 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountering Reward Over-optimization in LLM with Demonstration-Guided Reinforcement Learning
Apr 30, 2024



While Reinforcement Learning (RL) has been proven essential for tuning large language models (LLMs), it can lead to reward over-optimization (ROO). Existing approaches address ROO by adding KL regularization, requiring computationally expensive hyperparameter tuning. Additionally, KL regularization focuses solely on regularizing the language policy, neglecting a potential source of regularization: the reward function itself. Inspired by demonstration-guided RL, we here introduce the Reward Calibration from Demonstration (RCfD), which leverages human demonstrations and a reward model to recalibrate the reward objective. Formally, given a prompt, the RCfD objective minimizes the distance between the demonstrations' and LLM's rewards rather than directly maximizing the reward function. This objective shift avoids incentivizing the LLM to exploit the reward model and promotes more natural and diverse language generation. We show the effectiveness of RCfD on three language tasks, which achieves comparable performance to carefully tuned baselines while mitigating ROO.
Language Evolution with Deep Learning
Mar 18, 2024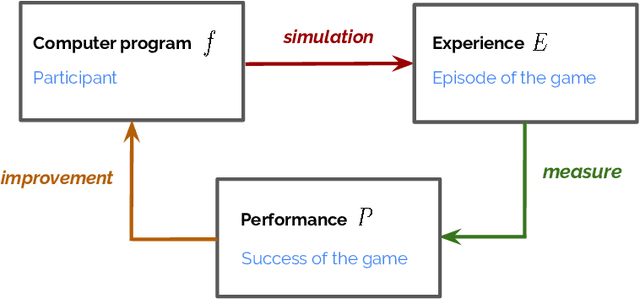
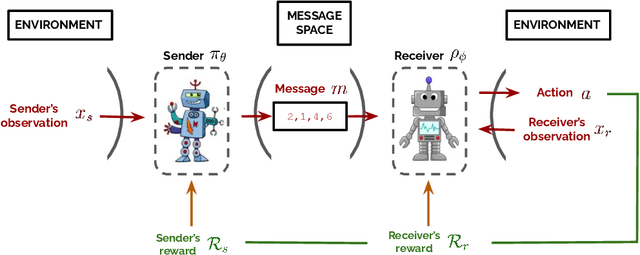

Computational modeling plays an essential role in the study of language emergence. It aims to simulate the conditions and learning processes that could trigger the emergence of a structured language within a simulated controlled environment. Several methods have been used to investigate the origin of our language, including agent-based systems, Bayesian agents, genetic algorithms, and rule-based systems. This chapter explores another class of computational models that have recently revolutionized the field of machine learning: deep learning models. The chapter introduces the basic concepts of deep and reinforcement learning methods and summarizes their helpfulness for simulating language emergence. It also discusses the key findings, limitations, and recent attempts to build realistic simulations. This chapter targets linguists and cognitive scientists seeking an introduction to deep learning as a tool to investigate language evolution.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Memory Consolidation Enables Long-Context Video Understanding
Feb 08, 2024



Most transformer-based video encoders are limited to short temporal contexts due to their quadratic complexity. While various attempts have been made to extend this context, this has often come at the cost of both conceptual and computational complexity. We propose to instead re-purpose existing pre-trained video transformers by simply fine-tuning them to attend to memories derived non-parametrically from past activations. By leveraging redundancy reduction, our memory-consolidated vision transformer (MC-ViT) effortlessly extends its context far into the past and exhibits excellent scaling behavior when learning from longer videos. In doing so, MC-ViT sets a new state-of-the-art in long-context video understanding on EgoSchema, Perception Test, and Diving48, outperforming methods that benefit from orders of magnitude more parameters.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Can Transformers Jump Around Right in Natural Language? Assessing Performance Transfer from SCAN
Jul 03, 2021
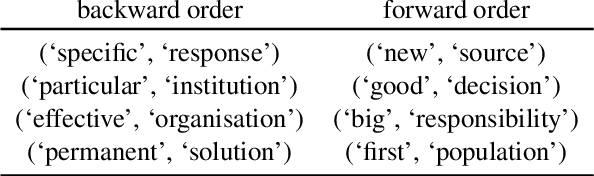
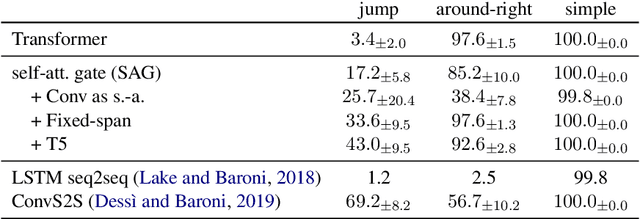
Despite their practical success, modern seq2seq architectures are unable to generalize systematically on several SCAN tasks. Hence, it is not clear if SCAN-style compositional generalization is useful in realistic NLP tasks. In this work, we study the benefit that such compositionality brings about to several machine translation tasks. We present several focused modifications of Transformer that greatly improve generalization capabilities on SCAN and select one that remains on par with a vanilla Transformer on a standard machine translation (MT) task. Next, we study its performance in low-resource settings and on a newly introduced distribution-shifted English-French translation task. Overall, we find that improvements of a SCAN-capable model do not directly transfer to the resource-rich MT setup. In contrast, in the low-resource setup, general modifications lead to an improvement of up to 13.1% BLEU score w.r.t. a vanilla Transformer. Similarly, an improvement of 14% in an accuracy-based metric is achieved in the introduced compositional English-French translation task. This provides experimental evidence that the compositional generalization assessed in SCAN is particularly useful in resource-starved and domain-shifted scenarios.
"LazImpa": Lazy and Impatient neural agents learn to communicate efficiently
Oct 05, 2020


