 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiQ: Bringing back Bellman to LLMs
May 16, 2025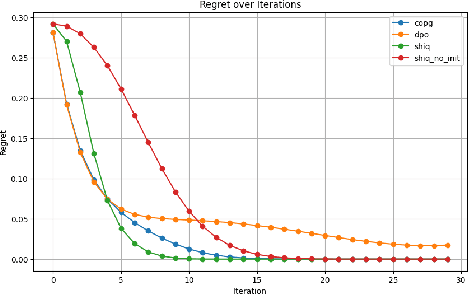
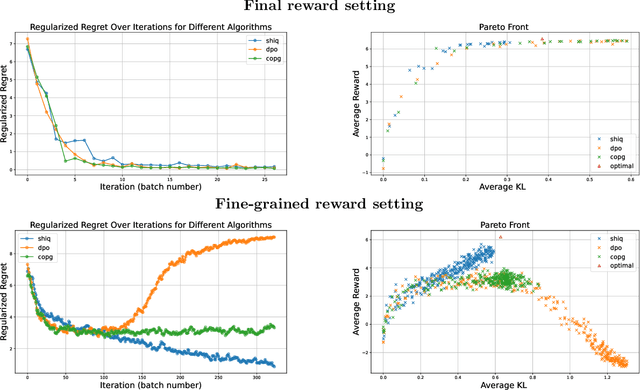

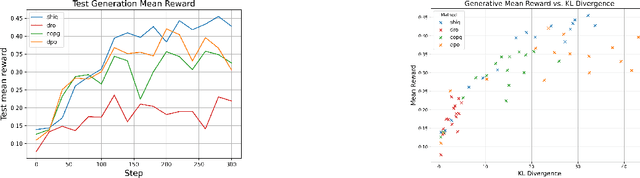
The fine-tuning of pre-trained large language models (LLMs) using reinforcement learning (RL) is generally formulated as direct policy optimization. This approach was naturally favored as it efficiently improves a pretrained LLM, seen as an initial policy. Another RL paradigm, Q-learning methods, has received far less attention in the LLM community while demonstrating major success in various non-LLM RL tasks. In particular, Q-learning effectiveness comes from its sample efficiency and ability to learn offline, which is particularly valuable given the high computational cost of sampling with LLMs. However, naively applying a Q-learning-style update to the model's logits is ineffective due to the specificity of LLMs. Our core contribution is to derive theoretically grounded loss functions from Bellman equations to adapt Q-learning methods to LLMs. To do so, we carefully adapt insights from the RL literature to account for LLM-specific characteristics, ensuring that the logits become reliable Q-value estimates. We then use this loss to build a practical algorithm, ShiQ for Shifted-Q, that supports off-policy, token-wise learning while remaining simple to implement. Finally, we evaluate ShiQ on both synthetic data and real-world benchmarks, e.g., UltraFeedback and BFCL-V3, demonstrating its effectiveness in both single-turn and multi-turn LLM settings
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier
Dec 05, 2024



We introduce the Aya Expanse model family, a new generation of 8B and 32B parameter multilingual language models, aiming to address the critical challenge of developing highly performant multilingual models that match or surpass the capabilities of monolingual models. By leveraging several years of research at Cohere For AI and Cohere, including advancements in data arbitrage, multilingual preference training, and model merging, Aya Expanse sets a new state-of-the-art in multilingual performance. Our evaluations on the Arena-Hard-Auto dataset, translated into 23 languages, demonstrate that Aya Expanse 8B and 32B outperform leading open-weight models in their respective parameter classes, including Gemma 2, Qwen 2.5, and Llama 3.1, achieving up to a 76.6% win-rate. Notably, Aya Expanse 32B outperforms Llama 3.1 70B, a model with twice as many parameters, achieving a 54.0% win-rate. In this short technical report, we present extended evaluation results for the Aya Expanse model family and release their open-weights, together with a new multilingual evaluation dataset m-ArenaHard.
Contrastive Policy Gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion
Jun 27, 2024Reinforcement Learning (RL) has been used to finetune Large Language Models (LLMs) using a reward model trained from preference data, to better align with human judgment. The recently introduced direct alignment methods, which are often simpler, more stable, and computationally lighter, can more directly achieve this. However, these approaches cannot optimize arbitrary rewards, and the preference-based ones are not the only rewards of interest for LLMs (eg., unit tests for code generation or textual entailment for summarization, among others). RL-finetuning is usually done with a variation of policy gradient, which calls for on-policy or near-on-policy samples, requiring costly generations. We introduce Contrastive Policy Gradient, or CoPG, a simple and mathematically principled new RL algorithm that can estimate the optimal policy even from off-policy data. It can be seen as an off-policy policy gradient approach that does not rely on important sampling techniques and highlights the importance of using (the right) state baseline. We show this approach to generalize the direct alignment method IPO (identity preference optimization) and classic policy gradient. We experiment with the proposed CoPG on a toy bandit problem to illustrate its properties, as well as for finetuning LLMs on a summarization task, using a learned reward function considered as ground truth for the purpose of the experiments.
Averaging log-likelihoods in direct alignment
Jun 27, 2024



