 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactored Agents: Decoupling In-Context Learning and Memorization for Robust Tool Use
Apr 02, 2025In this paper, we propose a novel factored agent architecture designed to overcome the limitations of traditional single-agent systems in agentic AI. Our approach decomposes the agent into two specialized components: (1) a large language model (LLM) that serves as a high level planner and in-context learner, which may use dynamically available information in user prompts, (2) a smaller language model which acts as a memorizer of tool format and output. This decoupling addresses prevalent issues in monolithic designs, including malformed, missing, and hallucinated API fields, as well as suboptimal planning in dynamic environments. Empirical evaluations demonstrate that our factored architecture significantly improves planning accuracy and error resilience, while elucidating the inherent trade-off between in-context learning and static memorization. These findings suggest that a factored approach is a promising pathway for developing more robust and adaptable agentic AI systems.
Project MPG: towards a generalized performance benchmark for LLM capabilities
Oct 28, 2024There exists an extremely wide array of LLM benchmarking tasks, whereas oftentimes a single number is the most actionable for decision-making, especially by non-experts. No such aggregation schema exists that is not Elo-based, which could be costly or time-consuming. Here we propose a method to aggregate performance across a general space of benchmarks, nicknamed Project "MPG," dubbed Model Performance and Goodness, additionally referencing a metric widely understood to be an important yet inaccurate and crude measure of car performance. Here, we create two numbers: a "Goodness" number (answer accuracy) and a "Fastness" number (cost or QPS). We compare models against each other and present a ranking according to our general metric as well as subdomains. We find significant agreement between the raw Pearson correlation of our scores and those of Chatbot Arena, even improving on the correlation of the MMLU leaderboard to Chatbot Arena.
Time Series Viewmakers for Robust Disruption Prediction
Oct 14, 2024



Machine Learning guided data augmentation may support the development of technologies in the physical sciences, such as nuclear fusion tokamaks. Here we endeavor to study the problem of detecting disruptions i.e. plasma instabilities that can cause significant damages, impairing the reliability and efficiency required for their real world viability. Machine learning (ML) prediction models have shown promise in detecting disruptions for specific tokamaks, but they often struggle in generalizing to the diverse characteristics and dynamics of different machines. This limits the effectiveness of ML models across different tokamak designs and operating conditions, which is a critical barrier to scaling fusion technology. Given the success of data augmentation in improving model robustness and generalizability in other fields, this study explores the use of a novel time series viewmaker network to generate diverse augmentations or "views" of training data. Our results show that incorporating views during training improves AUC and F2 scores on DisruptionBench tasks compared to standard or no augmentations. This approach represents a promising step towards developing more broadly applicable ML models for disruption avoidance, which is essential for advancing fusion technology and, ultimately, addressing climate change through reliable and sustainable energy production.
Offline Regularised Reinforcement Learning for Large Language Models Alignment
May 29, 2024The dominant framework for alignment of large language models (LLM), whether through reinforcement learning from human feedback or direct preference optimisation, is to learn from preference data. This involves building datasets where each element is a quadruplet composed of a prompt, two independent responses (completions of the prompt) and a human preference between the two independent responses, yielding a preferred and a dis-preferred response. Such data is typically scarce and expensive to collect. On the other hand, \emph{single-trajectory} datasets where each element is a triplet composed of a prompt, a response and a human feedback is naturally more abundant. The canonical element of such datasets is for instance an LLM's response to a user's prompt followed by a user's feedback such as a thumbs-up/down. Consequently, in this work, we propose DRO, or \emph{Direct Reward Optimisation}, as a framework and associated algorithms that do not require pairwise preferences. DRO uses a simple mean-squared objective that can be implemented in various ways. We validate our findings empirically, using T5 encoder-decoder language models, and show DRO's performance over selected baselines such as Kahneman-Tversky Optimization (KTO). Thus, we confirm that DRO is a simple and empirically compelling method for single-trajectory policy optimisation.
