarios and 38 moral beliefs from the International Social Survey Programme's Family and Changing Gender Roles module covering 32 countries--we show how simple elicitation techniques help improve AI-human alignment. First, prompting models to report standard deviations and response proportions recovers the full range of human responses better than common strategies. Second, ensuring scenarios are clear to human participants--as reflected in human confusion ratings--boosts model alignment, and LLMs can track human confusion ratings. At the same time, we find that LLMs' estimates of their own error are poorly calibrated, though they can predict human variability relatively well. These results suggest that asking better questions to LLMs can yield better answers.
DIVERGE: Diversity-Enhanced RAG for Open-Ended Information Seeking
Jan 30, 2026Existing retrieval-augmented generation (RAG) systems are primarily designed under the assumption that each query has a single correct answer. This overlooks common information-seeking scenarios with multiple plausible answers, where diversity is essential to avoid collapsing to a single dominant response, thereby constraining creativity and compromising fair and inclusive information access. Our analysis reveals a commonly overlooked limitation of standard RAG systems: they underutilize retrieved context diversity, such that increasing retrieval diversity alone does not yield diverse generations. To address this limitation, we propose DIVERGE, a plug-and-play agentic RAG framework with novel reflection-guided generation and memory-augmented iterative refinement, which promotes diverse viewpoints while preserving answer quality. We introduce novel metrics tailored to evaluating the diversity-quality trade-off in open-ended questions, and show that they correlate well with human judgments. We demonstrate that DIVERGE achieves the best diversity-quality trade-off compared to competitive baselines and previous state-of-the-art methods on the real-world Infinity-Chat dataset, substantially improving diversity while maintaining quality. More broadly, our results reveal a systematic limitation of current LLM-based systems for open-ended information-seeking and show that explicitly modeling diversity can mitigate it. Our code is available at: https://github.com/au-clan/Diverge
From Pre-training Corpora to Large Language Models: What Factors Influence LLM Performance in Causal Discovery Tasks?
Jul 29, 2024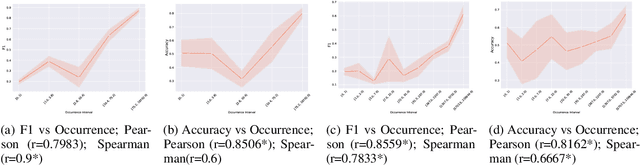
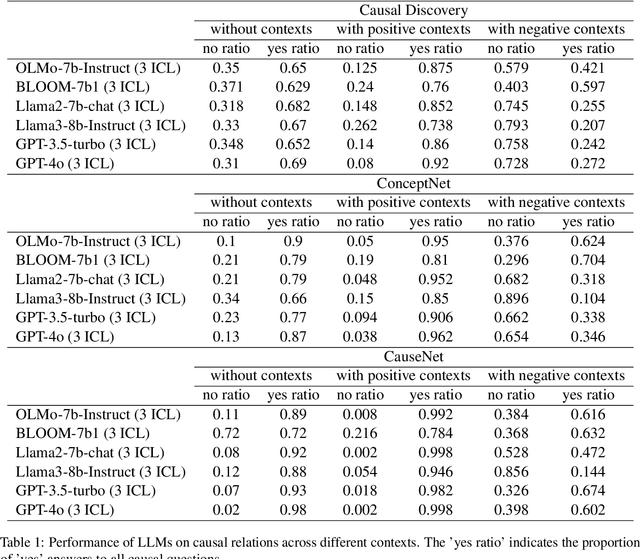
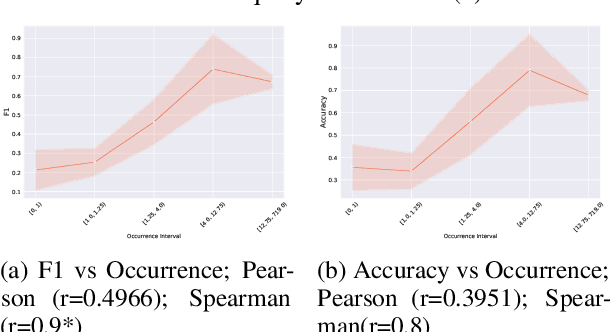
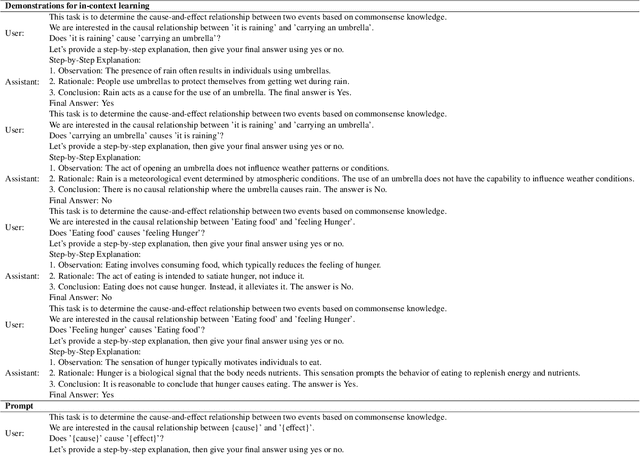
Recent advances in artificial intelligence have seen Large Language Models (LLMs) demonstrate notable proficiency in causal discovery tasks. This study explores the factors influencing the performance of LLMs in causal discovery tasks. Utilizing open-source LLMs, we examine how the frequency of causal relations within their pre-training corpora affects their ability to accurately respond to causal discovery queries. Our findings reveal that a higher frequency of causal mentions correlates with better model performance, suggesting that extensive exposure to causal information during training enhances the models' causal discovery capabilities. Additionally, we investigate the impact of context on the validity of causal relations. Our results indicate that LLMs might exhibit divergent predictions for identical causal relations when presented in different contexts. This paper provides the first comprehensive analysis of how different factors contribute to LLM performance in causal discovery tasks.