To better align Large Language Models (LLMs) with human judgment, Reinforcement Learning from Human Feedback (RLHF) learns a reward model and then optimizes it using regularized RL. Recently, direct alignment methods were introduced to learn such a fine-tuned model directly from a preference dataset without computing a proxy reward function. These methods are built upon contrastive losses involving the log-likelihood of (dis)preferred completions according to the trained model. However, completions have various lengths, and the log-likelihood is not length-invariant. On the other side, the cross-entropy loss used in supervised training is length-invariant, as batches are typically averaged token-wise. To reconcile these approaches, we introduce a principled approach for making direct alignment length-invariant. Formally, we introduce a new averaging operator, to be composed with the optimality operator giving the best policy for the underlying RL problem. It translates into averaging the log-likelihood within the loss. We empirically study the effect of such averaging, observing a trade-off between the length of generations and their scores.
Countering Reward Over-optimization in LLM with Demonstration-Guided Reinforcement Learning
Apr 30, 2024



While Reinforcement Learning (RL) has been proven essential for tuning large language models (LLMs), it can lead to reward over-optimization (ROO). Existing approaches address ROO by adding KL regularization, requiring computationally expensive hyperparameter tuning. Additionally, KL regularization focuses solely on regularizing the language policy, neglecting a potential source of regularization: the reward function itself. Inspired by demonstration-guided RL, we here introduce the Reward Calibration from Demonstration (RCfD), which leverages human demonstrations and a reward model to recalibrate the reward objective. Formally, given a prompt, the RCfD objective minimizes the distance between the demonstrations' and LLM's rewards rather than directly maximizing the reward function. This objective shift avoids incentivizing the LLM to exploit the reward model and promotes more natural and diverse language generation. We show the effectiveness of RCfD on three language tasks, which achieves comparable performance to carefully tuned baselines while mitigating ROO.
Language Evolution with Deep Learning
Mar 18, 2024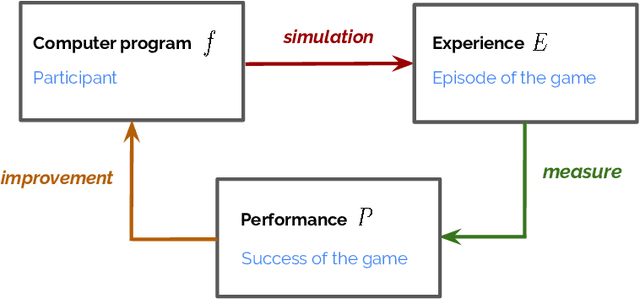
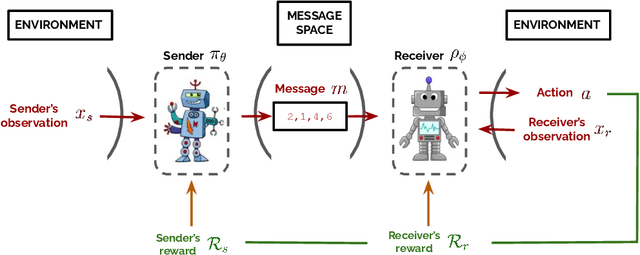
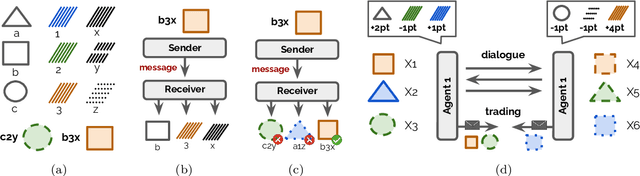

