 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOLOMITES: Domain-Specific Long-Form Methodical Tasks
May 09, 2024Experts in various fields routinely perform methodical writing tasks to plan, organize, and report their work. From a clinician writing a differential diagnosis for a patient, to a teacher writing a lesson plan for students, these tasks are pervasive, requiring to methodically generate structured long-form output for a given input. We develop a typology of methodical tasks structured in the form of a task objective, procedure, input, and output, and introduce DoLoMiTes, a novel benchmark with specifications for 519 such tasks elicited from hundreds of experts from across 25 fields. Our benchmark further contains specific instantiations of methodical tasks with concrete input and output examples (1,857 in total) which we obtain by collecting expert revisions of up to 10 model-generated examples of each task. We use these examples to evaluate contemporary language models highlighting that automating methodical tasks is a challenging long-form generation problem, as it requires performing complex inferences, while drawing upon the given context as well as domain knowledge.
Text-Blueprint: An Interactive Platform for Plan-based Conditional Generation
Apr 28, 2023While conditional generation models can now generate natural language well enough to create fluent text, it is still difficult to control the generation process, leading to irrelevant, repetitive, and hallucinated content. Recent work shows that planning can be a useful intermediate step to render conditional generation less opaque and more grounded. We present a web browser-based demonstration for query-focused summarization that uses a sequence of question-answer pairs, as a blueprint plan for guiding text generation (i.e., what to say and in what order). We illustrate how users may interact with the generated text and associated plan visualizations, e.g., by editing and modifying the blueprint in order to improve or control the generated output. A short video demonstrating our system is available at https://goo.gle/text-blueprint-demo.
Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022



Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
Towards Computationally Verifiable Semantic Grounding for Language Models
Nov 16, 2022



The paper presents an approach to semantic grounding of language models (LMs) that conceptualizes the LM as a conditional model generating text given a desired semantic message formalized as a set of entity-relationship triples. It embeds the LM in an auto-encoder by feeding its output to a semantic parser whose output is in the same representation domain as the input message. Compared to a baseline that generates text using greedy search, we demonstrate two techniques that improve the fluency and semantic accuracy of the generated text: The first technique samples multiple candidate text sequences from which the semantic parser chooses. The second trains the language model while keeping the semantic parser frozen to improve the semantic accuracy of the auto-encoder. We carry out experiments on the English WebNLG 3.0 data set, using BLEU to measure the fluency of generated text and standard parsing metrics to measure semantic accuracy. We show that our proposed approaches significantly improve on the greedy search baseline. Human evaluation corroborates the results of the automatic evaluation experiments.
QAmeleon: Multilingual QA with Only 5 Examples
Nov 15, 2022The availability of large, high-quality datasets has been one of the main drivers of recent progress in question answering (QA). Such annotated datasets however are difficult and costly to collect, and rarely exist in languages other than English, rendering QA technology inaccessible to underrepresented languages. An alternative to building large monolingual training datasets is to leverage pre-trained language models (PLMs) under a few-shot learning setting. Our approach, QAmeleon, uses a PLM to automatically generate multilingual data upon which QA models are trained, thus avoiding costly annotation. Prompt tuning the PLM for data synthesis with only five examples per language delivers accuracy superior to translation-based baselines, bridges nearly 60% of the gap between an English-only baseline and a fully supervised upper bound trained on almost 50,000 hand labeled examples, and always leads to substantial improvements compared to fine-tuning a QA model directly on labeled examples in low resource settings. Experiments on the TyDiQA-GoldP and MLQA benchmarks show that few-shot prompt tuning for data synthesis scales across languages and is a viable alternative to large-scale annotation.
Conditional Generation with a Question-Answering Blueprint
Jul 01, 2022
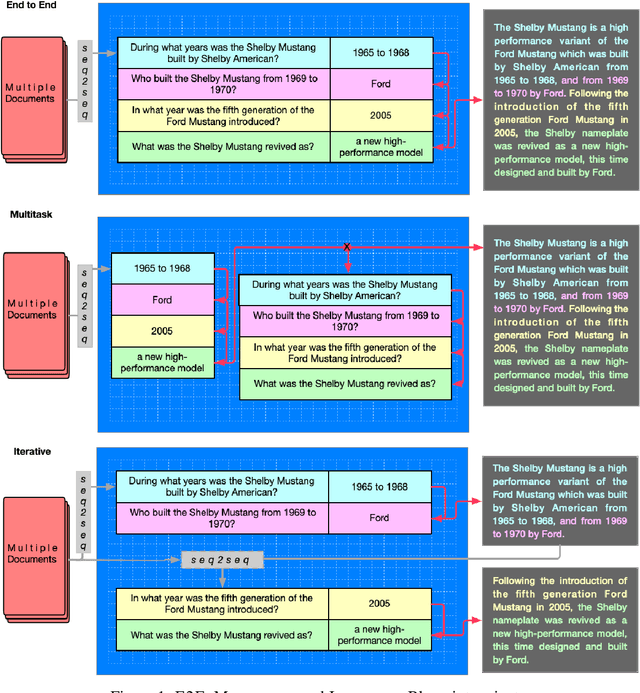
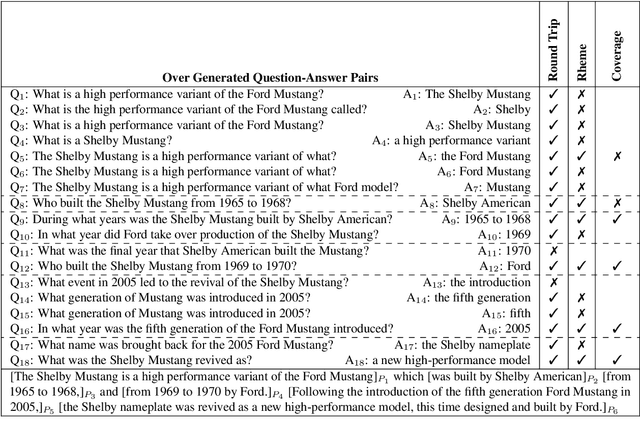
The ability to convey relevant and faithful information is critical for many tasks in conditional generation and yet remains elusive for neural seq-to-seq models whose outputs often reveal hallucinations and fail to correctly cover important details. In this work, we advocate planning as a useful intermediate representation for rendering conditional generation less opaque and more grounded. Our work proposes a new conceptualization of text plans as a sequence of question-answer (QA) pairs. We enhance existing datasets (e.g., for summarization) with a QA blueprint operating as a proxy for both content selection (i.e.,~what to say) and planning (i.e.,~in what order). We obtain blueprints automatically by exploiting state-of-the-art question generation technology and convert input-output pairs into input-blueprint-output tuples. We develop Transformer-based models, each varying in how they incorporate the blueprint in the generated output (e.g., as a global plan or iteratively). Evaluation across metrics and datasets demonstrates that blueprint models are more factual than alternatives which do not resort to planning and allow tighter control of the generation output.
Feature-Rich Named Entity Recognition for Bulgarian Using Conditional Random Fields
Sep 26, 2021

