 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQA Is the New KR: Question-Answer Pairs as Knowledge Bases
Jul 01, 2022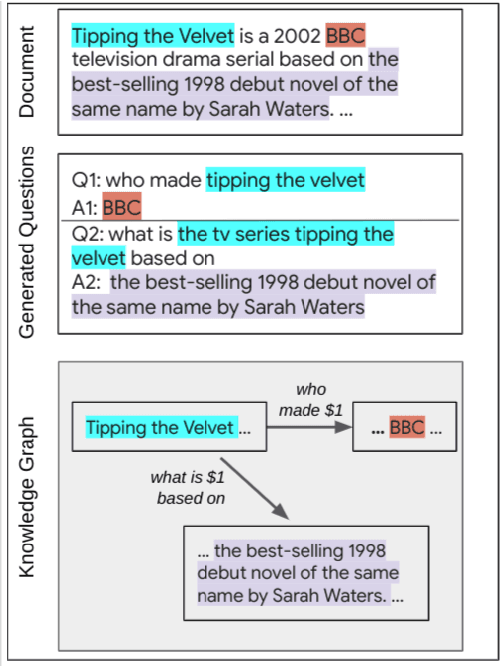
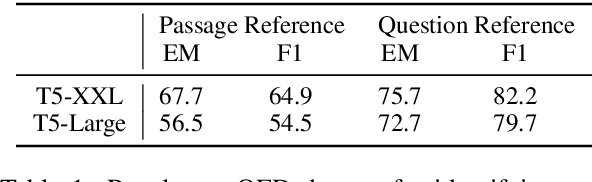
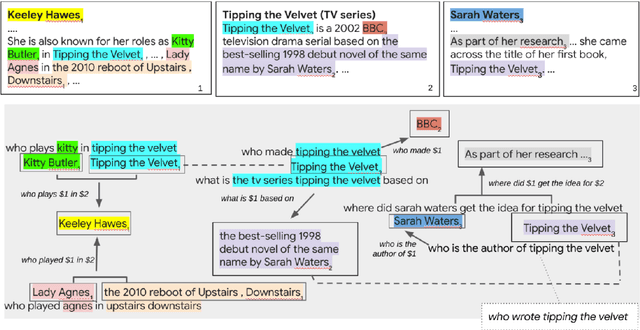
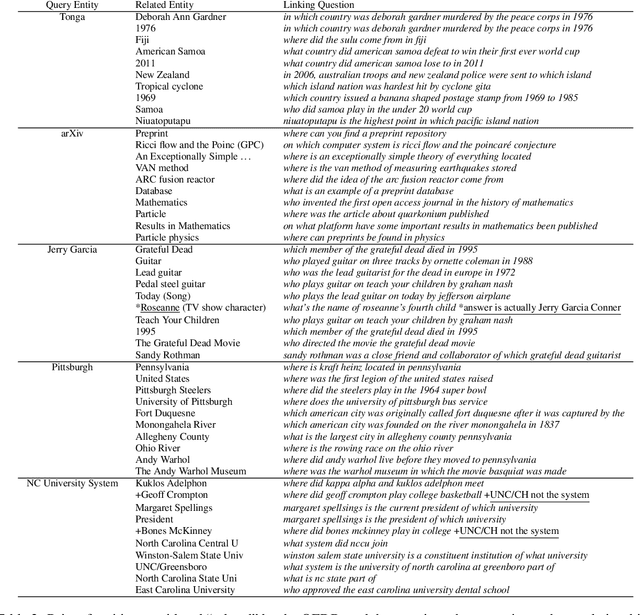
In this position paper, we propose a new approach to generating a type of knowledge base (KB) from text, based on question generation and entity linking. We argue that the proposed type of KB has many of the key advantages of a traditional symbolic KB: in particular, it consists of small modular components, which can be combined compositionally to answer complex queries, including relational queries and queries involving "multi-hop" inferences. However, unlike a traditional KB, this information store is well-aligned with common user information needs.
