 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Surprising Effectiveness of Masking Updates in Adaptive Optimizers
Feb 17, 2026Training large language models (LLMs) relies almost exclusively on dense adaptive optimizers with increasingly sophisticated preconditioners. We challenge this by showing that randomly masking parameter updates can be highly effective, with a masked variant of RMSProp consistently outperforming recent state-of-the-art optimizers. Our analysis reveals that the random masking induces a curvature-dependent geometric regularization that smooths the optimization trajectory. Motivated by this finding, we introduce Momentum-aligned gradient masking (Magma), which modulates the masked updates using momentum-gradient alignment. Extensive LLM pre-training experiments show that Magma is a simple drop-in replacement for adaptive optimizers with consistent gains and negligible computational overhead. Notably, for the 1B model size, Magma reduces perplexity by over 19\% and 9\% compared to Adam and Muon, respectively.
Type-Compliant Adaptation Cascades: Adapting Programmatic LM Workflows to Data
Aug 25, 2025Reliably composing Large Language Models (LLMs) for complex, multi-step workflows remains a significant challenge. The dominant paradigm-optimizing discrete prompts in a pipeline-is notoriously brittle and struggles to enforce the formal compliance required for structured tasks. We introduce Type-Compliant Adaptation Cascades (TACs), a framework that recasts workflow adaptation as learning typed probabilistic programs. TACs treats the entire workflow, which is composed of parameter-efficiently adapted LLMs and deterministic logic, as an unnormalized joint distribution. This enables principled, gradient-based training even with latent intermediate structures. We provide theoretical justification for our tractable optimization objective, proving that the optimization bias vanishes as the model learns type compliance. Empirically, TACs significantly outperforms state-of-the-art prompt-optimization baselines. Gains are particularly pronounced on structured tasks, improving MGSM-SymPy from $57.1\%$ to $75.9\%$ for a 27B model, MGSM from $1.6\%$ to $27.3\%$ for a 7B model. TACs offers a robust and theoretically grounded paradigm for developing reliable, task-compliant LLM systems.
Beyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning
May 26, 2025Large Language Models (LLMs) trained via Reinforcement Learning (RL) have exhibited strong reasoning capabilities and emergent reflective behaviors, such as backtracking and error correction. However, conventional Markovian RL confines exploration to the training phase to learn an optimal deterministic policy and depends on the history contexts only through the current state. Therefore, it remains unclear whether reflective reasoning will emerge during Markovian RL training, or why they are beneficial at test time. To remedy this, we recast reflective exploration within the Bayes-Adaptive RL framework, which explicitly optimizes the expected return under a posterior distribution over Markov decision processes. This Bayesian formulation inherently incentivizes both reward-maximizing exploitation and information-gathering exploration via belief updates. Our resulting algorithm, BARL, instructs the LLM to stitch and switch strategies based on the observed outcomes, offering principled guidance on when and how the model should reflectively explore. Empirical results on both synthetic and mathematical reasoning tasks demonstrate that BARL outperforms standard Markovian RL approaches at test time, achieving superior token efficiency with improved exploration effectiveness. Our code is available at https://github.com/shenao-zhang/BARL.
Factored Agents: Decoupling In-Context Learning and Memorization for Robust Tool Use
Apr 02, 2025In this paper, we propose a novel factored agent architecture designed to overcome the limitations of traditional single-agent systems in agentic AI. Our approach decomposes the agent into two specialized components: (1) a large language model (LLM) that serves as a high level planner and in-context learner, which may use dynamically available information in user prompts, (2) a smaller language model which acts as a memorizer of tool format and output. This decoupling addresses prevalent issues in monolithic designs, including malformed, missing, and hallucinated API fields, as well as suboptimal planning in dynamic environments. Empirical evaluations demonstrate that our factored architecture significantly improves planning accuracy and error resilience, while elucidating the inherent trade-off between in-context learning and static memorization. These findings suggest that a factored approach is a promising pathway for developing more robust and adaptable agentic AI systems.