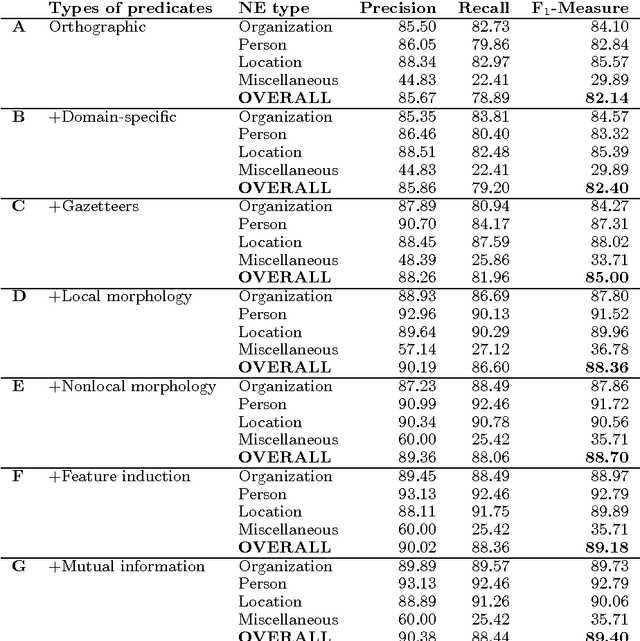
The paper presents a feature-rich approach to the automatic recognition and categorization of named entities (persons, organizations, locations, and miscellaneous) in news text for Bulgarian. We combine well-established features used for other languages with language-specific lexical, syntactic and morphological information. In particular, we make use of the rich tagset annotation of the BulTreeBank (680 morpho-syntactic tags), from which we derive suitable task-specific tagsets (local and nonlocal). We further add domain-specific gazetteers and additional unlabeled data, achieving F1=89.4%, which is comparable to the state-of-the-art results for English.
* named entity recognition, NER, conditional random fields, CRF, Bulgarian, BulTreeBank
State-of-the-art Chinese Word Segmentation with Bi-LSTMs
Aug 24, 2018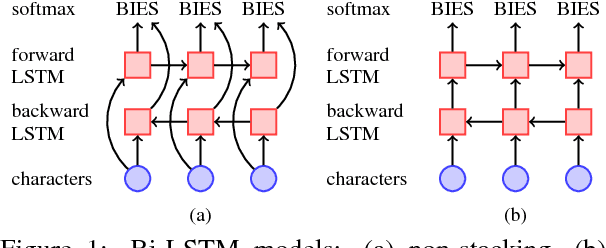