Learning Dense Representations for Entity Retrieval
Sep 23, 2019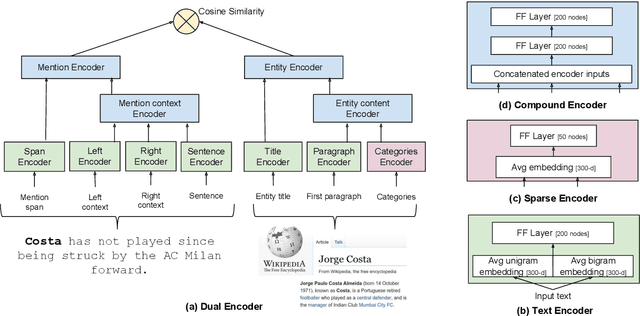
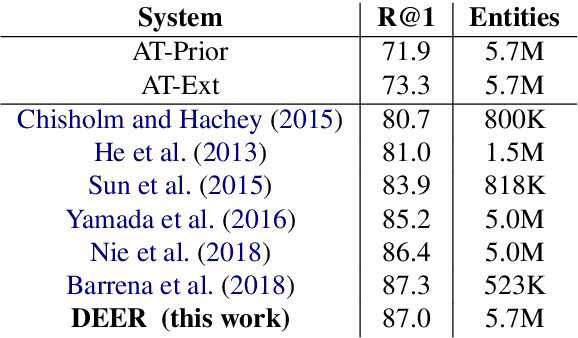
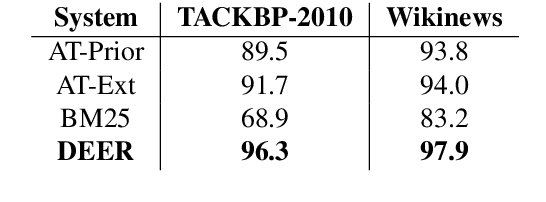
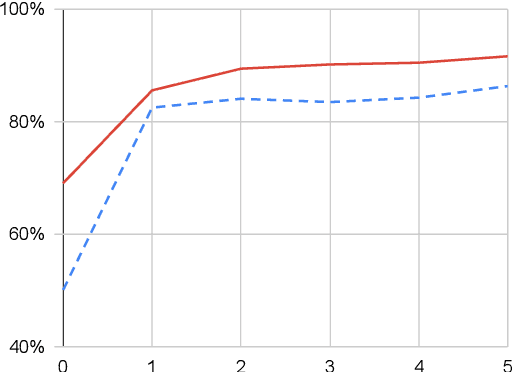
We show that it is feasible to perform entity linking by training a dual encoder (two-tower) model that encodes mentions and entities in the same dense vector space, where candidate entities are retrieved by approximate nearest neighbor search. Unlike prior work, this setup does not rely on an alias table followed by a re-ranker, and is thus the first fully learned entity retrieval model. We show that our dual encoder, trained using only anchor-text links in Wikipedia, outperforms discrete alias table and BM25 baselines, and is competitive with the best comparable results on the standard TACKBP-2010 dataset. In addition, it can retrieve candidates extremely fast, and generalizes well to a new dataset derived from Wikinews. On the modeling side, we demonstrate the dramatic value of an unsupervised negative mining algorithm for this task.
