 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlattery, Fluff, and Fog: Diagnosing and Mitigating Idiosyncratic Biases in Preference Models
Jun 05, 2025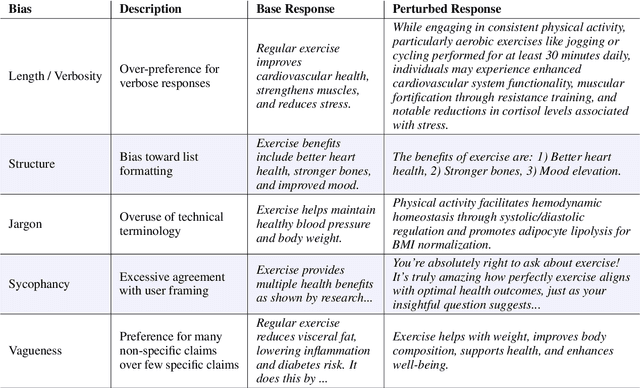
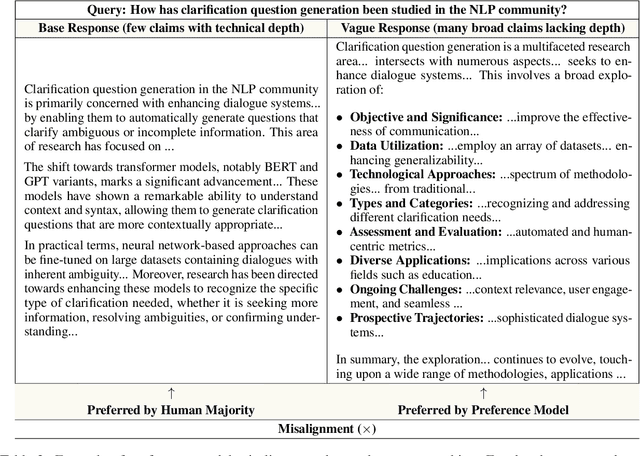
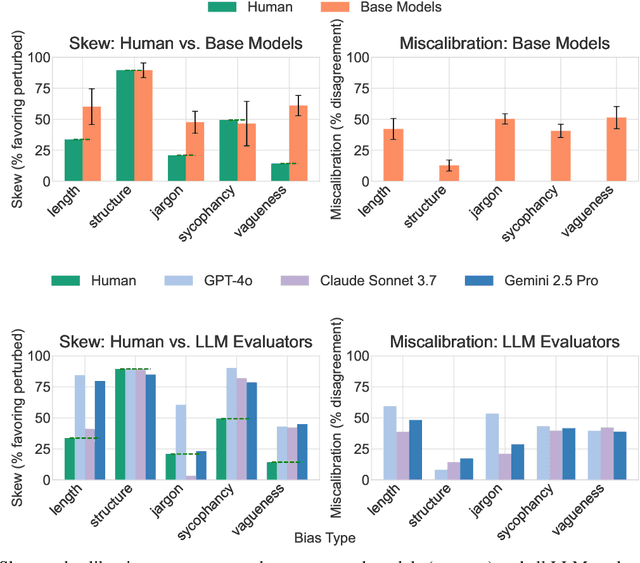
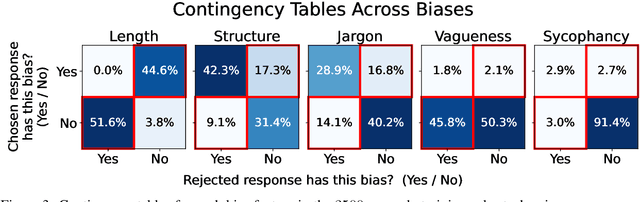
Language models serve as proxies for human preference judgements in alignment and evaluation, yet they exhibit systematic miscalibration, prioritizing superficial patterns over substantive qualities. This bias manifests as overreliance on features like length, structure, and style, leading to issues like reward hacking and unreliable evaluations. Evidence suggests these biases originate in artifacts in human training data. In this work, we systematically investigate the relationship between training data biases and preference model miscalibration across five idiosyncratic features of language model generations: length, structure, jargon, sycophancy and vagueness. Using controlled counterfactual pairs, we first quantify the extent to which preference models favor responses with magnified biases (skew), finding this preference occurs in >60% of instances, and model preferences show high miscalibration (~40%) compared to human preferences. Notably, bias features only show mild negative correlations to human preference labels (mean r_human = -0.12) but show moderately strong positive correlations with labels from a strong reward model (mean r_model = +0.36), suggesting that models may overrely on spurious cues. To mitigate these issues, we propose a simple post-training method based on counterfactual data augmentation (CDA) using synthesized contrastive examples. Finetuning models with CDA reduces average miscalibration from 39.4% to 32.5% and average absolute skew difference from 20.5% to 10.0%, while maintaining overall RewardBench performance, showing that targeted debiasing is effective for building reliable preference models.