Project MPG: towards a generalized performance benchmark for LLM capabilities
Oct 28, 2024There exists an extremely wide array of LLM benchmarking tasks, whereas oftentimes a single number is the most actionable for decision-making, especially by non-experts. No such aggregation schema exists that is not Elo-based, which could be costly or time-consuming. Here we propose a method to aggregate performance across a general space of benchmarks, nicknamed Project "MPG," dubbed Model Performance and Goodness, additionally referencing a metric widely understood to be an important yet inaccurate and crude measure of car performance. Here, we create two numbers: a "Goodness" number (answer accuracy) and a "Fastness" number (cost or QPS). We compare models against each other and present a ranking according to our general metric as well as subdomains. We find significant agreement between the raw Pearson correlation of our scores and those of Chatbot Arena, even improving on the correlation of the MMLU leaderboard to Chatbot Arena.
Improving Multi-Agent Debate with Sparse Communication Topology
Jun 17, 2024Multi-agent debate has proven effective in improving large language models quality for reasoning and factuality tasks. While various role-playing strategies in multi-agent debates have been explored, in terms of the communication among agents, existing approaches adopt a brute force algorithm -- each agent can communicate with all other agents. In this paper, we systematically investigate the effect of communication connectivity in multi-agent systems. Our experiments on GPT and Mistral models reveal that multi-agent debates leveraging sparse communication topology can achieve comparable or superior performance while significantly reducing computational costs. Furthermore, we extend the multi-agent debate framework to multimodal reasoning and alignment labeling tasks, showcasing its broad applicability and effectiveness. Our findings underscore the importance of communication connectivity on enhancing the efficiency and effectiveness of the "society of minds" approach.
Pedestrian Crossing Action Recognition and Trajectory Prediction with 3D Human Keypoints
Jun 01, 2023



Accurate understanding and prediction of human behaviors are critical prerequisites for autonomous vehicles, especially in highly dynamic and interactive scenarios such as intersections in dense urban areas. In this work, we aim at identifying crossing pedestrians and predicting their future trajectories. To achieve these goals, we not only need the context information of road geometry and other traffic participants but also need fine-grained information of the human pose, motion and activity, which can be inferred from human keypoints. In this paper, we propose a novel multi-task learning framework for pedestrian crossing action recognition and trajectory prediction, which utilizes 3D human keypoints extracted from raw sensor data to capture rich information on human pose and activity. Moreover, we propose to apply two auxiliary tasks and contrastive learning to enable auxiliary supervisions to improve the learned keypoints representation, which further enhances the performance of major tasks. We validate our approach on a large-scale in-house dataset, as well as a public benchmark dataset, and show that our approach achieves state-of-the-art performance on a wide range of evaluation metrics. The effectiveness of each model component is validated in a detailed ablation study.
