 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject MPG: towards a generalized performance benchmark for LLM capabilities
Oct 28, 2024There exists an extremely wide array of LLM benchmarking tasks, whereas oftentimes a single number is the most actionable for decision-making, especially by non-experts. No such aggregation schema exists that is not Elo-based, which could be costly or time-consuming. Here we propose a method to aggregate performance across a general space of benchmarks, nicknamed Project "MPG," dubbed Model Performance and Goodness, additionally referencing a metric widely understood to be an important yet inaccurate and crude measure of car performance. Here, we create two numbers: a "Goodness" number (answer accuracy) and a "Fastness" number (cost or QPS). We compare models against each other and present a ranking according to our general metric as well as subdomains. We find significant agreement between the raw Pearson correlation of our scores and those of Chatbot Arena, even improving on the correlation of the MMLU leaderboard to Chatbot Arena.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Scalability in Perception for Autonomous Driving: Waymo Open Dataset
Dec 18, 2019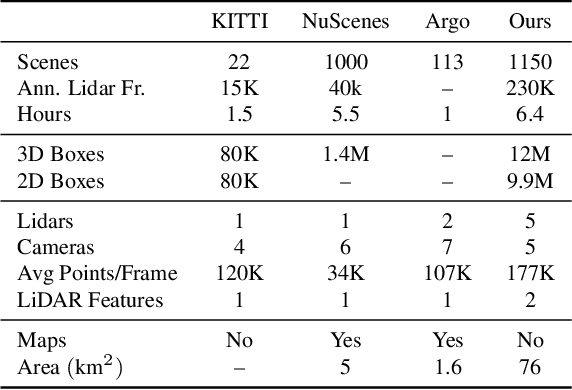



The research community has increasing interest in autonomous driving research, despite the resource intensity of obtaining representative real world data. Existing self-driving datasets are limited in the scale and variation of the environments they capture, even though generalization within and between operating regions is crucial to the overall viability of the technology. In an effort to help align the research community's contributions with real-world self-driving problems, we introduce a new large scale, high quality, diverse dataset. Our new dataset consists of 1150 scenes that each span 20 seconds, consisting of well synchronized and calibrated high quality LiDAR and camera data captured across a range of urban and suburban geographies. It is 15x more diverse than the largest camera+LiDAR dataset available based on our proposed diversity metric. We exhaustively annotated this data with 2D (camera image) and 3D (LiDAR) bounding boxes, with consistent identifiers across frames. Finally, we provide strong baselines for 2D as well as 3D detection and tracking tasks. We further study the effects of dataset size and generalization across geographies on 3D detection methods. Find data, code and more up-to-date information at http://www.waymo.com/open.