 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse or Dense? A Mechanistic Estimation of Computation Density in Transformer-based LLMs
Jan 30, 2026Transformer-based large language models (LLMs) are comprised of billions of parameters arranged in deep and wide computational graphs. Several studies on LLM efficiency optimization argue that it is possible to prune a significant portion of the parameters, while only marginally impacting performance. This suggests that the computation is not uniformly distributed across the parameters. We introduce here a technique to systematically quantify computation density in LLMs. In particular, we design a density estimator drawing on mechanistic interpretability. We experimentally test our estimator and find that: (1) contrary to what has been often assumed, LLM processing generally involves dense computation; (2) computation density is dynamic, in the sense that models shift between sparse and dense processing regimes depending on the input; (3) per-input density is significantly correlated across LLMs, suggesting that the same inputs trigger either low or high density. Investigating the factors influencing density, we observe that predicting rarer tokens requires higher density, and increasing context length often decreases the density. We believe that our computation density estimator will contribute to a better understanding of the processing at work in LLMs, challenging their symbolic interpretation.
Similarity of Processing Steps in Vision Model Representations
Jan 29, 2026Recent literature suggests that the bigger the model, the more likely it is to converge to similar, ``universal'' representations, despite different training objectives, datasets, or modalities. While this literature shows that there is an area where model representations are similar, we study here how vision models might get to those representations -- in particular, do they also converge to the same intermediate steps and operations? We therefore study the processes that lead to convergent representations in different models. First, we quantify distance between different model representations at different stages. We follow the evolution of distances between models throughout processing, identifying the processing steps which are most different between models. We find that while layers at similar positions in different models have the most similar representations, strong differences remain. Classifier models, unlike the others, will discard information about low-level image statistics in their final layers. CNN- and transformer-based models also behave differently, with transformer models applying smoother changes to representations from one layer to the next. These distinctions clarify the level and nature of convergence between model representations, and enables a more qualitative account of the underlying processes in image models.
Differential syntactic and semantic encoding in LLMs
Jan 08, 2026We study how syntactic and semantic information is encoded in inner layer representations of Large Language Models (LLMs), focusing on the very large DeepSeek-V3. We find that, by averaging hidden-representation vectors of sentences sharing syntactic structure or meaning, we obtain vectors that capture a significant proportion of the syntactic and semantic information contained in the representations. In particular, subtracting these syntactic and semantic ``centroids'' from sentence vectors strongly affects their similarity with syntactically and semantically matched sentences, respectively, suggesting that syntax and semantics are, at least partially, linearly encoded. We also find that the cross-layer encoding profiles of syntax and semantics are different, and that the two signals can to some extent be decoupled, suggesting differential encoding of these two types of linguistic information in LLM representations.
Tracing the complexity profiles of different linguistic phenomena through the intrinsic dimension of LLM representations
Jan 07, 2026We explore the intrinsic dimension (ID) of LLM representations as a marker of linguistic complexity, asking if different ID profiles across LLM layers differentially characterize formal and functional complexity. We find the formal contrast between sentences with multiple coordinated or subordinated clauses to be reflected in ID differences whose onset aligns with a phase of more abstract linguistic processing independently identified in earlier work. The functional contrasts between sentences characterized by right branching vs. center embedding or unambiguous vs. ambiguous relative clause attachment are also picked up by ID, but in a less marked way, and they do not correlate with the same processing phase. Further experiments using representational similarity and layer ablation confirm the same trends. We conclude that ID is a useful marker of linguistic complexity in LLMs, that it allows to differentiate between different types of complexity, and that it points to similar stages of linguistic processing across disparate LLMs.
An approach to identify the most semantically informative deep representations of text and images
May 21, 2025Deep neural networks are known to develop similar representations for semantically related data, even when they belong to different domains, such as an image and its description, or the same text in different languages. We present a method for quantitatively investigating this phenomenon by measuring the relative information content of the representations of semantically related data and probing how it is encoded into multiple tokens of large language models (LLMs) and vision transformers. Looking first at how LLMs process pairs of translated sentences, we identify inner ``semantic'' layers containing the most language-transferable information. We find moreover that, on these layers, a larger LLM (DeepSeek-V3) extracts significantly more general information than a smaller one (Llama3.1-8B). Semantic information is spread across many tokens and it is characterized by long-distance correlations between tokens and by a causal left-to-right (i.e., past-future) asymmetry. We also identify layers encoding semantic information within visual transformers. We show that caption representations in the semantic layers of LLMs predict visual representations of the corresponding images. We observe significant and model-dependent information asymmetries between image and text representations.