RecSim NG: Toward Principled Uncertainty Modeling for Recommender Ecosystems
Mar 14, 2021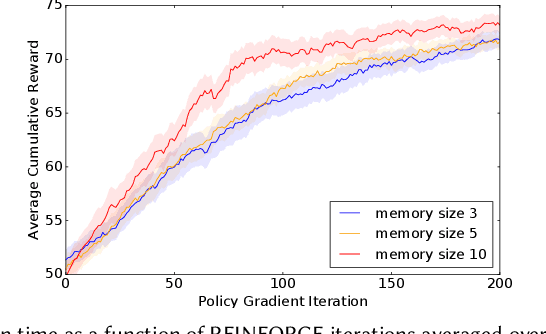
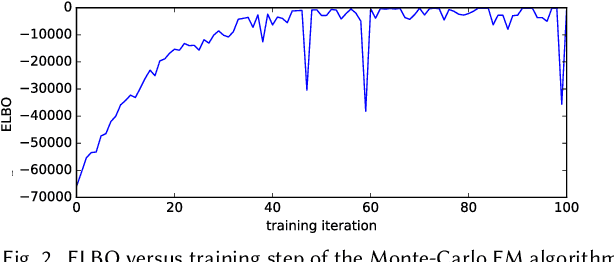
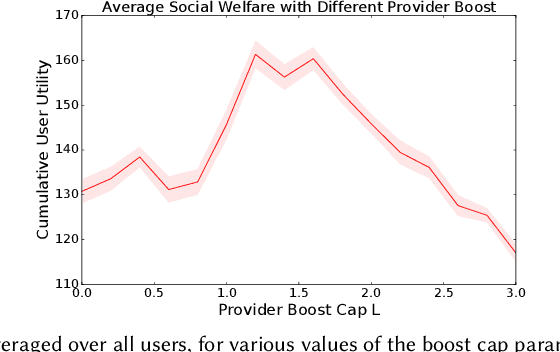
The development of recommender systems that optimize multi-turn interaction with users, and model the interactions of different agents (e.g., users, content providers, vendors) in the recommender ecosystem have drawn increasing attention in recent years. Developing and training models and algorithms for such recommenders can be especially difficult using static datasets, which often fail to offer the types of counterfactual predictions needed to evaluate policies over extended horizons. To address this, we develop RecSim NG, a probabilistic platform for the simulation of multi-agent recommender systems. RecSim NG is a scalable, modular, differentiable simulator implemented in Edward2 and TensorFlow. It offers: a powerful, general probabilistic programming language for agent-behavior specification; tools for probabilistic inference and latent-variable model learning, backed by automatic differentiation and tracing; and a TensorFlow-based runtime for running simulations on accelerated hardware. We describe RecSim NG and illustrate how it can be used to create transparent, configurable, end-to-end models of a recommender ecosystem, complemented by a small set of simple use cases that demonstrate how RecSim NG can help both researchers and practitioners easily develop and train novel algorithms for recommender systems.
On the Evaluation of Vision-and-Language Navigation Instructions
Jan 26, 2021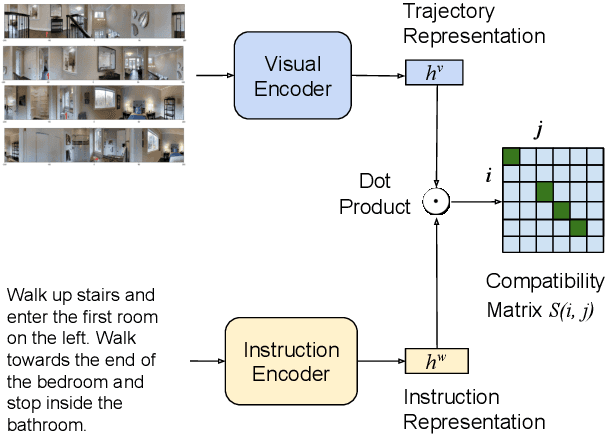
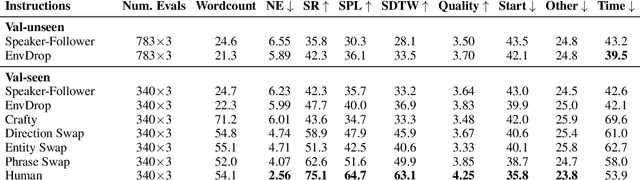
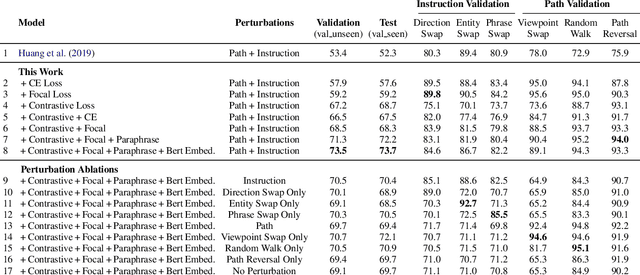
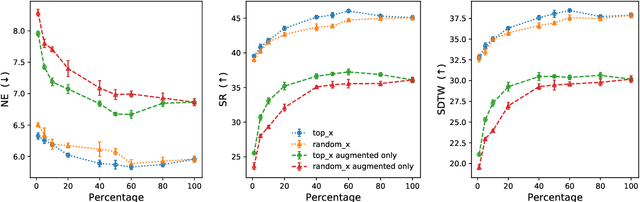
Vision-and-Language Navigation wayfinding agents can be enhanced by exploiting automatically generated navigation instructions. However, existing instruction generators have not been comprehensively evaluated, and the automatic evaluation metrics used to develop them have not been validated. Using human wayfinders, we show that these generators perform on par with or only slightly better than a template-based generator and far worse than human instructors. Furthermore, we discover that BLEU, ROUGE, METEOR and CIDEr are ineffective for evaluating grounded navigation instructions. To improve instruction evaluation, we propose an instruction-trajectory compatibility model that operates without reference instructions. Our model shows the highest correlation with human wayfinding outcomes when scoring individual instructions. For ranking instruction generation systems, if reference instructions are available we recommend using SPICE.