Active Reinforcement Learning for Robust Building Control
Dec 16, 2023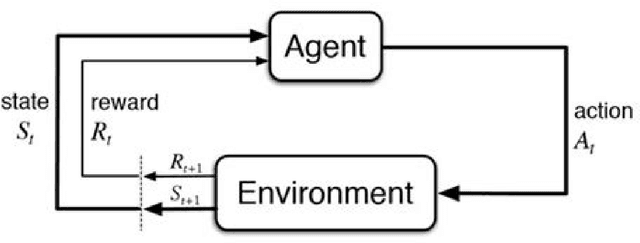
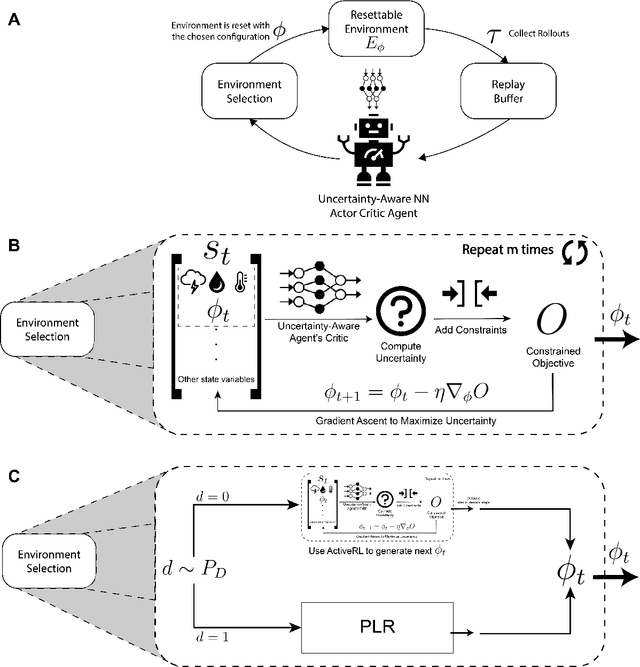
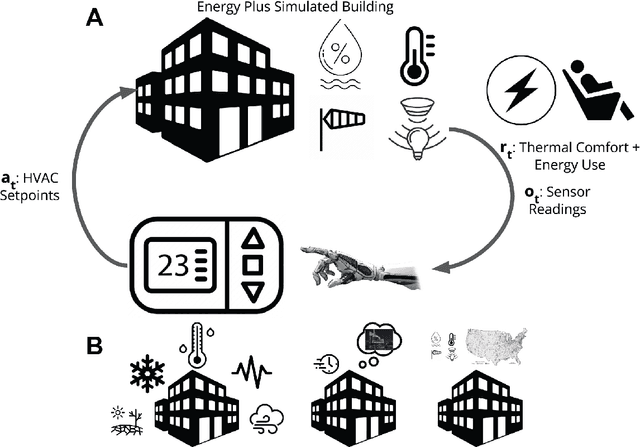
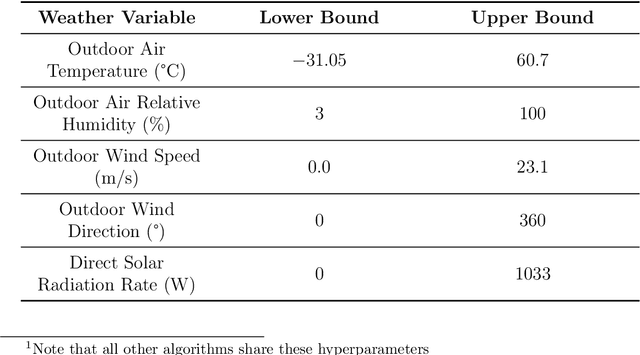
Reinforcement learning (RL) is a powerful tool for optimal control that has found great success in Atari games, the game of Go, robotic control, and building optimization. RL is also very brittle; agents often overfit to their training environment and fail to generalize to new settings. Unsupervised environment design (UED) has been proposed as a solution to this problem, in which the agent trains in environments that have been specially selected to help it learn. Previous UED algorithms focus on trying to train an RL agent that generalizes across a large distribution of environments. This is not necessarily desirable when we wish to prioritize performance in one environment over others. In this work, we will be examining the setting of robust RL building control, where we wish to train an RL agent that prioritizes performing well in normal weather while still being robust to extreme weather conditions. We demonstrate a novel UED algorithm, ActivePLR, that uses uncertainty-aware neural network architectures to generate new training environments at the limit of the RL agent's ability while being able to prioritize performance in a desired base environment. We show that ActivePLR is able to outperform state-of-the-art UED algorithms in minimizing energy usage while maximizing occupant comfort in the setting of building control.
Continuous Convolutional Neural Networks for Disruption Prediction in Nuclear Fusion Plasmas
Dec 03, 2023



Grid decarbonization for climate change requires dispatchable carbon-free energy like nuclear fusion. The tokamak concept offers a promising path for fusion, but one of the foremost challenges in implementation is the occurrence of energetic plasma disruptions. In this study, we delve into Machine Learning approaches to predict plasma state outcomes. Our contributions are twofold: (1) We present a novel application of Continuous Convolutional Neural Networks for disruption prediction and (2) We examine the advantages and disadvantages of continuous models over discrete models for disruption prediction by comparing our model with the previous, discrete state of the art, and show that continuous models offer significantly better performance (Area Under the Receiver Operating Characteristic Curve = 0.974 v.s. 0.799) with fewer parameters
Machine Learning for Smart and Energy-Efficient Buildings
Nov 27, 2022Energy consumption in buildings, both residential and commercial, accounts for approximately 40% of all energy usage in the U.S., and similar numbers are being reported from countries around the world. This significant amount of energy is used to maintain a comfortable, secure, and productive environment for the occupants. So, it is crucial that the energy consumption in buildings must be optimized, all the while maintaining satisfactory levels of occupant comfort, health, and safety. Recently, Machine Learning has been proven to be an invaluable tool in deriving important insights from data and optimizing various systems. In this work, we review the ways in which machine learning has been leveraged to make buildings smart and energy-efficient. For the convenience of readers, we provide a brief introduction of several machine learning paradigms and the components and functioning of each smart building system we cover. Finally, we discuss challenges faced while implementing machine learning algorithms in smart buildings and provide future avenues for research at the intersection of smart buildings and machine learning.