PDDLEGO: Iterative Planning in Textual Environments
May 30, 2024Planning in textual environments have been shown to be a long-standing challenge even for current models. A recent, promising line of work uses LLMs to generate a formal representation of the environment that can be solved by a symbolic planner. However, existing methods rely on a fully-observed environment where all entity states are initially known, so a one-off representation can be constructed, leading to a complete plan. In contrast, we tackle partially-observed environments where there is initially no sufficient information to plan for the end-goal. We propose PDDLEGO that iteratively construct a planning representation that can lead to a partial plan for a given sub-goal. By accomplishing the sub-goal, more information is acquired to augment the representation, eventually achieving the end-goal. We show that plans produced by few-shot PDDLEGO are 43% more efficient than generating plans end-to-end on the Coin Collector simulation, with strong performance (98%) on the more complex Cooking World simulation where end-to-end LLMs fail to generate coherent plans (4%).
WorldValuesBench: A Large-Scale Benchmark Dataset for Multi-Cultural Value Awareness of Language Models
Apr 25, 2024



The awareness of multi-cultural human values is critical to the ability of language models (LMs) to generate safe and personalized responses. However, this awareness of LMs has been insufficiently studied, since the computer science community lacks access to the large-scale real-world data about multi-cultural values. In this paper, we present WorldValuesBench, a globally diverse, large-scale benchmark dataset for the multi-cultural value prediction task, which requires a model to generate a rating response to a value question based on demographic contexts. Our dataset is derived from an influential social science project, World Values Survey (WVS), that has collected answers to hundreds of value questions (e.g., social, economic, ethical) from 94,728 participants worldwide. We have constructed more than 20 million examples of the type "(demographic attributes, value question) $\rightarrow$ answer" from the WVS responses. We perform a case study using our dataset and show that the task is challenging for strong open and closed-source models. On merely $11.1\%$, $25.0\%$, $72.2\%$, and $75.0\%$ of the questions, Alpaca-7B, Vicuna-7B-v1.5, Mixtral-8x7B-Instruct-v0.1, and GPT-3.5 Turbo can respectively achieve $<0.2$ Wasserstein 1-distance from the human normalized answer distributions. WorldValuesBench opens up new research avenues in studying limitations and opportunities in multi-cultural value awareness of LMs.
PROC2PDDL: Open-Domain Planning Representations from Texts
Feb 29, 2024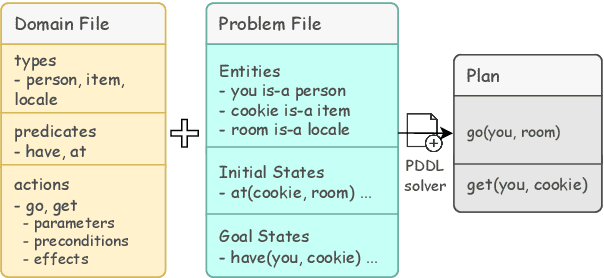
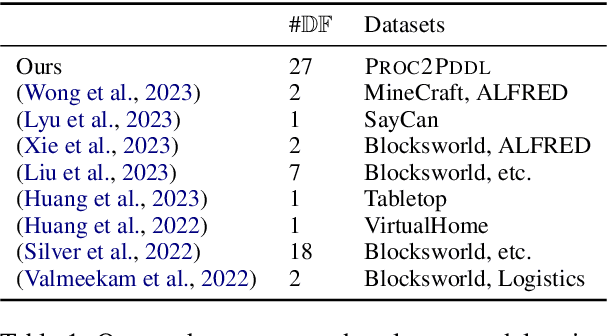

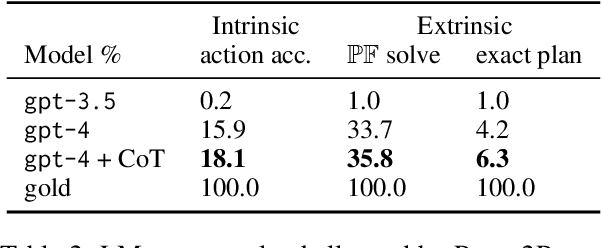
Planning in a text-based environment continues to be a major challenge for AI systems. Recent approaches have used language models to predict a planning domain definition (e.g., PDDL) but have only been evaluated in closed-domain simulated environments. To address this, we present Proc2PDDL , the first dataset containing open-domain procedural texts paired with expert-annotated PDDL representations. Using this dataset, we evaluate state-of-the-art models on defining the preconditions and effects of actions. We show that Proc2PDDL is highly challenging, with GPT-3.5's success rate close to 0% and GPT-4's around 35%. Our analysis shows both syntactic and semantic errors, indicating LMs' deficiency in both generating domain-specific prgorams and reasoning about events. We hope this analysis and dataset helps future progress towards integrating the best of LMs and formal planning.
