 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Contrastive Policy Gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion
Jun 27, 2024Reinforcement Learning (RL) has been used to finetune Large Language Models (LLMs) using a reward model trained from preference data, to better align with human judgment. The recently introduced direct alignment methods, which are often simpler, more stable, and computationally lighter, can more directly achieve this. However, these approaches cannot optimize arbitrary rewards, and the preference-based ones are not the only rewards of interest for LLMs (eg., unit tests for code generation or textual entailment for summarization, among others). RL-finetuning is usually done with a variation of policy gradient, which calls for on-policy or near-on-policy samples, requiring costly generations. We introduce Contrastive Policy Gradient, or CoPG, a simple and mathematically principled new RL algorithm that can estimate the optimal policy even from off-policy data. It can be seen as an off-policy policy gradient approach that does not rely on important sampling techniques and highlights the importance of using (the right) state baseline. We show this approach to generalize the direct alignment method IPO (identity preference optimization) and classic policy gradient. We experiment with the proposed CoPG on a toy bandit problem to illustrate its properties, as well as for finetuning LLMs on a summarization task, using a learned reward function considered as ground truth for the purpose of the experiments.
Averaging log-likelihoods in direct alignment
Jun 27, 2024



To better align Large Language Models (LLMs) with human judgment, Reinforcement Learning from Human Feedback (RLHF) learns a reward model and then optimizes it using regularized RL. Recently, direct alignment methods were introduced to learn such a fine-tuned model directly from a preference dataset without computing a proxy reward function. These methods are built upon contrastive losses involving the log-likelihood of (dis)preferred completions according to the trained model. However, completions have various lengths, and the log-likelihood is not length-invariant. On the other side, the cross-entropy loss used in supervised training is length-invariant, as batches are typically averaged token-wise. To reconcile these approaches, we introduce a principled approach for making direct alignment length-invariant. Formally, we introduce a new averaging operator, to be composed with the optimality operator giving the best policy for the underlying RL problem. It translates into averaging the log-likelihood within the loss. We empirically study the effect of such averaging, observing a trade-off between the length of generations and their scores.
Self-Improving Robust Preference Optimization
Jun 03, 2024


Both online and offline RLHF methods such as PPO and DPO have been extremely successful in aligning AI with human preferences. Despite their success, the existing methods suffer from a fundamental problem that their optimal solution is highly task-dependent (i.e., not robust to out-of-distribution (OOD) tasks). Here we address this challenge by proposing Self-Improving Robust Preference Optimization SRPO, a practical and mathematically principled offline RLHF framework that is completely robust to the changes in the task. The key idea of SRPO is to cast the problem of learning from human preferences as a self-improvement process, which can be mathematically expressed in terms of a min-max objective that aims at joint optimization of self-improvement policy and the generative policy in an adversarial fashion. The solution for this optimization problem is independent of the training task and thus it is robust to its changes. We then show that this objective can be re-expressed in the form of a non-adversarial offline loss which can be optimized using standard supervised optimization techniques at scale without any need for reward model and online inference. We show the effectiveness of SRPO in terms of AI Win-Rate (WR) against human (GOLD) completions. In particular, when SRPO is evaluated on the OOD XSUM dataset, it outperforms the celebrated DPO by a clear margin of 15% after 5 self-revisions, achieving WR of 90%.
Offline Regularised Reinforcement Learning for Large Language Models Alignment
May 29, 2024The dominant framework for alignment of large language models (LLM), whether through reinforcement learning from human feedback or direct preference optimisation, is to learn from preference data. This involves building datasets where each element is a quadruplet composed of a prompt, two independent responses (completions of the prompt) and a human preference between the two independent responses, yielding a preferred and a dis-preferred response. Such data is typically scarce and expensive to collect. On the other hand, \emph{single-trajectory} datasets where each element is a triplet composed of a prompt, a response and a human feedback is naturally more abundant. The canonical element of such datasets is for instance an LLM's response to a user's prompt followed by a user's feedback such as a thumbs-up/down. Consequently, in this work, we propose DRO, or \emph{Direct Reward Optimisation}, as a framework and associated algorithms that do not require pairwise preferences. DRO uses a simple mean-squared objective that can be implemented in various ways. We validate our findings empirically, using T5 encoder-decoder language models, and show DRO's performance over selected baselines such as Kahneman-Tversky Optimization (KTO). Thus, we confirm that DRO is a simple and empirically compelling method for single-trajectory policy optimisation.
Nash Learning from Human Feedback
Dec 06, 2023