Personalized Federated Hypernetworks for Privacy Preservation in Multi-Task Reinforcement Learning
Oct 19, 2022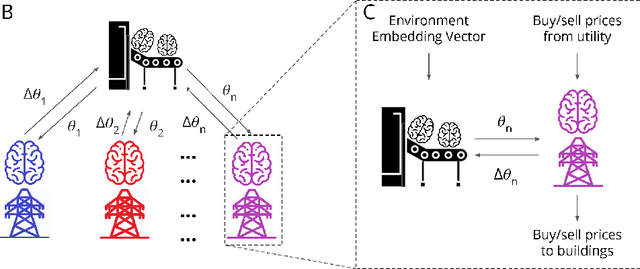
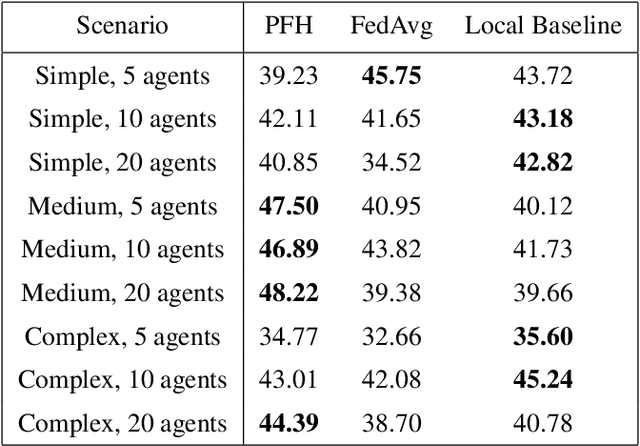
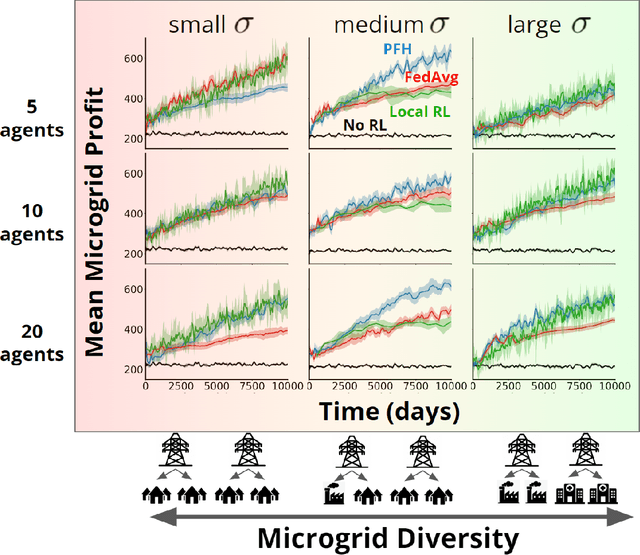
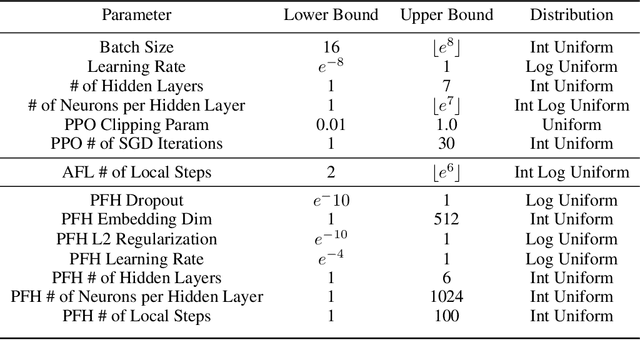
Multi-Agent Reinforcement Learning currently focuses on implementations where all data and training can be centralized to one machine. But what if local agents are split across multiple tasks, and need to keep data private between each? We develop the first application of Personalized Federated Hypernetworks (PFH) to Reinforcement Learning (RL). We then present a novel application of PFH to few-shot transfer, and demonstrate significant initial increases in learning. PFH has never been demonstrated beyond supervised learning benchmarks, so we apply PFH to an important domain: RL price-setting for energy demand response. We consider a general case across where agents are split across multiple microgrids, wherein energy consumption data must be kept private within each microgrid. Together, our work explores how the fields of personalized federated learning and RL can come together to make learning efficient across multiple tasks while keeping data secure.