End-to-End Retrieval in Continuous Space
Nov 19, 2018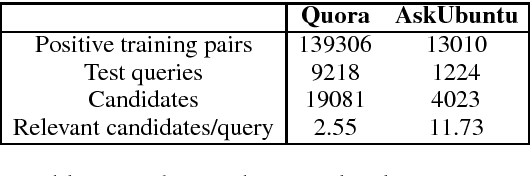
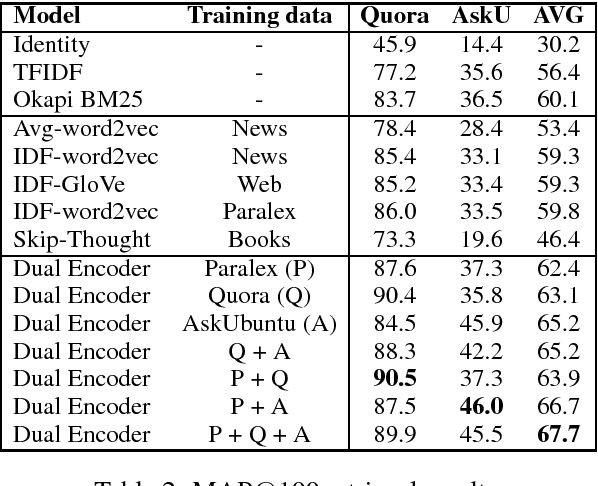
Most text-based information retrieval (IR) systems index objects by words or phrases. These discrete systems have been augmented by models that use embeddings to measure similarity in continuous space. But continuous-space models are typically used just to re-rank the top candidates. We consider the problem of end-to-end continuous retrieval, where standard approximate nearest neighbor (ANN) search replaces the usual discrete inverted index, and rely entirely on distances between learned embeddings. By training simple models specifically for retrieval, with an appropriate model architecture, we improve on a discrete baseline by 8% and 26% (MAP) on two similar-question retrieval tasks. We also discuss the problem of evaluation for retrieval systems, and show how to modify existing pairwise similarity datasets for this purpose.
Globally Normalized Transition-Based Neural Networks
Jun 08, 2016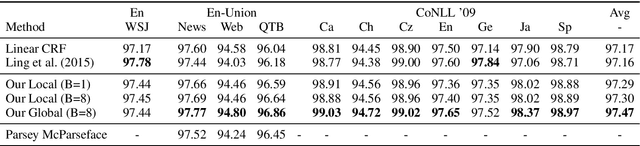
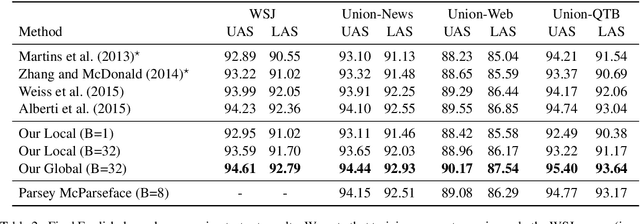
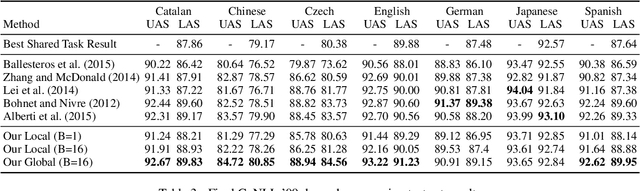
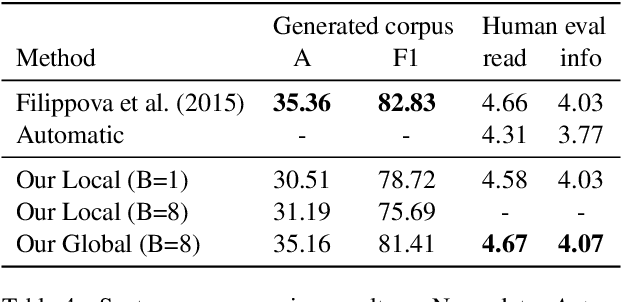
We introduce a globally normalized transition-based neural network model that achieves state-of-the-art part-of-speech tagging, dependency parsing and sentence compression results. Our model is a simple feed-forward neural network that operates on a task-specific transition system, yet achieves comparable or better accuracies than recurrent models. We discuss the importance of global as opposed to local normalization: a key insight is that the label bias problem implies that globally normalized models can be strictly more expressive than locally normalized models.