Computational modeling plays an essential role in the study of language emergence. It aims to simulate the conditions and learning processes that could trigger the emergence of a structured language within a simulated controlled environment. Several methods have been used to investigate the origin of our language, including agent-based systems, Bayesian agents, genetic algorithms, and rule-based systems. This chapter explores another class of computational models that have recently revolutionized the field of machine learning: deep learning models. The chapter introduces the basic concepts of deep and reinforcement learning methods and summarizes their helpfulness for simulating language emergence. It also discusses the key findings, limitations, and recent attempts to build realistic simulations. This chapter targets linguists and cognitive scientists seeking an introduction to deep learning as a tool to investigate language evolution.
Language Model Alignment with Elastic Reset
Dec 06, 2023Finetuning language models with reinforcement learning (RL), e.g. from human feedback (HF), is a prominent method for alignment. But optimizing against a reward model can improve on reward while degrading performance in other areas, a phenomenon known as reward hacking, alignment tax, or language drift. First, we argue that commonly-used test metrics are insufficient and instead measure how different algorithms tradeoff between reward and drift. The standard method modified the reward with a Kullback-Lieber (KL) penalty between the online and initial model. We propose Elastic Reset, a new algorithm that achieves higher reward with less drift without explicitly modifying the training objective. We periodically reset the online model to an exponentially moving average (EMA) of itself, then reset the EMA model to the initial model. Through the use of an EMA, our model recovers quickly after resets and achieves higher reward with less drift in the same number of steps. We demonstrate that fine-tuning language models with Elastic Reset leads to state-of-the-art performance on a small scale pivot-translation benchmark, outperforms all baselines in a medium-scale RLHF-like IMDB mock sentiment task and leads to a more performant and more aligned technical QA chatbot with LLaMA-7B. Code available at github.com/mnoukhov/elastic-reset.
The Edge of Orthogonality: A Simple View of What Makes BYOL Tick
Feb 09, 2023Self-predictive unsupervised learning methods such as BYOL or SimSiam have shown impressive results, and counter-intuitively, do not collapse to trivial representations. In this work, we aim at exploring the simplest possible mathematical arguments towards explaining the underlying mechanisms behind self-predictive unsupervised learning. We start with the observation that those methods crucially rely on the presence of a predictor network (and stop-gradient). With simple linear algebra, we show that when using a linear predictor, the optimal predictor is close to an orthogonal projection, and propose a general framework based on orthonormalization that enables to interpret and give intuition on why BYOL works. In addition, this framework demonstrates the crucial role of the exponential moving average and stop-gradient operator in BYOL as an efficient orthonormalization mechanism. We use these insights to propose four new \emph{closed-form predictor} variants of BYOL to support our analysis. Our closed-form predictors outperform standard linear trainable predictor BYOL at $100$ and $300$ epochs (top-$1$ linear accuracy on ImageNet).
SemPPL: Predicting pseudo-labels for better contrastive representations
Jan 12, 2023Learning from large amounts of unsupervised data and a small amount of supervision is an important open problem in computer vision. We propose a new semi-supervised learning method, Semantic Positives via Pseudo-Labels (SemPPL), that combines labelled and unlabelled data to learn informative representations. Our method extends self-supervised contrastive learning -- where representations are shaped by distinguishing whether two samples represent the same underlying datum (positives) or not (negatives) -- with a novel approach to selecting positives. To enrich the set of positives, we leverage the few existing ground-truth labels to predict the missing ones through a $k$-nearest neighbours classifier by using the learned embeddings of the labelled data. We thus extend the set of positives with datapoints having the same pseudo-label and call these semantic positives. We jointly learn the representation and predict bootstrapped pseudo-labels. This creates a reinforcing cycle. Strong initial representations enable better pseudo-label predictions which then improve the selection of semantic positives and lead to even better representations. SemPPL outperforms competing semi-supervised methods setting new state-of-the-art performance of $68.5\%$ and $76\%$ top-$1$ accuracy when using a ResNet-$50$ and training on $1\%$ and $10\%$ of labels on ImageNet, respectively. Furthermore, when using selective kernels, SemPPL significantly outperforms previous state-of-the-art achieving $72.3\%$ and $78.3\%$ top-$1$ accuracy on ImageNet with $1\%$ and $10\%$ labels, respectively, which improves absolute $+7.8\%$ and $+6.2\%$ over previous work. SemPPL also exhibits state-of-the-art performance over larger ResNet models as well as strong robustness, out-of-distribution and transfer performance.