Previous work has shown that artificial neural agents naturally develop surprisingly non-efficient codes. This is illustrated by the fact that in a referential game involving a speaker and a listener neural networks optimizing accurate transmission over a discrete channel, the emergent messages fail to achieve an optimal length. Furthermore, frequent messages tend to be longer than infrequent ones, a pattern contrary to the Zipf Law of Abbreviation (ZLA) observed in all natural languages. Here, we show that near-optimal and ZLA-compatible messages can emerge, but only if both the speaker and the listener are modified. We hence introduce a new communication system, "LazImpa", where the speaker is made increasingly lazy, i.e. avoids long messages, and the listener impatient, i.e.,~seeks to guess the intended content as soon as possible.
What they do when in doubt: a study of inductive biases in seq2seq learners
Jun 26, 2020



Sequence-to-sequence (seq2seq) learners are widely used, but we still have only limited knowledge about what inductive biases shape the way they generalize. We address that by investigating how popular seq2seq learners generalize in tasks that have high ambiguity in the training data. We use SCAN and three new tasks to study learners' preferences for memorization, arithmetic, hierarchical, and compositional reasoning. Further, we connect to Solomonoff's theory of induction and propose to use description length as a principled and sensitive measure of inductive biases. In our experimental study, we find that LSTM-based learners can learn to perform counting, addition, and multiplication by a constant from a single training example. Furthermore, Transformer and LSTM-based learners show a bias toward the hierarchical induction over the linear one, while CNN-based learners prefer the opposite. On the SCAN dataset, we find that CNN-based, and, to a lesser degree, Transformer- and LSTM-based learners have a preference for compositional generalization over memorization. Finally, across all our experiments, description length proved to be a sensitive measure of inductive biases.
Compositionality and Generalization in Emergent Languages
Apr 20, 2020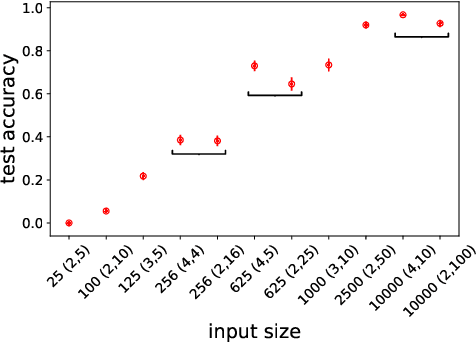



Natural language allows us to refer to novel composite concepts by combining expressions denoting their parts according to systematic rules, a property known as \emph{compositionality}. In this paper, we study whether the language emerging in deep multi-agent simulations possesses a similar ability to refer to novel primitive combinations, and whether it accomplishes this feat by strategies akin to human-language compositionality. Equipped with new ways to measure compositionality in emergent languages inspired by disentanglement in representation learning, we establish three main results. First, given sufficiently large input spaces, the emergent language will naturally develop the ability to refer to novel composite concepts. Second, there is no correlation between the degree of compositionality of an emergent language and its ability to generalize. Third, while compositionality is not necessary for generalization, it provides an advantage in terms of language transmission: The more compositional a language is, the more easily it will be picked up by new learners, even when the latter differ in architecture from the original agents. We conclude that compositionality does not arise from simple generalization pressure, but if an emergent language does chance upon it, it will be more likely to survive and thrive.