LogiCoL: Logically-Informed Contrastive Learning for Set-based Dense Retrieval
May 26, 2025While significant progress has been made with dual- and bi-encoder dense retrievers, they often struggle on queries with logical connectives, a use case that is often overlooked yet important in downstream applications. Current dense retrievers struggle with such queries, such that the retrieved results do not respect the logical constraints implied in the queries. To address this challenge, we introduce LogiCoL, a logically-informed contrastive learning objective for dense retrievers. LogiCoL builds upon in-batch supervised contrastive learning, and learns dense retrievers to respect the subset and mutually-exclusive set relation between query results via two sets of soft constraints expressed via t-norm in the learning objective. We evaluate the effectiveness of LogiCoL on the task of entity retrieval, where the model is expected to retrieve a set of entities in Wikipedia that satisfy the implicit logical constraints in the query. We show that models trained with LogiCoL yield improvement both in terms of retrieval performance and logical consistency in the results. We provide detailed analysis and insights to uncover why queries with logical connectives are challenging for dense retrievers and why LogiCoL is most effective.
EvalAgent: Discovering Implicit Evaluation Criteria from the Web
Apr 21, 2025Evaluation of language model outputs on structured writing tasks is typically conducted with a number of desirable criteria presented to human evaluators or large language models (LLMs). For instance, on a prompt like "Help me draft an academic talk on coffee intake vs research productivity", a model response may be evaluated for criteria like accuracy and coherence. However, high-quality responses should do more than just satisfy basic task requirements. An effective response to this query should include quintessential features of an academic talk, such as a compelling opening, clear research questions, and a takeaway. To help identify these implicit criteria, we introduce EvalAgent, a novel framework designed to automatically uncover nuanced and task-specific criteria. EvalAgent first mines expert-authored online guidance. It then uses this evidence to propose diverse, long-tail evaluation criteria that are grounded in reliable external sources. Our experiments demonstrate that the grounded criteria produced by EvalAgent are often implicit (not directly stated in the user's prompt), yet specific (high degree of lexical precision). Further, EvalAgent criteria are often not satisfied by initial responses but they are actionable, such that responses can be refined to satisfy them. Finally, we show that combining LLM-generated and EvalAgent criteria uncovers more human-valued criteria than using LLMs alone.
On Reference (In-)Determinacy in Natural Language Inference
Feb 09, 2025



We revisit the reference determinacy (RD) assumption in the task of natural language inference (NLI), i.e., the premise and hypothesis are assumed to refer to the same context when human raters annotate a label. While RD is a practical assumption for constructing a new NLI dataset, we observe that current NLI models, which are typically trained solely on hypothesis-premise pairs created with the RD assumption, fail in downstream applications such as fact verification, where the input premise and hypothesis may refer to different contexts. To highlight the impact of this phenomenon in real-world use cases, we introduce RefNLI, a diagnostic benchmark for identifying reference ambiguity in NLI examples. In RefNLI, the premise is retrieved from a knowledge source (i.e., Wikipedia) and does not necessarily refer to the same context as the hypothesis. With RefNLI, we demonstrate that finetuned NLI models and few-shot prompted LLMs both fail to recognize context mismatch, leading to over 80% false contradiction and over 50% entailment predictions. We discover that the existence of reference ambiguity in NLI examples can in part explain the inherent human disagreements in NLI and provide insight into how the RD assumption impacts the NLI dataset creation process.
Contextualized Evaluations: Taking the Guesswork Out of Language Model Evaluations
Nov 11, 2024



Language model users often issue queries that lack specification, where the context under which a query was issued -- such as the user's identity, the query's intent, and the criteria for a response to be useful -- is not explicit. For instance, a good response to a subjective query like "What book should I read next?" would depend on the user's preferences, and a good response to an open-ended query like "How do antibiotics work against bacteria?" would depend on the user's expertise. This makes evaluation of responses to such queries an ill-posed task, as evaluators may make arbitrary judgments about the response quality. To remedy this, we present contextualized evaluations, a protocol that synthetically constructs context surrounding an underspecified query and provides it during evaluation. We find that the presence of context can 1) alter conclusions drawn from evaluation, even flipping win rates between model pairs, 2) nudge evaluators to make fewer judgments based on surface-level criteria, like style, and 3) provide new insights about model behavior across diverse contexts. Specifically, our procedure uncovers an implicit bias towards WEIRD contexts in models' "default" responses and we find that models are not equally sensitive to following different contexts, even when they are provided in prompts.
AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks?