Outlier dimensions favor frequent tokens in language model
Mar 27, 2025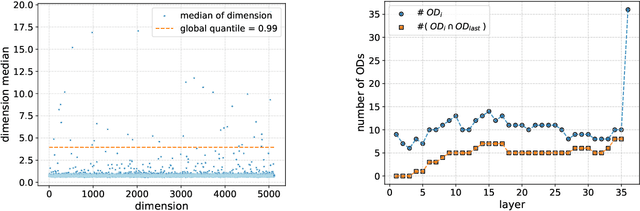



We study last-layer outlier dimensions, i.e.dimensions that display extreme activations for the majority of inputs. We show that outlier dimensions arise in many different modern language models, and trace their function back to the heuristic of constantly predicting frequent words. We further show how a model can block this heuristic when it is not contextually appropriate, by assigning a counterbalancing weight mass to the remaining dimensions, and we investigate which model parameters boost outlier dimensions and when they arise during training. We conclude that outlier dimensions are a specialized mechanism discovered by many distinct models to implement a useful token prediction heuristic.
Evil twins are not that evil: Qualitative insights into machine-generated prompts
Dec 11, 2024It has been widely observed that language models (LMs) respond in predictable ways to algorithmically generated prompts that are seemingly unintelligible. This is both a sign that we lack a full understanding of how LMs work, and a practical challenge, because opaqueness can be exploited for harmful uses of LMs, such as jailbreaking. We present the first thorough analysis of opaque machine-generated prompts, or autoprompts, pertaining to 3 LMs of different sizes and families. We find that machine-generated prompts are characterized by a last token that is often intelligible and strongly affects the generation. A small but consistent proportion of the previous tokens are fillers that probably appear in the prompt as a by-product of the fact that the optimization process fixes the number of tokens. The remaining tokens tend to have at least a loose semantic relation with the generation, although they do not engage in well-formed syntactic relations with it. We find moreover that some of the ablations we applied to machine-generated prompts can also be applied to natural language sequences, leading to similar behavior, suggesting that autoprompts are a direct consequence of the way in which LMs process linguistic inputs in general.
Emergence of a High-Dimensional Abstraction Phase in Language Transformers
May 24, 2024



A language model (LM) is a mapping from a linguistic context to an output token. However, much remains to be known about this mapping, including how its geometric properties relate to its function. We take a high-level geometric approach to its analysis, observing, across five pre-trained transformer-based LMs and three input datasets, a distinct phase characterized by high intrinsic dimensionality. During this phase, representations (1) correspond to the first full linguistic abstraction of the input; (2) are the first to viably transfer to downstream tasks; (3) predict each other across different LMs. Moreover, we find that an earlier onset of the phase strongly predicts better language modelling performance. In short, our results suggest that a central high-dimensionality phase underlies core linguistic processing in many common LM architectures.
Linearly Controlled Language Generation with Performative Guarantees
May 24, 2024The increasing prevalence of Large Language Models (LMs) in critical applications highlights the need for controlled language generation strategies that are not only computationally efficient but that also enjoy performance guarantees. To achieve this, we use a common model of concept semantics as linearly represented in an LM's latent space. In particular, we take the view that natural language generation traces a trajectory in this continuous semantic space, realized by the language model's hidden activations. This view permits a control-theoretic treatment of text generation in latent space, in which we propose a lightweight, gradient-free intervention that dynamically steers trajectories away from regions corresponding to undesired meanings. Crucially, we show that this intervention, which we compute in closed form, is guaranteed (in probability) to steer the output into the allowed region. Finally, we demonstrate on a toxicity avoidance objective that the intervention steers language away from undesired content while maintaining text quality.
MemoryPrompt: A Light Wrapper to Improve Context Tracking in Pre-trained Language Models
Feb 23, 2024Transformer-based language models (LMs) track contextual information through large, hard-coded input windows. We introduce MemoryPrompt, a leaner approach in which the LM is complemented by a small auxiliary recurrent network that passes information to the LM by prefixing its regular input with a sequence of vectors, akin to soft prompts, without requiring LM finetuning. Tested on a task designed to probe a LM's ability to keep track of multiple fact updates, a MemoryPrompt-augmented LM outperforms much larger LMs that have access to the full input history. We also test MemoryPrompt on a long-distance dialogue dataset, where its performance is comparable to that of a model conditioned on the entire conversation history. In both experiments we also observe that, unlike full-finetuning approaches, MemoryPrompt does not suffer from catastrophic forgetting when adapted to new tasks, thus not disrupting the generalist capabilities of the underlying LM.