A Hierarchical Multi-Modal Encoder for Moment Localization in Video Corpus
Nov 24, 2020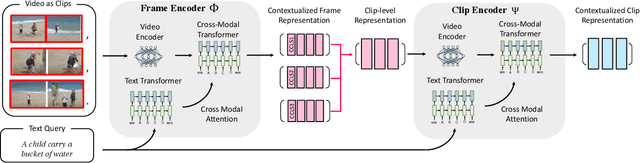
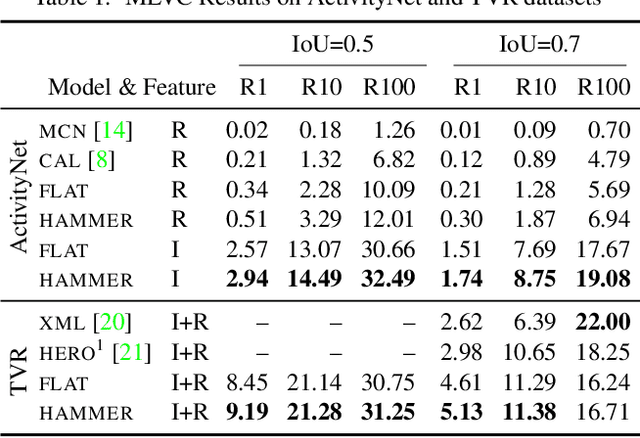
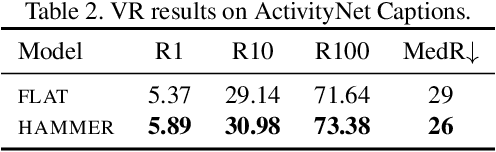
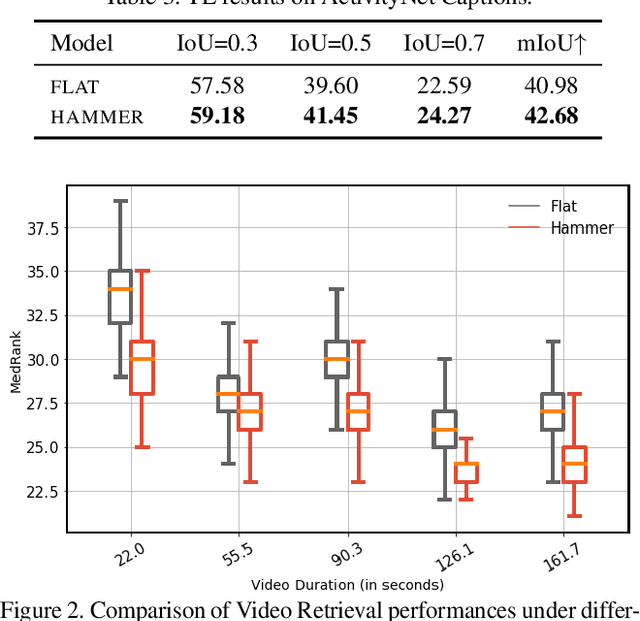
Identifying a short segment in a long video that semantically matches a text query is a challenging task that has important application potentials in language-based video search, browsing, and navigation. Typical retrieval systems respond to a query with either a whole video or a pre-defined video segment, but it is challenging to localize undefined segments in untrimmed and unsegmented videos where exhaustively searching over all possible segments is intractable. The outstanding challenge is that the representation of a video must account for different levels of granularity in the temporal domain. To tackle this problem, we propose the HierArchical Multi-Modal EncodeR (HAMMER) that encodes a video at both the coarse-grained clip level and the fine-grained frame level to extract information at different scales based on multiple subtasks, namely, video retrieval, segment temporal localization, and masked language modeling. We conduct extensive experiments to evaluate our model on moment localization in video corpus on ActivityNet Captions and TVR datasets. Our approach outperforms the previous methods as well as strong baselines, establishing new state-of-the-art for this task.