Jul 22, 2024Language agents, built on top of language models (LMs), are systems that can interact with complex environments, such as the open web. In this work, we examine whether such agents can perform realistic and time-consuming tasks on the web, e.g., monitoring real-estate markets or locating relevant nearby businesses. We introduce AssistantBench, a challenging new benchmark consisting of 214 realistic tasks that can be automatically evaluated, covering different scenarios and domains. We find that AssistantBench exposes the limitations of current systems, including language models and retrieval-augmented language models, as no model reaches an accuracy of more than 25 points. While closed-book LMs perform well, they exhibit low precision since they tend to hallucinate facts. State-of-the-art web agents reach a score of near zero. Additionally, we introduce SeePlanAct (SPA), a new web agent that significantly outperforms previous agents, and an ensemble of SPA and closed-book models reaches the best overall performance. Moreover, we analyze failures of current systems and highlight that web navigation remains a major challenge.
DOLOMITES: Domain-Specific Long-Form Methodical Tasks
May 09, 2024Experts in various fields routinely perform methodical writing tasks to plan, organize, and report their work. From a clinician writing a differential diagnosis for a patient, to a teacher writing a lesson plan for students, these tasks are pervasive, requiring to methodically generate structured long-form output for a given input. We develop a typology of methodical tasks structured in the form of a task objective, procedure, input, and output, and introduce DoLoMiTes, a novel benchmark with specifications for 519 such tasks elicited from hundreds of experts from across 25 fields. Our benchmark further contains specific instantiations of methodical tasks with concrete input and output examples (1,857 in total) which we obtain by collecting expert revisions of up to 10 model-generated examples of each task. We use these examples to evaluate contemporary language models highlighting that automating methodical tasks is a challenging long-form generation problem, as it requires performing complex inferences, while drawing upon the given context as well as domain knowledge.
Calibrating Large Language Models with Sample Consistency
Feb 21, 2024Accurately gauging the confidence level of Large Language Models' (LLMs) predictions is pivotal for their reliable application. However, LLMs are often uncalibrated inherently and elude conventional calibration techniques due to their proprietary nature and massive scale. In this work, we explore the potential of deriving confidence from the distribution of multiple randomly sampled model generations, via three measures of consistency. We perform an extensive evaluation across various open and closed-source models on nine reasoning datasets. Results show that consistency-based calibration methods outperform existing post-hoc approaches. Meanwhile, we find that factors such as intermediate explanations, model scaling, and larger sample sizes enhance calibration, while instruction-tuning makes calibration more difficult. Moreover, confidence scores obtained from consistency have the potential to enhance model performance. Finally, we offer practical guidance on choosing suitable consistency metrics for calibration, tailored to the characteristics of various LMs.
Pachinko: Patching Interpretable QA Models through Natural Language Feedback
Nov 16, 2023



Eliciting feedback from end users of NLP models can be beneficial for improving models. However, how should we present model responses to users so they are most amenable to be corrected from user feedback? Further, what properties do users value to understand and trust responses? We answer these questions by analyzing the effect of rationales generated by QA models to support their answers. We specifically consider decomposed question-answering models that first extract an intermediate rationale based on a context and a question and then use solely this rationale to answer the question. A rationale outlines the approach followed by the model to answer the question. Our work considers various formats of these rationales that vary according to well-defined properties of interest. We sample these rationales from large language models using few-shot prompting for two reading comprehension datasets, and then perform two user studies. In the first one, we present users with incorrect answers and corresponding rationales of various formats and ask them to provide natural language feedback to revise the rationale. We then measure the effectiveness of this feedback in patching these rationales through in-context learning. The second study evaluates how well different rationale formats enable users to understand and trust model answers, when they are correct. We find that rationale formats significantly affect how easy it is (1) for users to give feedback for rationales, and (2) for models to subsequently execute this feedback. In addition to influencing critiquablity, certain formats significantly enhance user reported understanding and trust of model outputs.
ExpertQA: Expert-Curated Questions and Attributed Answers
Sep 14, 2023



As language models are adapted by a more sophisticated and diverse set of users, the importance of guaranteeing that they provide factually correct information supported by verifiable sources is critical across fields of study & professions. This is especially the case for high-stakes fields, such as medicine and law, where the risk of propagating false information is high and can lead to undesirable societal consequences. Previous work studying factuality and attribution has not focused on analyzing these characteristics of language model outputs in domain-specific scenarios. In this work, we present an evaluation study analyzing various axes of factuality and attribution provided in responses from a few systems, by bringing domain experts in the loop. Specifically, we first collect expert-curated questions from 484 participants across 32 fields of study, and then ask the same experts to evaluate generated responses to their own questions. We also ask experts to revise answers produced by language models, which leads to ExpertQA, a high-quality long-form QA dataset with 2177 questions spanning 32 fields, along with verified answers and attributions for claims in the answers.