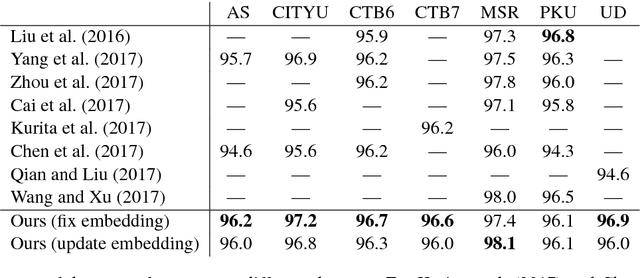

A wide variety of neural-network architectures have been proposed for the task of Chinese word segmentation. Surprisingly, we find that a bidirectional LSTM model, when combined with standard deep learning techniques and best practices, can achieve better accuracy on many of the popular datasets as compared to models based on more complex neural-network architectures. Furthermore, our error analysis shows that out-of-vocabulary words remain challenging for neural-network models, and many of the remaining errors are unlikely to be fixed through architecture changes. Instead, more effort should be made on exploring resources for further improvement.
Context-Dependent Fine-Grained Entity Type Tagging
Aug 01, 2016



Entity type tagging is the task of assigning category labels to each mention of an entity in a document. While standard systems focus on a small set of types, recent work (Ling and Weld, 2012) suggests that using a large fine-grained label set can lead to dramatic improvements in downstream tasks. In the absence of labeled training data, existing fine-grained tagging systems obtain examples automatically, using resolved entities and their types extracted from a knowledge base. However, since the appropriate type often depends on context (e.g. Washington could be tagged either as city or government), this procedure can result in spurious labels, leading to poorer generalization. We propose the task of context-dependent fine type tagging, where the set of acceptable labels for a mention is restricted to only those deducible from the local context (e.g. sentence or document). We introduce new resources for this task: 12,017 mentions annotated with their context-dependent fine types, and we provide baseline experimental results on this data.
Globally Normalized Transition-Based Neural Networks
Jun 08, 2016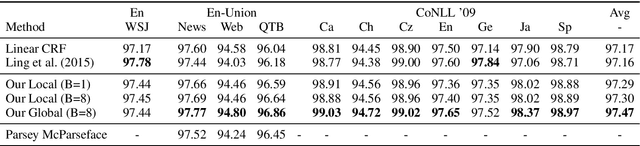
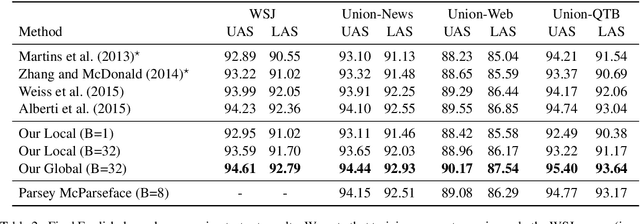
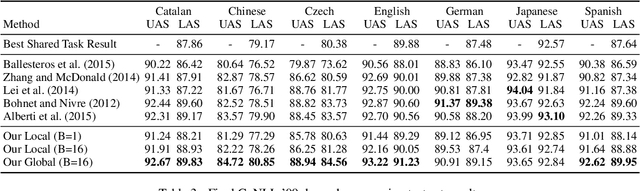
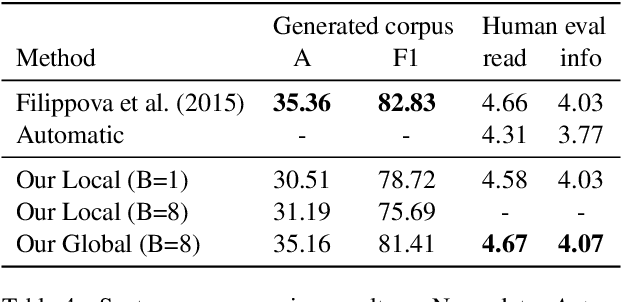
We introduce a globally normalized transition-based neural network model that achieves state-of-the-art part-of-speech tagging, dependency parsing and sentence compression results. Our model is a simple feed-forward neural network that operates on a task-specific transition system, yet achieves comparable or better accuracies than recurrent models. We discuss the importance of global as opposed to local normalization: a key insight is that the label bias problem implies that globally normalized models can be strictly more expressive than locally normalized models.