Calibrating Large Language Models with Sample Consistency
Feb 21, 2024Accurately gauging the confidence level of Large Language Models' (LLMs) predictions is pivotal for their reliable application. However, LLMs are often uncalibrated inherently and elude conventional calibration techniques due to their proprietary nature and massive scale. In this work, we explore the potential of deriving confidence from the distribution of multiple randomly sampled model generations, via three measures of consistency. We perform an extensive evaluation across various open and closed-source models on nine reasoning datasets. Results show that consistency-based calibration methods outperform existing post-hoc approaches. Meanwhile, we find that factors such as intermediate explanations, model scaling, and larger sample sizes enhance calibration, while instruction-tuning makes calibration more difficult. Moreover, confidence scores obtained from consistency have the potential to enhance model performance. Finally, we offer practical guidance on choosing suitable consistency metrics for calibration, tailored to the characteristics of various LMs.
In-Context Principle Learning from Mistakes
Feb 09, 2024

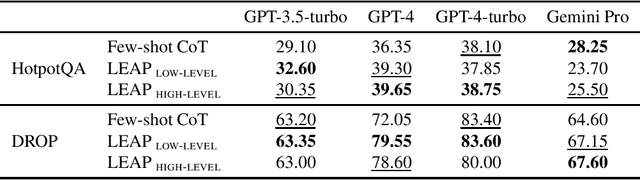

In-context learning (ICL, also known as few-shot prompting) has been the standard method of adapting LLMs to downstream tasks, by learning from a few input-output examples. Nonetheless, all ICL-based approaches only learn from correct input-output pairs. In this paper, we revisit this paradigm, by learning more from the few given input-output examples. We introduce Learning Principles (LEAP): First, we intentionally induce the model to make mistakes on these few examples; then we reflect on these mistakes, and learn explicit task-specific "principles" from them, which help solve similar problems and avoid common mistakes; finally, we prompt the model to answer unseen test questions using the original few-shot examples and these learned general principles. We evaluate LEAP on a wide range of benchmarks, including multi-hop question answering (Hotpot QA), textual QA (DROP), Big-Bench Hard reasoning, and math problems (GSM8K and MATH); in all these benchmarks, LEAP improves the strongest available LLMs such as GPT-3.5-turbo, GPT-4, GPT-4 turbo and Claude-2.1. For example, LEAP improves over the standard few-shot prompting using GPT-4 by 7.5% in DROP, and by 3.3% in HotpotQA. Importantly, LEAP does not require any more input or examples than the standard few-shot prompting settings.
One Size Does Not Fit All: Customizing Open-Domain Procedures
Nov 16, 2023How-to procedures, such as how to plant a garden, are ubiquitous. But one size does not fit all - humans often need to customize these procedural plans according to their specific needs, e.g., planting a garden without pesticides. While LLMs can fluently generate generic procedures, we present the first study on how well LLMs can customize open-domain procedures. We introduce CustomPlans, a probe dataset of customization hints that encodes diverse user needs for open-domain How-to procedures. Using LLMs as CustomizationAgent and ExecutionAgent in different settings, we establish their abilities to perform open-domain procedure customization. Human evaluation shows that using these agents in a Sequential setting is the best, but they are good enough only ~51% of the time. Error analysis shows that LLMs do not sufficiently address user customization needs in their generated procedures.
What Makes it Ok to Set a Fire? Iterative Self-distillation of Contexts and Rationales for Disambiguating Defeasible Social and Moral Situations
Nov 01, 2023Moral or ethical judgments rely heavily on the specific contexts in which they occur. Understanding varying shades of defeasible contextualizations (i.e., additional information that strengthens or attenuates the moral acceptability of an action) is critical to accurately represent the subtlety and intricacy of grounded human moral judgment in real-life scenarios. We introduce defeasible moral reasoning: a task to provide grounded contexts that make an action more or less morally acceptable, along with commonsense rationales that justify the reasoning. To elicit high-quality task data, we take an iterative self-distillation approach that starts from a small amount of unstructured seed knowledge from GPT-3 and then alternates between (1) self-distillation from student models; (2) targeted filtering with a critic model trained by human judgment (to boost validity) and NLI (to boost diversity); (3) self-imitation learning (to amplify the desired data quality). This process yields a student model that produces defeasible contexts with improved validity, diversity, and defeasibility. From this model we distill a high-quality dataset, \delta-Rules-of-Thumb, of 1.2M entries of contextualizations and rationales for 115K defeasible moral actions rated highly by human annotators 85.9% to 99.8% of the time. Using \delta-RoT we obtain a final student model that wins over all intermediate student models by a notable margin.