Adapting Surprise Minimizing Reinforcement Learning Techniques for Transactive Control
Nov 11, 2021
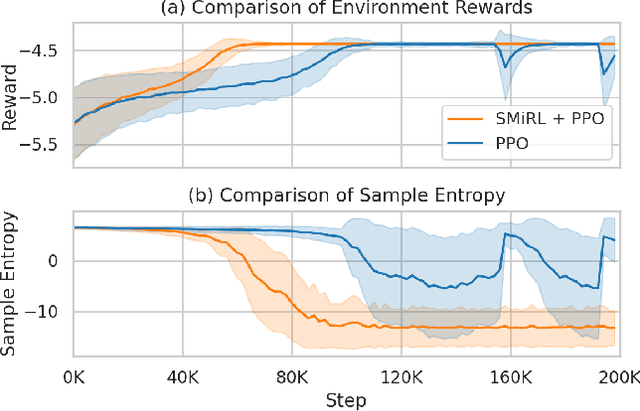
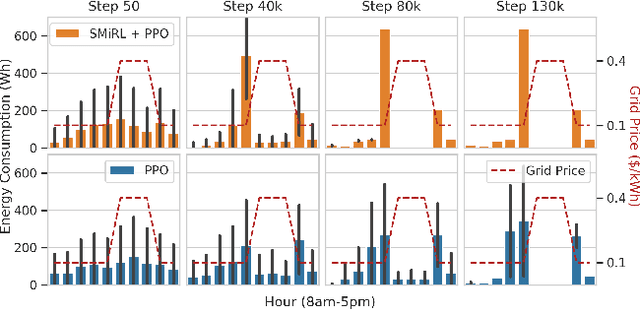
Optimizing prices for energy demand response requires a flexible controller with ability to navigate complex environments. We propose a reinforcement learning controller with surprise minimizing modifications in its architecture. We suggest that surprise minimization can be used to improve learning speed, taking advantage of predictability in peoples' energy usage. Our architecture performs well in a simulation of energy demand response. We propose this modification to improve functionality and save in a large scale experiment.
Offline-Online Reinforcement Learning for Energy Pricing in Office Demand Response: Lowering Energy and Data Costs
Aug 14, 2021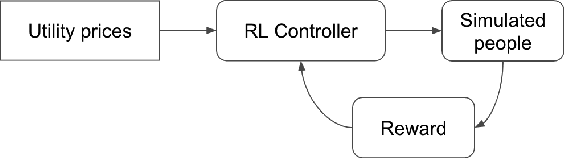

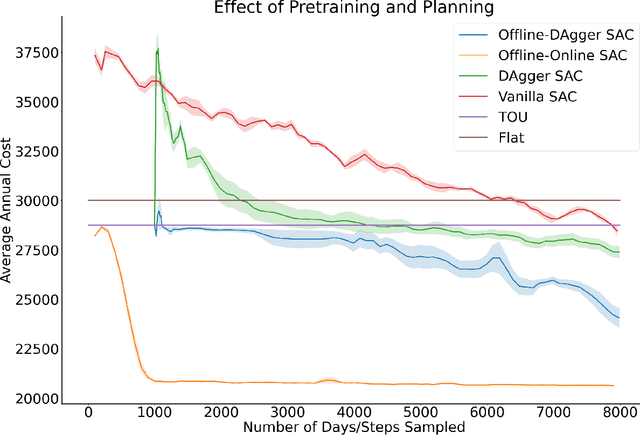
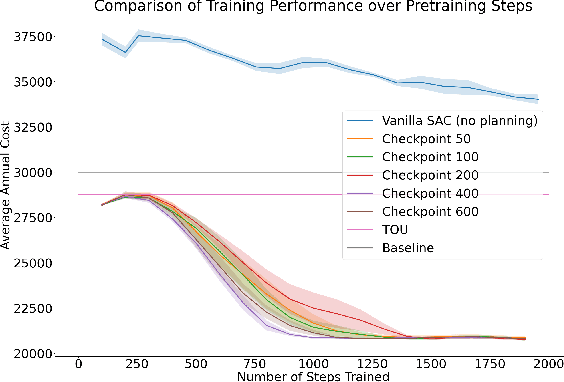
Our team is proposing to run a full-scale energy demand response experiment in an office building. Although this is an exciting endeavor which will provide value to the community, collecting training data for the reinforcement learning agent is costly and will be limited. In this work, we examine how offline training can be leveraged to minimize data costs (accelerate convergence) and program implementation costs. We present two approaches to doing so: pretraining our model to warm start the experiment with simulated tasks, and using a planning model trained to simulate the real world's rewards to the agent. We present results that demonstrate the utility of offline reinforcement learning to efficient price-setting in the energy demand response problem.