Reinforcement learning from human feedback (RLHF) has emerged as the main paradigm for aligning large language models (LLMs) with human preferences. Typically, RLHF involves the initial step of learning a reward model from human feedback, often expressed as preferences between pairs of text generations produced by a pre-trained LLM. Subsequently, the LLM's policy is fine-tuned by optimizing it to maximize the reward model through a reinforcement learning algorithm. However, an inherent limitation of current reward models is their inability to fully represent the richness of human preferences and their dependency on the sampling distribution. In this study, we introduce an alternative pipeline for the fine-tuning of LLMs using pairwise human feedback. Our approach entails the initial learning of a preference model, which is conditioned on two inputs given a prompt, followed by the pursuit of a policy that consistently generates responses preferred over those generated by any competing policy, thus defining the Nash equilibrium of this preference model. We term this approach Nash learning from human feedback (NLHF). In the context of a tabular policy representation, we present a novel algorithmic solution, Nash-MD, founded on the principles of mirror descent. This algorithm produces a sequence of policies, with the last iteration converging to the regularized Nash equilibrium. Additionally, we explore parametric representations of policies and introduce gradient descent algorithms for deep-learning architectures. To demonstrate the effectiveness of our approach, we present experimental results involving the fine-tuning of a LLM for a text summarization task. We believe NLHF offers a compelling avenue for preference learning and policy optimization with the potential of advancing the field of aligning LLMs with human preferences.
A General Theoretical Paradigm to Understand Learning from Human Preferences
Oct 18, 2023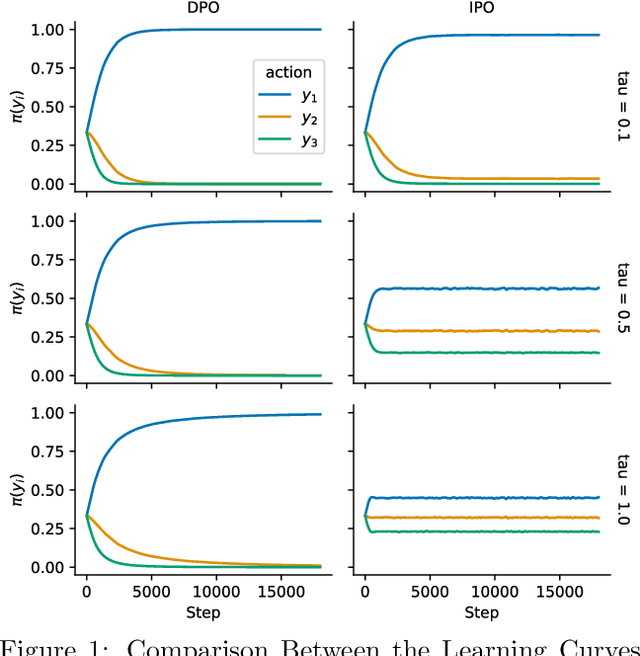

The prevalent deployment of learning from human preferences through reinforcement learning (RLHF) relies on two important approximations: the first assumes that pairwise preferences can be substituted with pointwise rewards. The second assumes that a reward model trained on these pointwise rewards can generalize from collected data to out-of-distribution data sampled by the policy. Recently, Direct Preference Optimisation (DPO) has been proposed as an approach that bypasses the second approximation and learn directly a policy from collected data without the reward modelling stage. However, this method still heavily relies on the first approximation. In this paper we try to gain a deeper theoretical understanding of these practical algorithms. In particular we derive a new general objective called $\Psi$PO for learning from human preferences that is expressed in terms of pairwise preferences and therefore bypasses both approximations. This new general objective allows us to perform an in-depth analysis of the behavior of RLHF and DPO (as special cases of $\Psi$PO) and to identify their potential pitfalls. We then consider another special case for $\Psi$PO by setting $\Psi$ simply to Identity, for which we can derive an efficient optimisation procedure, prove performance guarantees and demonstrate its empirical superiority to DPO on some illustrative examples.
Regularization and Variance-Weighted Regression Achieves Minimax Optimality in Linear MDPs: Theory and Practice
May 22, 2023Mirror descent value iteration (MDVI), an abstraction of Kullback-Leibler (KL) and entropy-regularized reinforcement learning (RL), has served as the basis for recent high-performing practical RL algorithms. However, despite the use of function approximation in practice, the theoretical understanding of MDVI has been limited to tabular Markov decision processes (MDPs). We study MDVI with linear function approximation through its sample complexity required to identify an $\varepsilon$-optimal policy with probability $1-\delta$ under the settings of an infinite-horizon linear MDP, generative model, and G-optimal design. We demonstrate that least-squares regression weighted by the variance of an estimated optimal value function of the next state is crucial to achieving minimax optimality. Based on this observation, we present Variance-Weighted Least-Squares MDVI (VWLS-MDVI), the first theoretical algorithm that achieves nearly minimax optimal sample complexity for infinite-horizon linear MDPs. Furthermore, we propose a practical VWLS algorithm for value-based deep RL, Deep Variance Weighting (DVW). Our experiments demonstrate that DVW improves the performance of popular value-based deep RL algorithms on a set of MinAtar benchmarks.
An Analysis of Quantile Temporal-Difference Learning
Jan 11, 2023



We analyse quantile temporal-difference learning (QTD), a distributional reinforcement learning algorithm that has proven to be a key component in several successful large-scale applications of reinforcement learning. Despite these empirical successes, a theoretical understanding of QTD has proven elusive until now. Unlike classical TD learning, which can be analysed with standard stochastic approximation tools, QTD updates do not approximate contraction mappings, are highly non-linear, and may have multiple fixed points. The core result of this paper is a proof of convergence to the fixed points of a related family of dynamic programming procedures with probability 1, putting QTD on firm theoretical footing. The proof establishes connections between QTD and non-linear differential inclusions through stochastic approximation theory and non-smooth analysis.
Understanding Self-Predictive Learning for Reinforcement Learning
Dec 06, 2022



We study the learning dynamics of self-predictive learning for reinforcement learning, a family of algorithms that learn representations by minimizing the prediction error of their own future latent representations. Despite its recent empirical success, such algorithms have an apparent defect: trivial representations (such as constants) minimize the prediction error, yet it is obviously undesirable to converge to such solutions. Our central insight is that careful designs of the optimization dynamics are critical to learning meaningful representations. We identify that a faster paced optimization of the predictor and semi-gradient updates on the representation, are crucial to preventing the representation collapse. Then in an idealized setup, we show self-predictive learning dynamics carries out spectral decomposition on the state transition matrix, effectively capturing information of the transition dynamics. Building on the theoretical insights, we propose bidirectional self-predictive learning, a novel self-predictive algorithm that learns two representations simultaneously. We examine the robustness of our theoretical insights with a number of small-scale experiments and showcase the promise of the novel representation learning algorithm with large-scale experiments.